-
【算法训练-回溯算法 一】【经典模版】全排列
废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是【回溯算法】,使用【数组】这个基本的数据结构来实现,这个高频题的站点是:CodeTop,筛选条件为:目标公司+最近一年+出现频率排序,由高到低的去牛客TOP101去找,只有两个地方都出现过才做这道题(CodeTop本身汇聚了LeetCode的来源),确保刷的题都是高频要面试考的题。

明确目标题后,附上题目链接,后期可以依据解题思路反复快速练习,题目按照题干的基本数据结构分类,且每个分类的第一篇必定是对基础数据结构的介绍。
全排列【MID】
一道一直想要解决的高频题,理解回溯算法,解决回溯算法经典题目:全排列,排列树如下

题干

解题思路
原题解思路地址,我们在高中的时候就做过排列组合的数学题,我们也知道 n 个不重复的数,全排列共有 n! 个。那么我们当时是怎么穷举全排列的呢?比方说给三个数 [1,2,3],一般是这样:先固定第一位为 1,然后第二位可以是 2,那么第三位只能是 3;然后可以把第二位变成 3,第三位就只能是 2 了;然后就只能变化第一位,变成 2,然后再穷举后两位

只要从根遍历这棵树,记录路径上的数字,其实就是所有的全排列。我们不妨把这棵树称为回溯算法的「决策树」。为啥说这是决策树呢,因为你在每个节点上其实都在做决策。比如说你站在下图的红色节点上

你现在就在做决策,可以选择 1 那条树枝,也可以选择 3 那条树枝。为啥只能在 1 和 3 之中选择呢?因为 2 这个树枝在你身后,这个选择你之前做过了,而全排列是不允许重复使用数字的。所以[2] 就是「路径」,记录你已经做过的选择;[1,3] 就是「选择列表」,表示你当前可以做出的选择;「结束条件」就是遍历到树的底层叶子节点,这里也就是选择列表为空的时候

我们定义的 backtrack 函数其实就像一个指针,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层叶子节点,其「路径」就是一个全排列,「路径」和「选择」是每个节点的属性,函数在树上游走要正确处理节点的属性,那么就要在这两个特殊时间点搞点动作

