-
使用PyTorch解决多分类问题:构建、训练和评估深度学习模型
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢迎在文章下方留下你的评论和反馈。我期待着与你分享知识、互相学习和建立一个积极的社区。谢谢你的光临,让我们一起踏上这个知识之旅!

🍋引言
当处理多分类问题时,PyTorch是一种非常有用的深度学习框架。在这篇博客中,我们将讨论如何使用PyTorch来解决多分类问题。我们将介绍多分类问题的基本概念,构建一个简单的多分类神经网络模型,并演示如何准备数据、训练模型和评估结果。
🍋什么是多分类问题?
多分类问题是一种机器学习任务,其中目标是将输入数据分为多个不同的类别或标签。与二分类问题不同,多分类问题涉及到三个或更多类别的分类任务。例如,图像分类问题可以将图像分为不同的类别,如猫、狗、鸟等。
🍋处理步骤
-
准备数据:
收集和准备数据集,确保每个样本都有相应的标签,以指明其所属类别。
划分数据集为训练集、验证集和测试集,以便进行模型训练、调优和性能评估。 -
数据预处理:
对数据进行预处理,例如归一化、标准化、缺失值处理或数据增强,以确保模型训练的稳定性和性能。 -
选择模型架构:
选择适当的深度学习模型架构,通常包括卷积神经网络(CNN)、循环神经网络(RNN)、Transformer等,具体取决于问题的性质。 -
定义损失函数:
为多分类问题选择适当的损失函数,通常是交叉熵损失(Cross-Entropy Loss)。 -
选择优化器:
选择合适的优化算法,如随机梯度下降(SGD)、Adam、RMSprop等,以训练模型并调整权重。 -
训练模型:
使用训练数据集来训练模型。在每个训练迭代中,通过前向传播和反向传播来更新模型参数,以减小损失函数的值。 -
评估模型:
使用验证集来评估模型性能。常见的性能指标包括准确性、精确度、召回率、F1分数等。 -
调优模型:
根据验证集的性能,对模型进行调优,可以尝试不同的超参数设置、模型架构变化或数据增强策略。 -
测试模型:
最终,在独立的测试数据集上评估模型的性能,以获得最终性能评估。 -
部署模型:
将训练好的模型部署到实际应用中,用于实时或批处理多分类任务。
🍋多分类问题
之前我们讨论的问题都是二分类居多,对于二分类问题,我们若求得p(0),南无p(1)=1-p(0),还是比较容易的,但是本节我们将引入多分类,那么我们所求得就转化为p(i)(i=1,2,3,4…),同时我们需要满足以上概率中每一个都大于0;且总和为1。
处理多分类问题,这里我们新引入了一个称为Softmax Layer

