-
Spark上使用pandas API快速入门
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的动态,一起学习,共同进步。
相关文章:
这是 Spark 上的 pandas API 的简短介绍,主要面向新用户。本笔记本向您展示 pandas 和 Spark 上的 pandas API 之间的一些关键区别。您可以在快速入门页面的“Live Notebook:Spark 上的 pandas API”中自行运行此示例。
习惯上,我们在Spark上导入pandas API如下:
- import pandas as pd
- import numpy as np
- import pyspark.pandas as ps
- from pyspark.sql import SparkSession
对象创建
通过传递值列表来创建 pandas-on-Spark 系列,让 Spark 上的 pandas API 创建默认整数索引:
- s = ps.Series([1, 3, 5, np.nan, 6, 8])
- s
0 1.0 1 3.0 2 5.0 3 NaN 4 6.0 5 8.0 dtype: float64
通过传递可转换为类似系列的对象字典来创建 pandas-on-Spark DataFrame。
- psdf = ps.DataFrame(
- {'a': [1, 2, 3, 4, 5, 6],
- 'b': [100, 200, 300, 400, 500, 600],
- 'c': ["one", "two", "three", "four", "five", "six"]},
- index=[10, 20, 30, 40, 50, 60])
- psdf
a b c 10 1 100 one 20 2 200 two 30 3 300 three 40 4 400 four 50 5 500 five 60 6 600 six 创建pandas DataFrame通过numpyt array, 用datetime 作为索引,label列
- dates = pd.date_range('20130101', periods=6)
- dates
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04', '2013-01-05', '2013-01-06'], dtype='datetime64[ns]', freq='D')
- pdf = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
- pdf
A B C D 2013-01-01 0.912558 -0.795645 -0.289115 0.187606 2013-01-02 -0.059703 -1.233897 0.316625 -1.226828 2013-01-03 0.332871 -1.262010 -0.434844 -0.579920 2013-01-04 0.924016 -1.022019 -0.405249 -1.036021 2013-01-05 -0.772209 -1.228099 0.068901 0.896679 2013-01-06 1.485582 -0.709306 -0.202637 -0.248766 现在,dataframe能够转换成pandas 在spark上运行
- psdf = ps.from_pandas(pdf)
- type(psdf)
pyspark.pandas.frame.DataFrame
看上去和dataframe一样的使用
psdfA B C D 2013-01-01 0.912558 -0.795645 -0.289115 0.187606 2013-01-02 -0.059703 -1.233897 0.316625 -1.226828 2013-01-03 0.332871 -1.262010 -0.434844 -0.579920 2013-01-04 0.924016 -1.022019 -0.405249 -1.036021 2013-01-05 -0.772209 -1.228099 0.068901 0.896679 2013-01-06 1.485582 -0.709306 -0.202637 -0.248766 当然通过spark pandas dataframe创建pandas on spark dataframe 非常容易
- spark = SparkSession.builder.getOrCreate()
- sdf = spark.createDataFrame(pdf)
- sdf.show()
+--------------------+-------------------+--------------------+--------------------+ | A| B| C| D| +--------------------+-------------------+--------------------+--------------------+ | 0.91255803205208|-0.7956452608556638|-0.28911463069772175| 0.18760566615081622| |-0.05970271470242...| -1.233896949308984| 0.3166246451758431| -1.2268284000402265| | 0.33287106947536615|-1.2620100816441786| -0.4348444277082644| -0.5799199651437185| | 0.9240158461589916|-1.0220190956326003| -0.4052488880650239| -1.0360212104348547| | -0.7722090016558953|-1.2280986385313222| 0.0689011451939635| 0.8966790729426755| | 1.4855822995785612|-0.7093056426018517| -0.2026366848847041|-0.24876619876451092| +--------------------+-------------------+--------------------+--------------------+
