-
KMP 算法 + 详细笔记
先快速了解一些名词和概念(来自王道的PPT):
- 串:即字符串(String)是由零个或多个字符组成的有限序列
- 子串:串中任意个连续的字符组成的子序列
- 主串:包含子串的串
- 字符在主串中的位置:字符在串中的序号
- 子串在主串中的位置:子串的第一个字符在主串中的位置
- 串的前缀:包含第一个字符,且不包含最后一个字符的子串
- 串的后缀:包含最后一个字符,且不包含第一个字符的子串
给两个字符串,T="AAAAAAAAB",P="AAAAB";

可以暴力匹配,但是太费时和效率不太好。于是KMP问世,我们一起来探究一下吧!!!
(一)最大公共前后缀
例如对于字符串 abacaba,其前缀有 a, ab, aba, abac, abacab,后缀有bacaba, acaba, caba, aba, ba, a。最长公共前后缀就是 aba(举的例子来自这个博主:最长公共前后缀-CSDN博客)

- D[i] = p[0]~p[i] 区间(前i+1个字母)所拥有的最大公共前后缀的长度(类似动态规划的定义,以便于从具体的例子转换成通用的代码)

- D[0]=0,表示p[0]~p[0]区间(前1个字母)->也就是 A 所拥有的最大公共前后缀长度为0.
- D[1]=1,表示p[0]~p[1]区间(前2个字母)->也就是 AA 所拥有的最大公共前后缀长度为1.
- D[2]=2,表示p[0]~p[2]区间(前3个字母)->也就是 AAA 所拥有的最大公共前后缀长度为2.
- D[3]=3,表示p[0]~p[3]区间(前4个字母)->也就是 AAAA 所拥有的最大公共前后缀长度为3.
- D[4]=0,表示p[0]~p[4]区间(前5个字母)->也就是 AAAAB 所拥有的最大公共前后缀长度为0.
我们先手算好了P="AAAAB"的D[i]数组(记录最大公共前后缀的长度),继续挖掘,看看有没有好东西!
- 字符串匹配问题:文本串(T),模式串(P),从T串查找符合P串的子串并返回位置
(1)举个栗子,T = "AAAAAAAAB",P="AAAAB" ,D数组上文已经求出,这个例子将引出KMP 算法的核心:j=D[j-1];

当 i = 4,j = 4 时,T串 和 P串 发生不匹配,此时我们就发现 T[0-3] 和 P[0-3] 都是匹配的。
那可以获得什么样的有用信息呢?我们从刚刚已经计算好的 D数组(记录最大公共前后缀的长度)里发现,D[3]表示这前四个字母A所对应的最大公共前后缀的长度为3,P串拥有的最大公共前后缀也是3,可以看标注的串③ 和 串④;同理,T串也拥有的最大公共前后缀也是3,可以看标注的串① 和 串②;串①、串②、串③、串④的长度完全相等,因为它们是匹配成功的部分。匹配成功的部分,P串所拥有的特质完全可以在T串里面重现,同理T串。那么在发生匹配失败时,完全相等的部分我们就不需要对它们再进行匹配了。
那就会思考:是否可以用一些方法来尽可能的跳过已经判断是能匹配的范围呢?
在i = 4, j = 4 时,匹配失败,但 0 ~ (j - 1) 的位置是匹配成功的。此时看前一个位置: j - 1 = 3 在D数组中的值和所代表意义。D[3] = 3,也就是意味着P[0]~P[3] 区间(前4个字母)所拥有的最大公共前后缀长度为3.这也意味着:P[0]~P[3]的这前4个字母已经匹配成功了。因此当匹配失败时,我们可以利用这个D数组来尽可能的跳过已经匹配成功的部分。
 着重看 串② 和 串③,通过刚才观察最大前后缀的部分,我们可以发现串② 和 串③ 是相等的。也就是这三个A没必要进行比较了,直接跳过。此时操作:i 不变,让 j = 3,即:j = D[4-1] = 3; 再让T[i] 和 P[j] 去判断是否匹配。
着重看 串② 和 串③,通过刚才观察最大前后缀的部分,我们可以发现串② 和 串③ 是相等的。也就是这三个A没必要进行比较了,直接跳过。此时操作:i 不变,让 j = 3,即:j = D[4-1] = 3; 再让T[i] 和 P[j] 去判断是否匹配。

此时 i = 4 , j = 3时,T[4] = P[3],是匹配的,那么让 i++, j++,可得到下图:

此时 i = 5 , j = 4时,T[5] ≠ P[4],是不匹配的,此时跟前面的操作一样。进行操作是:j = D[4-1]; 再让T[i] 和 P[j] 去判断是否匹配。可得到下图:

此时 i = 5 , j = 3时,T[5] = P[3],是匹配的,那么让 i++, j++,可得到下图:

此时 i = 6 , j = 4时,T[6] ≠ P[4],是不匹配的,此时跟前面的操作一样。进行操作是:j = D[4-1]; 再让T[i] 和 P[j] 去判断是否匹配。可得到下图:

此时 i = 6 , j = 3时,T[6] = P[3],是匹配的,那么让 i++, j++,可得到下图:

此时 i = 7 , j = 4时,T[7] ≠ P[4],是不匹配的,此时跟前面的操作一样。进行操作是:j = D[4-1]; 再让T[i] 和 P[j] 去判断是否匹配。可得到下图:

此时 i = 7 , j = 3时,T[7] = P[3],是匹配的,那么让 i++, j++,可得到下图:

此时 i = 8 , j = 4时,T[8] = P[4],是匹配的,那么让 i++, j++,可得到下图:

此时 i = 9(越界), j = 5(越界,表示匹配成功),终止!
总结:发现已经匹配成功的部分,它所拥有的最大公共前后缀就不用重复进行比较了,不用再花费无效的时间进行比较了,最大公共前后缀越长,那它所省略的就越多,效率也就越高。相对于暴力匹配来说,效率提升也就越高。
kmp 核心思路的关键所在:
- 1.必须理解 D[j] 的意义:P串的前 j+1个字母,即 P[0]~P[j] 所拥有的最大公共前后缀的长度
- 2.匹配到T[i] != P[j]失败时,想一想P[j]是不是P串的第j+1个字母,是不是也意味着:P[0]~P[j-1]的这前j个字母已经匹配成功了
- 3.P[0]~P[j-1]的这前 j 个字母的最大公共前后缀 = D[j-1]
----来自B站Up邋遢大王233的评论区回复
(二)KMP Code
- D[i] = P[0]至P[i],P串前 i+1 个字母拥有的最大公共前后缀的长度

D[k] 表示 P[0]~P[k]时,前 k+1 个 字母拥有的最大公共前后缀的长度
同理,D[j-1]: P[0]~P[j-1], 前 j 个 字母拥有的最大公共前后缀的长度
结合上图,D[j-1]:P[0]~P[j-1],前 j 个 字母拥有的最大公共前后缀的长度
在上图我们知道,在 i 位置的 x 和 j 位置的 y 匹配失败。此时该怎么办呢?为了更好的观察规律,我们不妨设D[j-1] = 3,也就是说P[0]~P[j-1],前 j 个 字母拥有的最大公共前后缀的长度为3。此时如下图:
观察上图,P串的下标0、1、2 完全等价于 T串的 i-1、i-2、i-3,也就是说这三个字母不用再匹配了。那下一次匹配在什么地方呢?操作:i 不变,j 回到下标为 3 这个地方,那怎么得知去下标为3这个地方呢?刚好发现D[j-1] = 3,那么让 j = D[j-1] = 3,此时 j 的位置 更新到下标为3这个位置,再从j = 3这个位置与 T 串的 x进行匹配判断。
所以由上文所举的具体例子和这个普遍例子可知,当发生匹配失败的时候:
- 此时操作: i 不变,j = D[j-1];
若 j = 0时,匹配失败。(极端例子)此时再让 j = D[j-1]是无意义的。已经越界了。那怎么办呢?

若 j = 0时,匹配失败。让 j 不变,i++

1.如果 T[i] == P[j],表示匹配成功
那就继续进行下一个字符的匹配判断,也就是i++,j++。如果说运气非常好,j == np了,说明找到了匹配结果。找到匹配起点位置:i - j
j == np (视频中没有介绍后续如何继续匹配,所以一旦匹配成功一次就结束算法了)。而匹配失败时j只可能减少不可能增加第一次匹配成功后,后续想要继续的话,继续 j = D[j-1] 就可以了(此时必然 j = np ,所以写成 j=D[np-1] 也对) ----来自B站Up邋遢大王233的评论区回复
2.如果 T[i] != P[j],表示匹配失败,有两种情况:
- 情况①:j > 0,j = D[j-1]「KMP算法核心」让其回到公共前后缀的下一个位置
- 情况②:j 退无可退了,也就是上面举的极端例子,那么此时的操作:i++
while(i < nt) :表示只要 i 没有走到头就还有匹配成功的可能性。因为 i 是不会轻易变动的
3.本文中用的是 D[ ]数组,为什么不用next数组呢?
D[i] = p[0]~p[i] 区间(前i+1个字母)所拥有的最大公共前后缀的长度
但是,书本上常见的next数组的定义是,next[i] = p[0]~p[i-1] 区间(前i个字母)所拥有的最大公共前后缀的长度
虽然这两者只是在定义上有些差别,很多人在使用Kmp,用next数组的时候,会让i=0,j=-1等等操作,会让人摸不着头脑,比较难以理解。
(三)计算 D 数组
在前文,举了一个例子,并且手算了P串的D数组该如何计算,接下来我们仔细分析其原理和代码实现:

这里采用的方法是:把P串错开一个位置,上下都是P串。但是由于错开一个位置,最开始匹配的地方是i = 1 和 j = 0。那匹配到什么地方结束呢?此时 i 在P串的最后一个位置,j 在P串的倒数第二个位置。从图里可知上P串的第一个字符和下P串的最后一个字符没有参与匹配,这意味着对P串的后缀和P串的前缀去进行匹配判断,计算最大公共前后缀
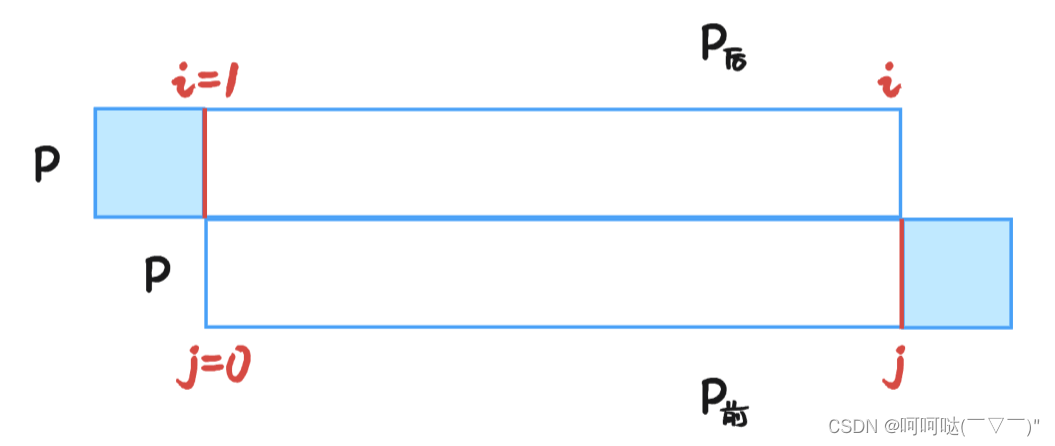
如果说在匹配的过程中,在某个时间点,此时 i 指向的字符是 x ,j 指向的字符是 y ,此时匹配失败,是否就意味着D[i] = 0?

思考问题(O_O)?:因为 P[i] ≠ P[j] 「匹配失败」,就断定D[i] = 0 ,表示从P[0] ~P[i] 没有公共前后缀?这样对吗?
其实这里就跟上文提到的KMP算法核心是一样的,绿色这块区域里面,仍然有可能存在着公共前后缀,那长度多少呢?

不妨设D[j-1] = 3,接着往下看,你的耐心真的值得鼓励!!!

发生匹配时候的时候,由于设D[j-1]=3,在图中所画的上下各自三条横线,表示上下这三个字符相匹配。在这种情况下,j 该跳转到什么地方呢?j 是跳转到下标为 3 的位置。也就是图中的标注为绿色的 j .
(1)若当前 j 所指的字符 恰好与 i 所指的字符相等,也就是图中的字符都为 x,此时 j 该更新了,j = 4,在图中表现为蓝色的 j 。那此时 D[i] = ++j;
其实计算最大公共前后缀的过程,跟KMP算法本身求解的过程是一致的,都是在利用之前求解出来的D数组来递推。当发现 P[i] ≠ P[j],我们不是马上推翻之前的结论让D[i] = 0,而是利用之前得出的结果,让 j = D[j-1];(j > 0),若此时更新的 j 位置,出现了 P[i] == P[j],那D[i] == ++j;

(2)若当前 j 所指的字符z 与 i 所指的字符x 不相等,就继续看下P串的绿色部分有没有公共前后缀,继续移动 j,移动到 当 j = 0的时候,匹配仍然失败,只能让i 移动了。
总结:错开一位后,一个取不到末尾字符,另一个取不到首字符,正是p串的前缀和后缀在匹配,能匹配成功,最大公共前后缀就能增加
举个栗子:求 AAAAB 的 D数组

当 i = 0时,D[0] = 0(初始化)。
- D[0]=0,表示 p[0]~p[0]区间(前1个字母)->也就是 A 所拥有的最大公共前后缀长度为0.
当 i = 1,j = 0 时,匹配成功,也就是 P[1] == P[0] ,此时操作:D[i] ==++j;那么D[1] = 1;
- D[1]=1,表示p[0]~p[1]区间(前2个字母)->也就是 AA 所拥有的最大公共前后缀长度为1.
当 i = 2,j = 1 时,匹配成功,也就是 P[2] == P[1] ,此时操作:D[i] ==++j;那么D[2] = 2;
- D[2]=2,表示p[0]~p[2]区间(前3个字母)->也就是 AAA 所拥有的最大公共前后缀长度为2.
当 i = 3,j = 2 时,匹配成功,也就是 P[3] == P[2] ,此时操作:D[i] ==++j;那么D[3] = 3;
- D[3]=3,表示p[0]~p[3]区间(前4个字母)->也就是 AAAA 所拥有的最大公共前后缀长度为3.