接下来我们一起讨论一下Softmax Layer层
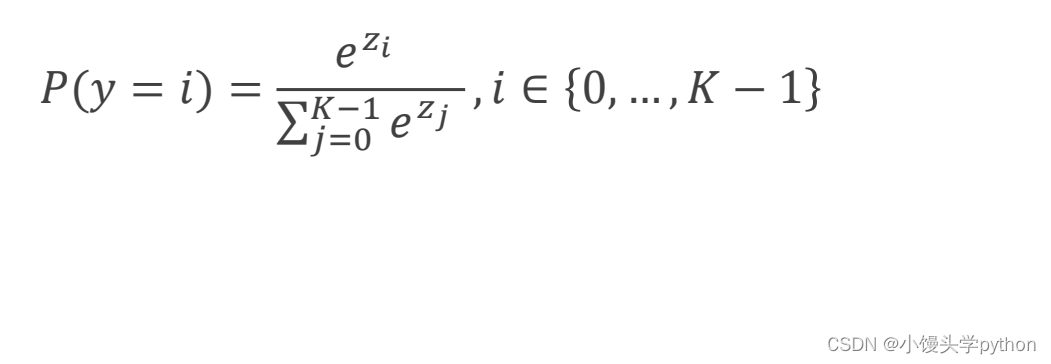
首先我们计算指数计算e的zi次幂,原因很简单e的指数函数恒大于0;分母就是e的z1次幂+e的z2次幂+e的z3次幂…求和,这样所有的概率和就为1了。
下图形象的展示了Softmax,Exponent这里指指数,和上面我们说的一样,先求指数,这样有了分子,再将所有指数求和,最后一一divide,得到了每一个概率。
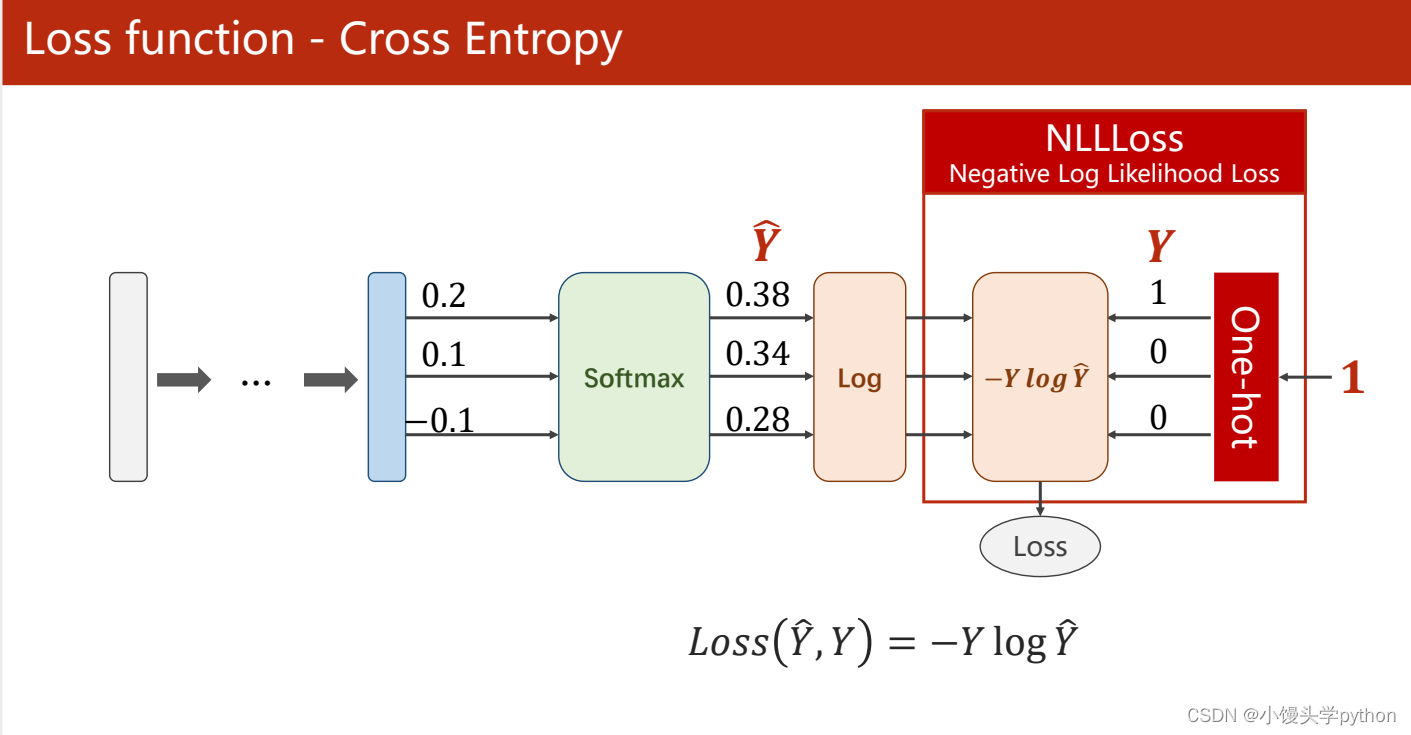
接下来我们一起来看看损失函数
如果使用numpy进行实现,根据刘二大人的代码,可以进行如下的实现import numpy as np y = np.array([1,0,0]) z = np.array([0.2,0.1,-0.1]) y_pred = np.exp(z)/np.exp(z).sum() loss = (-y * np.log(y_pred)).sum() print(loss)- 1
- 2
- 3
- 4
- 5
- 6
运行结果如下

注意:神经网络的最后一层不需要激活
在pytorch中
import torch y = torch.LongTensor([0]) # 长整型 z = torch.Tensor([[0.2, 0.1, -0.1]]) criterion = torch.nn.CrossEntropyLoss() loss = criterion(z, y) print(loss)- 1
- 2
- 3
- 4
- 5
- 6
运行结果如下

下面根据一个例子进行演示criterion = torch.nn.CrossEntropyLoss() Y = torch.LongTensor([2,0,1]) Y_pred1 = torch.Tensor([[0.1, 0.2, 0.9], [1.1, 0.1, 0.2], [0.2, 2.1, 0.1]]) Y_pred2 = torch.Tensor([[0.8, 0.2, 0.3], [0.2, 0.3, 0.5], [0.2, 0.2, 0.5]]) l1 = criterion(Y_pred1, Y) l2 = criterion(Y_pred2, Y) print("Batch Loss1 = ", l1.data, "\nBatch Loss2=", l2.data)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
运行结果如下

