-
postgresql字符串处理的函数
1. SPLIT_PART
SPLIT_PART() 函数通过指定分隔符分割字符串,并返回第N个子串。语法:- SPLIT_PART(string, delimiter, position)
- string : 待分割的字符串
- delimiter:指定分割字符串
- position:返回第几个字串,从1开始,该参数必须是正数。如果参数值大于分割后字符串的数量,函数返回空串。
示例:
SELECT SPLIT_PART('A,B,C', ',', 2); -- 返回B
2.STRING_TO_ARRAY
该函数用于分割字符串至数组元素,语法:string_to_array(string, delimiter [, null string])
string : 待分割的字符串
delimiter:指定分割字符串
null string : 设定空串的字符串
示例:- SELECT string_to_array('xx~^~yy~^~zz', '~^~'); -- {xx,yy,zz}
- SELECT string_to_array('xx~^~yy~^~zz', '~^~', 'yy'); -- {xx,NULL,zz}
3. regexp_split_to_array|regexp_split_to_table
使用正则表达式分割字符串,用来将字符串转换成格式化数据,一个是转换成数组,一个是转换成结果集表,语法:- regexp_split_to_array ( string, pattern [, flags text ] ) → text[]
- string : 待分割的字符串
- pattern:正则表达式或指定分割字符串
示例1:正则表达式SELECT regexp_split_to_array('foo bar baz', '\s+');
示例2:指定分割字符串SELECT * FROM student t WHERE regexp_split_to_array(t.subject,',') @> array['英语','中国古典文学']
SELECT * FROM student t WHERE regexp_split_to_array(t.subject,',') @> regexp_split_to_array('英语','中国古典文学',',')
- regexp_split_to_table ( string, pattern [, flags text ] )
- string : 待分割的字符串
- pattern:正则表达式或指定分割字符串

Tips:查询具体排序的第几个的用regexp_split_to_array函数,查询是否包含的条件,则使用ARRAY_AGG与 regexp_split_to_table两个函数4.regexp_split_to_array
和上面一样,只是返回数据类型,语法:- regexp_split_to_array( string, pattern )
- string : 待分割的字符串
- pattern:正则表达式或指定分割字符串
示例1(单个切断):
select regexp_split_to_array('the,quick,brown;fox;jumps', '[,;]') -- 返回 {the,quick,brown,fox,jumps}示例2(表字段和传入字符串比较):
select regexp_split_to_array(subjects,',') @> regexp_split_to_array('英语,中国古典文学',',')@> 包含的关系,不指定顺序
subjects 包含 数据:'英语','中国古典文学'
= 相等的关系
subjects 等于 数据:'英语','中国古典文学'
!= 不等的关系
subjects 不等于 数据:'英语','中国古典文学'
&& 存在
subjects 包含 数据:'英语','中国古典文学' 其中的一条
5. regexp_matches
匹配一个POSIX正则表达式针对字符串并返回匹配的子字符串。语法:REGEXP_MATCHES(string, pattern [, flags])
string : 待分割的字符串
pattern:要提取子字符串的字符串那匹配正则表达式
flag:一个或多个控制函数行为的字符
返回结果:即使结果数组仅包含单个元素,函数也会返回一组文本
示例1(提取指定符号后的内容):SELECT REGEXP_MATCHES('Learning #Geeksforgeeks #geekPower', '#([A-Za-z0-9_]+)', 'g');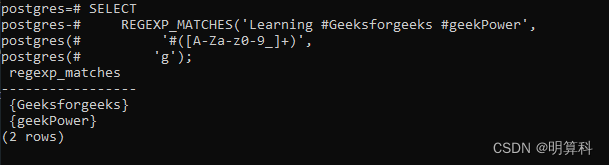
示例2(可以通过正则表达式匹配的所有模式都一样):
SELECT REGEXP_MATCHES('ABC', '^(A)(..)$', 'g');
-
相关阅读:
如何在 Google Analytics 中设置增强型电子商务
js中ECharts基础
JAVA计算机毕业设计在线玩具租赁系统Mybatis+源码+数据库+lw文档+系统+调试部署
自动化监控系统Prometheus&Grafana
跟我学c++高级篇——模板的ADL
c++ 获取当前时间(精确至秒、毫秒和微妙)
通达OA 2016网络智能办公系统 handle.php SQL注入漏洞
极客日报:腾讯推出员工退休待遇方案;百度高管称自动驾驶并非100%无事故;美国悬赏1500万美元通缉黑客
便捷查询中通快递,详细物流信息轻松获取
Laravel env()为null的问题
- 原文地址:https://blog.csdn.net/LG_15011399296/article/details/133904592