-
计算机网络 | 传输层
计算机网络 | 传输层
参考视频:王道计算机考研 计算机网络
参考书:《2022年计算机网络考研复习指导》
计算机网络 | 传输层

功能概述
传输层是主机才有的层次。

复用:发送方的不同应用进程都可以使用同一个传输层协议传送数据。
分用:接收方的传输层在去掉报文的首部后能把数据正确交付到目的应用进程。
注:网络层也有复用和分用功能。但网络层的复用指发送方不同协议的数据都可以封装成IP数据报发送出去,分用指接收方的网络层在去掉报文的首部后能把数据正确交付给相应的协议。
端口:

常用的熟知端口号:
应用程序 熟知端口号 FTP 21 TELNET 23 SMTP 25 DNS 53 TFTP 69 HTTP 80 SNMP 161 套接字:一个通信端点,在网络中采用发送方和接收方的套接字来识别端点。
套接字 Socket = (IP地址:端口号),它唯一地标识网络中的一台主机和其上的一个应用(进程)。
无连接服务和面向连接服务:

UDP协议
概述:
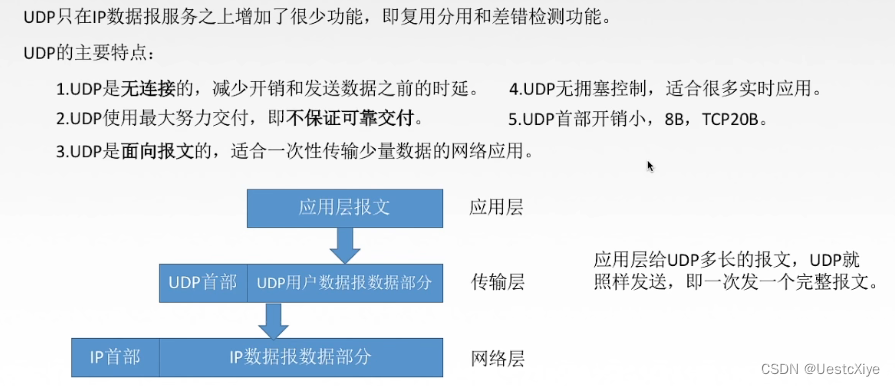
UDP不保证可靠交付,所有维护可靠性的工作在应用层完成。
UDP是面向报文的。报文不可分割,是UDP数据报处理的最小单位。报文过大或过小都会降低网络层的效率。
UDP首部占8B,首部格式:

当传输层从网络层收到UDP数据报时,就根据首部的目的端口把UDP数据报通过相应端口上交给应用进程。
如果接收方UDP发现接收报文的目的端口号错误,丢弃该报文,并发送ICMP“端口不可达”差错报文给发送方。
UDP的校验位构成:

这里的伪首部只是用来计算检验和的,计算完了就丢弃。
UDP校验方式:

在发送端的时候:
- 校验和字段全设为0,添加伪首部。
- 将每一行(4字节)拆成两部分,左右平均2字节大小,将这两字节数据写成二进制,那么2字节一共就需要2*8=16位。同时如果数据字段不整齐,则用0补齐,这样就可以写出几十行二进制数,如上图中所示。
- 计算着几十行二进制数按二进制反码运算求和,二进制反码运算可以参考二进制反码求和运算,得到的最后结构再反码,之后将反码之后的放入原来的检验和字段。
在接收端的时候:
- 与发送端的时候不同的是,此时检验和字段不是0了。
- 按照发送端的步骤再将所有数据写成二进制进行二进制反码运算求和。
- 如果最后得到结果全1就是没问题,否则丢弃。
注意:
- 校验时,若UDP数据报的长度不是偶数个字节,则需填入一个全0字节,但此字节和伪首部一样,是不发送的。
- 若UDP校验和校验出UDP数据报是错误的,那么可以丢弃,也可以附上错误报告交付给上层。
- 通过伪首部,不仅可以检查源端口号、目的端口号和UDP数据报的数据部分。还可以检查IP数据报的源IP地址和目的地址。
TCP协议
TCP协议的特点
TCP协议的主要特点:

- UDP报文的长度由发送应用进程决定。
- TCP报文的长度根据接收方给出的窗口值和当前网络拥塞程度来决定。如果应用进程传送到TCP缓存的数据块太长,TCP会分段传送;如果太短,TCP也可以等到积累足够多的字节后再组成报文段发送。
TCP报文段
TCP传送的数据单元称为报文段。
TCP报文段 = 首部 + 数据。
TCP报文段的首部最短为20B,最长为60B。前20B是固定的,后面有4N字节是根据需要而增加的选项,通常长度为4B的整数倍。
源端口和目的端口:各占2B。端口是传输层和应用层的服务接口。

保留:占6位,保留为今后使用,目前全为0。

- 紧急位URG:让数据插队,URG=1的就会在缓存中被提前到第一个传输。
- 确认位ACK:仅当ACK=1时确认号有效。
- 推送位PSH:将PSH=1的报文段尽快交付给接收应用进程,而不是等到缓存满了再向上交付。
- 复位RST:RST=1时,表明TCP连接中出现严重差错(比如:主机崩溃),必须释放连接,再重新建立连接。
- 同步为SYN:SYN=1表明这是一个连接请求或连接接受报文。SYN=1、ACK=0表明是连接请求报文,对方若同意建立连接,则在响应报文中使用SYN=1、ACK=1。
- 终止位FIN:当FIN=1时,表明此报文段的发送方的数据发送完毕,并要求释放连接。

填充:为了使整个首部长度是4B的整数倍。
注:紧急数据在报文段数据的最前面。
TCP连接管理
TCP连接的三个阶段:
- 建立连接
- 数据传送
- 释放连接
TCP连接把连接作为最基本的抽象,TCP连接的端口为套接字或插口。
TCP连接的建立
TCP连接的建立采用C/S方式。

第一段的意思是:
SYN=1:(A)要建立连接了!
seq=x(随机):因为还没有数据,所以写什么都无所谓第二段的意思是:
SYN=1:我(B)同意你(A)建立连接!
ACK=1:连接建立了,之后的ACK必须都置为1
seq=y(随机):因为还没有数据,所以写什么都无所谓
ack=x+1:之前发送方(A)说发送的是第x位数据(虽然发送方是瞎说的),所以我(B)要的是x+1位数据第三段的意思是:
SYN=0:SYN只有在建立连接时才为1,其他时候均设为0
ACK=1:连接建立了,之后的ACK必须都置为1
seq=x+1:我(A)发送的报文段的第一个字节就是x+1
ack=y+1:之前接收方(B)说发送的是第y位数据(虽然接收方是瞎说的),所以我(A)要的是y+1位数据注意,TCP提供的是全双工通信,这里的两台主机都同时是发送方和接收方。
服务器的资源是在完成第二次握手时分配的,客户端的资源是在完成第三次握手时分配的。这使得服务器易于受到SYN洪泛攻击。
SYN洪泛攻击:

解决方法:设置SYN cookie。
TCP连接的释放

第一段的意思是:
FIN=1:(A)要释放连接了!
seq=u:发了好多数据,这里只是用u指代一下,这里u是有确定值的第二段的意思是:
ACK=1:连接建立了,之后的ACK必须都置为1
seq=v:发了好多数据,这里只是用v指代一下,这里v是有确定值的
ack=u+1:之前发送方(A)说发送的是第u位数据,所以我(B)要的是u+1位数据(尽管此时A已经决定释放连接了)第三段的意思是:
FIN=1:(B)要释放连接了!
ACK=1:连接建立了,之后的ACK必须都置为1
seq=w:发了好多数据,这里只是用w指代一下,这里w是有确定值的
ack=u+1:之前发送方(A)说发送的是第u位数据,所以我(B)要的是u+1位数据(因为A直接不发数据了,所以第二段第三段的ack都是u+1)第四段的意思是:
ACK=1:连接建立了,之后的ACK必须都置为1
seq=u+1:之前发的数据时第u位数据,B也要第u+1位数据,所以我发第u+1位数据
ack=w+1:之前发送方(B)说发送的是第w位数据,所以我(A)要的是w+1位数据为什么需要等待计时2MSL?
因为这样可以保证B可以收到A的终止报文段进而进入关闭状态。
比如说如果A的第四段报文丢失,那么等待一个MSL之后B就会重传第三段报文,花费小于1MSL之后A就会再收到第三段报文,之后就可以再次向B发送第四段报文提示B关闭连接。TCP可靠传输