所以其核心逻辑就是for 选择 in 选择列表: # 做选择 将该选择从选择列表移除 路径.add(选择) backtrack(路径, 选择列表) # 撤销选择 路径.remove(选择) 将该选择再加入选择列表- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
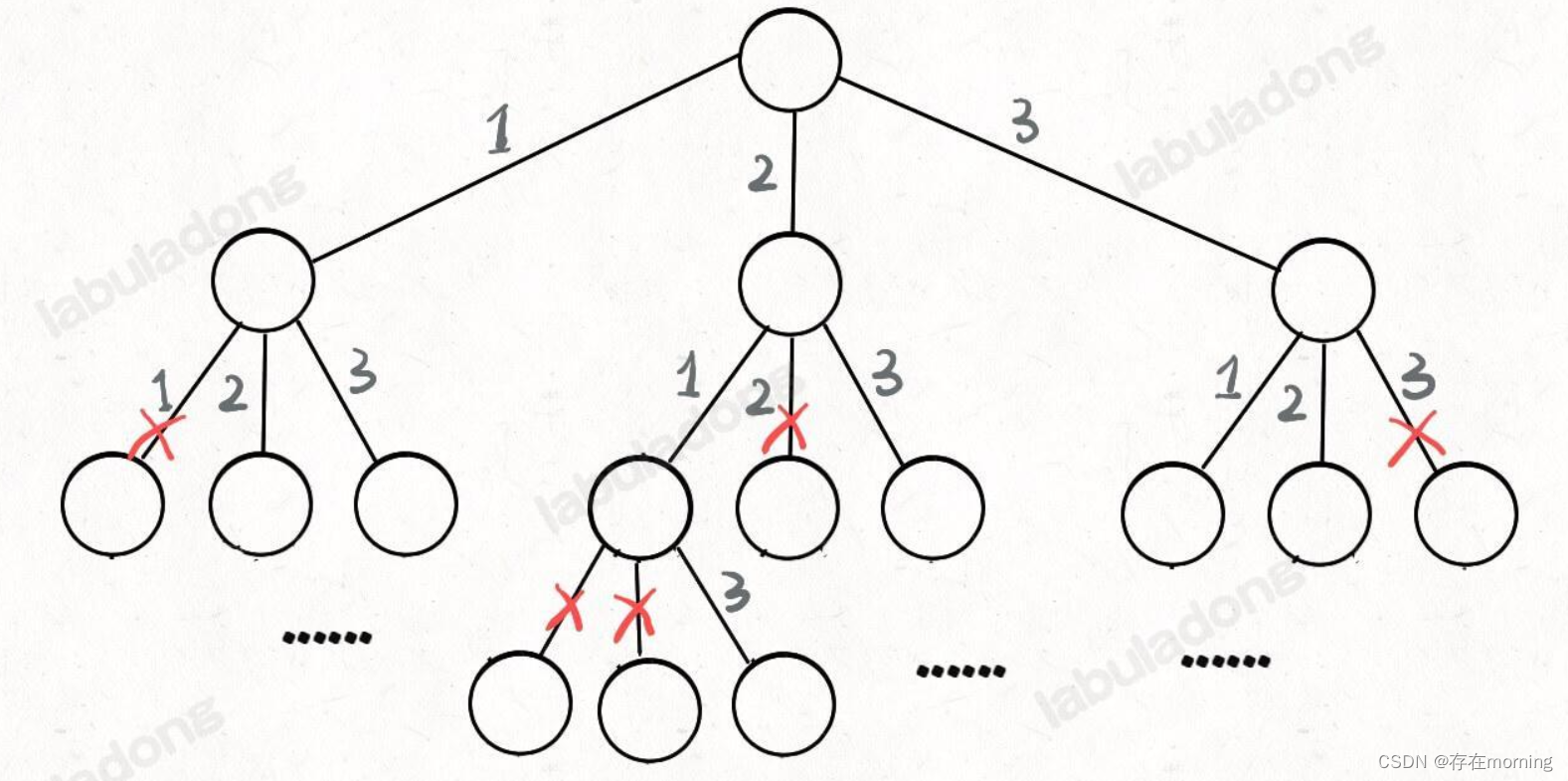
符合回溯框架,而且时间复杂度都不可能低于 O(N!),因为穷举整棵决策树是无法避免的,你最后肯定要穷举出 N! 种全排列结果。这也是回溯算法的一个特点,不像动态规划存在重叠子问题可以优化,回溯算法就是纯暴力穷举,复杂度一般都很高代码实现
给出代码实现基本档案
基本数据结构:数组
辅助数据结构:无
算法:回溯算法
技巧:无import java.util.*; public class Solution { // 定义结果集参数 private ArrayList<ArrayList<Integer>> result = new ArrayList<ArrayList<Integer>>(); // 定义路径 ArrayList<Integer> path = new ArrayList<Integer>(); /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param num int整型一维数组 * @return int整型ArrayList- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
复杂度分析
上述代码是一个用于生成整数数组的全排列的回溯算法,下面是对其时间复杂度和空间复杂度的分析:
时间复杂度:
-
回溯算法的时间复杂度通常取决于递归的深度和每层递归的操作数量。在这个算法中,每层递归都会尝试
num数组中的每个元素,直到达到终止条件。 -
在每层递归中,有一个循环来遍历
num数组的所有元素。由于每个元素都被考虑一次,因此总共有n个元素,所以在每层递归中有O(n)的操作。 -
递归的深度取决于
num数组的大小,也就是n。在最坏的情况下,递归会深入到n层,因此总时间复杂度是O(n * n!)。
空间复杂度:
-
空间复杂度主要取决于递归调用的深度,以及用于存储中间结果的数据结构。
-
递归的深度是
n,因此在调用堆栈中会有最多n层递归帧。每个递归帧包括used数组和path数组,它们的空间复杂度都是O(n)。 -
由于存在
n层递归帧,因此总的空间复杂度为O(n^2)。
综上所述,上述代码的时间复杂度是
O(n * n!),其中n是输入数组num的大小,空间复杂度是O(n^2)。由于全排列问题的本质,这个时间复杂度是可以接受的,因为全排列的数量本身是n!,因此生成所有排列的算法必然具有阶乘级的时间复杂度。全排列II
增加难度,在有重复元素的选择列表里选择所有的组合
题干

