-
Empowering Low-Light Image Enhancer through Customized Learnable Priors 论文阅读笔记

- 中科大、西安交大、南开大学发表在ICCV2023的论文,作者里有李重仪老师和中科大的Jie Huang(ECCV2022的FEC CVPR2022的ENC和CVPR2023的ERL的一作)喔,看来可能是和Jie Huang同一个课题组的,而且同样代码是开源的,我很喜欢。
- 文章利用了MAE的encoder来做一些事情,提出了一个叫customized unfolding enhancer (CUE)的方法。从MAE中学了illumination prior 和noise prior两个先验,用到了retinex模型中。流程如下图所示:

- 文章用的是如下的常规retinex公式:

- 目标是最小化如下表达式:

- 把限制项(2b)放到优化式中(拉格朗日),得到如下表达式:

- 用循环的方式来优化这个目标函数,其中L的优化目标如下:

- 用近端梯度下降法从
L
k
L_k
Lk推导出
L
k
+
1
L_{k+1}
Lk+1:

- 其中
p
r
o
x
β
ρ
2
prox_{\beta\rho_2}
proxβρ2是对先验约束
β
ρ
2
\beta\rho_2
βρ2的近端梯度下降算子,一般用一个网络来拟合。本文用的是如下网络。所以说利用MAE,其实就是利用MAE的方法来训练一个encoder来提取特征。文章用cnn做一个encoder decoder的网络,然后将输入图像用随机gamma校正进行数据增强后用三通道的max提取illumination maps后切分为不重叠的patch,随机mask掉一些patch,训练一个对illumination的inpainting模型,丢掉decoder,剩下的encoder用来放到下图的网络结构中。其实这样搞已经和MAE没多大关系了,没有注意力的MAE就是个普通的inpainting模型,所以这里其实只是用illumination inpainting任务预训练了一个encoder而已:


- R模块用的是类似的公式,只是网络就简单的得多,两层卷积加一层relu:

- N模块也是两层卷积加一层relu:


- 后面就是对估计出来的L进行增强,和KinD一样,训练的时候先用GT的L的均值除以暗图的L的均值得出一个 ε \varepsilon εconcatenate到L中(测试则直接指定一个预设值),进一个unet预测增亮后的L,同时也要把L R N都送进另一个unet预测修复后的R。修复后的R和增强后的L相乘得到增强结果I。
- 损失函数分为三部分,一部分是前面的retinex 分解的损失,一部分是增强修复网络的损失,还有一部分就是文章第二处用到MAE的noise prior损失。
- retinex分解损失有三个都是常见的,如暗图和亮图的R的距离,以及L的平滑损失,还有R和L相乘等于原图的重建损失。但有一个mutual consistency 损失好像不怎么见到,说是可以在亮度层中保留比较强的边缘而消除比较弱的边缘
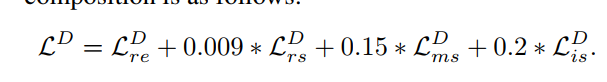
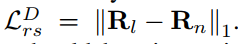


- 增强损失如下,也是比较常见:

- 第三部分的损失有点像perceptual loss,就是用一个MAE的encoder去求增强结果和GT的特征算距离,其中MAE的训练也是自己设计的,如下:


- 实验结果如下,也就一般,而且你一个有监督方法和一堆无监督方法比PSNR就不太正常了吧 :

- 评价:看起来给人的感觉就是一篇动机仅仅是为了和MAE结合做一个暗图增强的工作发一篇论文。个人观点是,做研究应该是发现问题解决问题,这篇文章看起来就像是蹭热度发论文。感觉就是大老板一拍脑袋说,最近MAE挺火,xxx你去结合MAE做一个暗图增强模型来。然后xxx kuakua一顿搞勉强拼出来一个模型,实验结果也不是很好,就找一堆无监督方法比一比,发了篇论文出来。感觉MAE的部分用得就很不自然,和一堆无监督方法比PSNR更是奇怪。唉,怎么ICCV这么多这样的论文。
-
相关阅读:
Llama-7b-hf和vicuna-7b-delta-v0合并成vicuna-7b-v0
tinymce输入框怎么限制只输入空格或者回车时不能提交
vscode中Chinese (Simplified)汉化无效解决方法
c++入门基础篇(上)
前后端分离,SpringBoot如何实现验证码操作
瑞吉外卖 —— 8、菜品展示、购物车、下单
Python实现基于交换机转发实验
9月19日学习记录
Pandas数据分析28——案例-销售额同期比分析、爬取各国新冠死亡人数等
无胁科技-TVD每日漏洞情报-2022-11-28
- 原文地址:https://blog.csdn.net/weixin_44326452/article/details/133833283