根据上面的代码可以看出第一个损失比第二个损失要小。原因很简单,想对于Y_pred1每一个预测的分类与Y是一致的,而Y_pred2则相差了一下,所以损失自然就大了些
🍋MNIST dataset的实现
首先第一步还是导包
import torch from torchvision import transforms from torchvision import datasets from torch.utils.data import DataLoader import torch.nn.functional as F import torch.optim as optim- 1
- 2
- 3
- 4
- 5
- 6
之后是数据的准备
batch_size = 64 # transform可以将其转化为0-1,形状的转换从28×28转换为,1×28×28 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307, ), (0.3081, )) # 均值mean和标准差std ]) train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform) train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform) test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

接下来我们构建网络class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.l1 = torch.nn.Linear(784, 512) self.l2 = torch.nn.Linear(512, 256) self.l3 = torch.nn.Linear(256, 128) self.l4 = torch.nn.Linear(128, 64) self.l5 = torch.nn.Linear(64, 10) def forward(self, x): x = x.view(-1, 784) x = F.relu(self.l1(x)) x = F.relu(self.l2(x)) x = F.relu(self.l3(x)) x = F.relu(self.l4(x)) return self.l5(x) # 注意最后一层不做激活 model = Net()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
之后定义损失和优化器
criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)- 1
- 2
接下来就进行训练了
def train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data optimizer.zero_grad() # forward + backward + update outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300)) running_loss = 0.0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
def test(): correct = 0 total = 0 with torch.no_grad(): # 这里可以防止内嵌代码不会执行梯度 for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy on test set: %d %%' % (100 * correct / total))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
最后调用执行
if __name__ == '__main__': for epoch in range(10): train(epoch) test()- 1
- 2
- 3
- 4
🍋NLLLoss 和 CrossEntropyLoss
NLLLoss 和 CrossEntropyLoss(也称为交叉熵损失)是深度学习中常用的两种损失函数,用于测量模型的输出与真实标签之间的差距,通常用于分类任务。它们有一些相似之处,但也有一些不同之处。
相同点:
用途:两者都用于分类任务,评估模型的输出和真实标签之间的差异,以便进行模型的训练和优化。 数学基础:NLLLoss 和 CrossEntropyLoss 本质上都是交叉熵损失的不同变种,它们都以信息论的概念为基础,衡量两个概率分布之间的相似度。 输入格式:它们通常期望模型的输出是一个概率分布,表示各个类别的预测概率,以及真实的标签。- 1
- 2
- 3
不同点:
输入格式:NLLLoss 通常期望输入是对数概率(log probabilities),而 CrossEntropyLoss 通常期望输入是未经对数化的概率。在实际应用中,CrossEntropyLoss 通常与softmax操作结合使用,将原始模型输出转化为概率分布,而NLLLoss可以直接使用对数概率。 对数化:NLLLoss 要求将模型输出的概率经过对数化(取对数)以获得对数概率,然后与真实标签的离散概率分布进行比较。CrossEntropyLoss 通常在 softmax 操作之后直接使用未对数化的概率值与真实标签比较。 输出维度:NLLLoss 更通用,可以用于多种情况,包括多类别分类和序列生成等任务,因此需要更多的灵活性。CrossEntropyLoss 通常用于多类别分类任务。- 1
- 2
- 3
总之,NLLLoss 和 CrossEntropyLoss 都用于分类任务,但它们在输入格式和使用上存在一些差异。通常,选择哪个损失函数取决于你的模型输出的格式以及任务的性质。如果你的模型输出已经是对数概率形式,通常使用NLLLoss,否则通常使用CrossEntropyLoss。

挑战与创造都是很痛苦的,但是很充实。
-
-
相关阅读:
MYSQL的安装及环境配置
国庆加速度!新增功能点锁定功能,敏捷开发新增估算功能,助力项目快速突破!
Linux学习笔记——网络管理
Python编程 列表的常用方法
PostgreSQL 给表添加自增字段脚本
在gitlab中指定自定义 CI/CD 配置文件
Linux环境搭配
Spring MVC的转发与重定向
B - Leonel and the powers of two
防止被00后整顿?一公司招聘要求员工不能起诉公司
- 原文地址:https://blog.csdn.net/null18/article/details/133859199