解题思路
假设输入为
nums = [1,2,2'],标准的全排列算法会得出如下答案:[ [1,2,2'],[1,2',2], [2,1,2'],[2,2',1], [2',1,2],[2',2,1] ]- 1
- 2
- 3
- 4
- 5
- 6
显然,这个结果存在重复,比如
[1,2,2']和[1,2',2]应该只被算作同一个排列,但被算作了两个不同的排列。所以现在的关键在于,如何设计剪枝逻辑,把这种重复去除掉?答案是,保证相同元素在排列中的相对位置保持不变。比如说nums = [1,2,2']这个例子,我保持排列中 2 一直在 2’ 前面。这样的话,你从上面 6 个排列中只能挑出 3 个排列符合这个条件:[ [1,2,2'],[2,1,2'],[2,2',1] ]- 1
这也就是正确答案。进一步,如果 nums =
[1,2,2',2''],我只要保证重复元素 2 的相对位置固定,比如说2 -> 2' -> 2'',也可以得到无重复的全排列结果标准全排列算法之所以出现重复,是因为把相同元素形成的排列序列视为不同的序列,但实际上它们应该是相同的;而如果固定相同元素形成的序列顺序,当然就避免了重复
// 新添加的剪枝逻辑,固定相同的元素在排列中的相对位置 if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) { // 如果前面的相邻相等元素没有用过,则跳过 continue; } // 选择 nums[i]- 1
- 2
- 3
- 4
- 5
- 6
- 7
当出现重复元素时,比如输入
nums = [1,2,2',2''],2’ 只有在 2 已经被使用的情况下才会被选择,同理,2’’ 只有在 2’ 已经被使用的情况下才会被选择,这就保证了相同元素在排列中的相对位置保证固定代码实现
给出代码实现基本档案
基本数据结构:数组
辅助数据结构:无
算法:回溯算法
技巧:无import java.util.*; public class Solution { // 定义结果集 private ArrayList<ArrayList<Integer>> result = new ArrayList<ArrayList<Integer>>(); // 定义路径集合以及使用标识集合 ArrayList<Integer> path = new ArrayList<Integer>(); /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param num int整型一维数组 * @return int整型ArrayList- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
复杂度分析
全排列II(Permutations II)是一个排列问题,与上述的全排列问题不同的是,这里的输入数组
num可能包含重复元素。解决这个问题的代码也使用回溯算法,但在处理重复元素时需要特殊考虑。以下是全排列II问题的时间复杂度和空间复杂度分析:时间复杂度:
-
与全排列问题类似,回溯算法的时间复杂度取决于递归的深度和每层递归的操作数量。
-
在每层递归中,需要遍历
num数组中的所有元素。由于可能有重复元素,需要确保相同的元素在同一层递归中只被考虑一次。因此,在每层递归中,可以采取一些方法来跳过重复元素,从而降低遍历的操作数量。 -
递归的深度仍然取决于
num数组的大小,即n。 -
在最坏的情况下,递归会深入到
n层,因此总的时间复杂度仍然是O(n * n!),但由于考虑重复元素,实际执行的操作数量可能比全排列问题少一些。
空间复杂度:
-
空间复杂度主要取决于递归调用的深度,以及用于存储中间结果的数据结构。
-
递归的深度是
n,因此在调用堆栈中会有最多n层递归帧。每个递归帧包括used数组和path数组,它们的空间复杂度都是O(n)。 -
由于存在
n层递归帧,因此总的空间复杂度为O(n^2)。
综上所述,全排列II的时间复杂度仍然是
O(n * n!),其中n是输入数组num的大小,空间复杂度是O(n^2)。同样,由于全排列问题的本质,这个时间复杂度在最坏情况下是可以接受的,尽管考虑了重复元素。然而,实际操作的数量可能比全排列问题少一些,因为会跳过相同的元素。拓展知识:回溯算法解题框架
抽象地说,解决一个回溯问题,实际上就是遍历一棵决策树的过程,树的每个叶子节点存放着一个合法答案。你把整棵树遍历一遍,把叶子节点上的答案都收集起来,就能得到所有的合法答案。站在回溯树的一个节点上,你只需要思考 3 个问题:
- 路径:也就是已经做出的选择。
- 选择列表:也就是你当前可以做的选择。
- 结束条件:也就是到达决策树底层,无法再做选择的条件。
回溯算法的框架:
result = [] def backtrack(路径, 选择列表): if 满足结束条件: result.add(路径) return for 选择 in 选择列表: 做选择 backtrack(路径, 选择列表) 撤销选择- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
其核心就是 for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」
-
相关阅读:
php中mcrypt_encrypt升级到openssl_encrypt
android.mk介绍
代码随想录算法训练营第五十六天|1143.最长公共子序列、1035.不相交的线、53. 最大子序和
数图可视化品类空间管理系统入编《零售门店数字化赋能专项报告(2024年)》
MySQL一条SQL语句的执行过程
About 11.20 This Week
Seata流程源码梳理下篇-TC
基于SSM的电子相册系统设计与实现
setTimeout和setInterval相互实现
NVIDIA 7th SkyHackathon(六)Tao 目标检测模型训练与评估
- 原文地址:https://blog.csdn.net/sinat_33087001/article/details/133894841