当 i = 4,j = 3 时,匹配失败,也就是 P[4] != P[3],此时操作:j = D[j-1] = D[2] = 2。如下图,此时 j 更新为2,继续与 i 所指向的字符进行匹配判断
这个时候发现仍然是匹配失败,此时操作:j = D[j-1] = D[1] = 1。如下图,此时 j 更新为1,继续与 i 所指向的字符进行匹配判断
这个时候发现仍然是匹配失败,此时操作:j = D[j-1] = D[0] = 0。如下图,此时 j 更新为0,继续与 i 所指向的字符进行匹配判断。

当 j = 0的时候,匹配仍然失败,只能让 i 移动了,故此时操作:i++。此时 i 越界,j = 0,匹配失败,故D[4] = 0

- D[4]=0,表示p[0]~p[4]区间(前5个字母)->也就是 AAAAB 所拥有的最大公共前后缀长度为0.

以下代码来自: xiaoyazi333 的 kmp.cpp
- #include
- using namespace std;
- #define SIZE (100)
- #define PRINT_ARRAY(a,n) do {for(int i = 0; i < n; i++) cout<
- /**********************************************
- KMP
- **********************************************/
- void print_matching_result(const char *p, int s)
- {
- for(int i = 0; i < s; i++)
- printf(" ");
- printf("%s\n",p);
- }
- /**********************************************
- d[i]:p[0]~p[i]共计i+1个字符的最大公共前后缀
- **********************************************/
- void calc_lps(int d[], const char *p)
- {
- int i = 1, j = 0, np = strlen(p);
- bzero(d, sizeof(int)*np);
- while(i < np)
- {
- if(p[j] == p[i])
- d[i++] = ++j;
- else
- {
- if(j > 0) j = d[j-1];
- else i++;
- }
- }
- }
- void kmp(const char *t, const char *p)
- {
- printf("**********************************************\n");
- printf("%s\n",t);
- int d[SIZE];
- calc_lps(d, p);
- int i = 0, j = 0, nt = strlen(t), np = strlen(p);
- while(i < nt)
- {
- if(p[j] == t[i])
- {
- i++,j++;
- if(j == np)
- {
- print_matching_result(p, i-j);
- j = d[np-1];
- }
- }
- else
- {
- if(j > 0) j = d[j-1];
- else i++;
- }
- }
- }
- int main()
- {
- kmp("ABABABABC", "ABAB");
- kmp("ABABCABAB", "ABAB");
- kmp("AAAAAAA", "AAA");
- kmp("ABABABC", "ABABC");
- kmp("XYXZdeOXZZKWXYZ", "WXYZ");
- kmp("GCAATGCCTATGTGACCTATGTG", "TATGTG");
- kmp("AGATACGATATATAC", "ATATA");
- kmp("CATCGCGGAGAGTATAGCAGAGAG", "GCAGAGAG");
- return 0;
- }
关键:j = D[j-1];是kmp算法的核心,它也是在做向前探索,可以去找一些复杂的例子感受一下,j是如何往前移动的,它可能不是一口气就移动到该去的位置的,它需要多次移动。设置是移动到0的位置,不得已让 i++
我的下一篇KMP 案例分析文章,大家感兴趣可以看一下这篇:
-
相关阅读:
Kafka架构和使用场景
KDChart3.0编译过程-使用QT5.15及QT6.x编译
设计模式:责任链模式
全流程GMS地下水数值模拟及溶质(包含反应性溶质)运移模拟技术深度应用
K8S集群配置私有仓库和集群功能演示
HarmonyOS ArkUI实战开发-NAPI 加载原理(上)
前端实现license许可证的需要做的工作
pureComponent
树上背包dp
MIT 6.S081学习笔记(第一章)
- 原文地址:https://blog.csdn.net/weixin_41987016/article/details/133848188

 https://www.bilibili.com/video/BV1iJ411a7Kb?p=5&vd_source=a934d7fc6f47698a29dac90a922ba5a3
https://www.bilibili.com/video/BV1iJ411a7Kb?p=5&vd_source=a934d7fc6f47698a29dac90a922ba5a3