序号
TCP首部的序号字段保证数据能有序提交给应用层。
TCP把数据视为一个无结构、有序的字节流,每个字节都编上一个序号。
序号字段的值:本报文段所发送的数据的第一个字节的序号。
确认
发送方每一次发送数据之后都需要接收方进行确认。
TCP首部的确认号字段是期望收到对方的下一个报文段的数据的第一个字节的序号。
发送方缓存区会继续存储那些已发送但未收到确认的报文段,以便重传。
TCP默认采用累积确认的机制,即TCP只确认数据流中至第一个丢失字节为止的字节。
示例:

重传
有两种事件会导致TCP对报文段进行重传:超时和冗余ACK。
超时重传:TCP每发送一个报文段,就对这个报文段设置一次计时器,计时器到期但还未收到确认时,就要重传该报文段。
TCP采用自适应算法,它记录每个报文段的发出时间和收到确认时间,两者之差就是报文段的往返时间(Round-Trip Time,RTT)。
TCP保留了一个加权平均往返时间RTTs,它会随新测量RTT值的变化而变化。
显然,超时计时器设置的超时重传时间(Retransmission Time-Out,RTO)应该略大于加权平均往返时间RTTs,但也不能大太多。
冗余ACK:再次确认某个报文段的ACK,而发送方先前已经收到过该报文段的确认。

TCP流量控制
接收方可以动态地发送信息告诉发送方发送窗口的大小。
接收方接受不过来了就让发送方发送窗口小点,这样发送方发送的速率就慢下来了,接收方就有时间处理它的数据了。
接受方处理完了也可以发送请求让发送方发送窗口大点,这样发送方发送的速率就快起来了,接收方就可以处理更多数据而不是空闲等着收数据了。

示例:

有一个情况就是,如果最后B不允许A再发送数据了,B在处理完数据之后想要恢复窗口大小时发送的有rwnd大小的数据报丢了怎么办?此时A有B的指令在前,发送窗口为0无法发送数据,B也在等待A回复,造成了类似死锁的现象。
解决方法:使用计时器。发送方主动向接收方询问接收窗口大小rwnd,这和超时重传无关。
传输层和数据链路层的流量控制的区别是:
- 传输层定义端到端的流量控制,数据链路层定义点到点的流量控制。
- 数据链路层的滑动窗口协议的滑动窗口大小不能动态变化,而传输层的可以。
TCP拥塞控制

拥塞控制是全局性的过程,而流量控制是端到端的问题。
TCP拥塞控制的四种算法:
- 慢开始
- 拥塞避免
- 快重传
- 快恢复
TCP协议要求发送方维护两个窗口:
- 接收窗口rwnd
- 拥塞窗口cwnd

慢开始和拥塞避免
每次发送方接收到接收方传回的确认报文后,就根据其中的cwnd值立即调整拥塞窗口的大小,再开始新的一个传输轮次。
过程:
- 开始时以指数形式增长,ssthresh的意思是慢开始门限,代表从这个地方注入的报文段就比较多了,需要开始慢速增加了。
- 之后一段都是线性增长,每次增加1,直至达到网络拥塞状态。
- 发现网络拥塞后,瞬间将cwnd设置为1,同时调整原来的ssthresh的值到之前达到网络拥塞状态的1/2(24降到12)。
- 重复以上步骤,注意此时ssthresh变了之后,线性增长的转折点也变了。

快重传和快恢复
快重传:当发送方连续收到三个重复的ACK报文时,直接重传接收方未收到的报文段,而不必等待那个报文段设置的重传计时器超时。
注:快重传并非取消重传计时器。
快恢复:当发送方连续收到三个冗余ACK(重复确认)时,执行“乘法减小”算法,把慢开始门限ssthresh设置为此时发送方拥塞窗口大小cwnd的一半,然后执行拥塞避免算法,使拥塞窗口缓慢地线性增大。

第5章总结

-
相关阅读:
java StringTokenizer类
mysql高级刷题-01-求中位数
自定义类加载器
编译器优化丨Cache优化
Windows卸载Nessus与安装Nessus
【ElasticSearch系列-05】SpringBoot整合elasticSearch
【Rust 笔记】15-字符串与文本(上)
vue 页面加水印
【C#实战】控制台游戏 勇士斗恶龙(3)——营救公主以及结束界面
Linux文件编程API的使用
- 原文地址:https://blog.csdn.net/ProgramNovice/article/details/133854642