从 Spark DataFrame 创建 pandas-on-Spark DataFrame。
- psdf = sdf.pandas_api()
- psdf
A B C D 0 0.912558 -0.795645 -0.289115 0.187606 1 -0.059703 -1.233897 0.316625 -1.226828 2 0.332871 -1.262010 -0.434844 -0.579920 3 0.924016 -1.022019 -0.405249 -1.036021 4 -0.772209 -1.228099 0.068901 0.896679 5 1.485582 -0.709306 -0.202637 -0.248766 具有特定的dtypes。目前支持 Spark 和 pandas 通用的类型。
psdf.dtypesA float64 B float64 C float64 D float64 dtype: object
以下是如何显示下面框架中的顶行。
请注意,Spark 数据帧中的数据默认不保留自然顺序。可以通过设置
compute.ordered_head选项来保留自然顺序,但它会导致内部排序的性能开销。psdf.head()A B C D 0 0.912558 -0.795645 -0.289115 0.187606 1 -0.059703 -1.233897 0.316625 -1.226828 2 0.332871 -1.262010 -0.434844 -0.579920 3 0.924016 -1.022019 -0.405249 -1.036021 4 -0.772209 -1.228099 0.068901 0.896679 展示index和columns 通过numpy 数据
psdf.indexInt64Index([0, 1, 2, 3, 4, 5], dtype='int64')
psdf.columnsIndex(['A', 'B', 'C', 'D'], dtype='object')
psdf.to_numpy()array([[ 0.91255803, -0.79564526, -0.28911463, 0.18760567], [-0.05970271, -1.23389695, 0.31662465, -1.2268284 ], [ 0.33287107, -1.26201008, -0.43484443, -0.57991997], [ 0.92401585, -1.0220191 , -0.40524889, -1.03602121], [-0.772209 , -1.22809864, 0.06890115, 0.89667907], [ 1.4855823 , -0.70930564, -0.20263668, -0.2487662 ]])通过简单统计展示你的数据:
psdf.describe()A B C D count 6.000000 6.000000 6.000000 6.000000 mean 0.470519 -1.041829 -0.157720 -0.334542 std 0.809428 0.241511 0.294520 0.793014 min -0.772209 -1.262010 -0.434844 -1.226828 25% -0.059703 -1.233897 -0.405249 -1.036021 50% 0.332871 -1.228099 -0.289115 -0.579920 75% 0.924016 -0.795645 0.068901 0.187606 max 1.485582 -0.709306 0.316625 0.896679 转置你的数据:
psdf.T0 1 2 3 4 5 A 0.912558 -0.059703 0.332871 0.924016 -0.772209 1.485582 B -0.795645 -1.233897 -1.262010 -1.022019 -1.228099 -0.709306 C -0.289115 0.316625 -0.434844 -0.405249 0.068901 -0.202637 D 0.187606 -1.226828 -0.579920 -1.036021 0.896679 -0.248766 通过index进行排序:
psdf.sort_index(ascending=False)A B C D 5 1.485582 -0.709306 -0.202637 -0.248766 4 -0.772209 -1.228099 0.068901 0.896679 3 0.924016 -1.022019 -0.405249 -1.036021 2 0.332871 -1.262010 -0.434844 -0.579920 1 -0.059703 -1.233897 0.316625 -1.226828 0 0.912558 -0.795645 -0.289115 0.187606 按照值排序:
psdf.sort_values(by='B')A B C D 2 0.332871 -1.262010 -0.434844 -0.579920 1 -0.059703 -1.233897 0.316625 -1.226828 4 -0.772209 -1.228099 0.068901 0.896679 3 0.924016 -1.022019 -0.405249 -1.036021 0 0.912558 -0.795645 -0.289115 0.187606 5 1.485582 -0.709306 -0.202637 -0.248766 缺失数据
Spark 上的 Pandas API 主要使用该值
np.nan来表示缺失的数据。默认情况下,它不包含在计算中。- pdf1 = pdf.reindex(index=dates[0:4], columns=list(pdf.columns) + ['E'])
- pdf1.loc[dates[0]:dates[1], 'E'] = 1
- psdf1 = ps.from_pandas(pdf1)
- psdf1
A乙 C D 乙 2013-01-01 0.912558 -0.795645 -0.289115 0.187606 1.0 2013-01-02 -0.059703 -1.233897 0.316625 -1.226828 1.0 2013-01-03 0.332871 -1.262010 -0.434844 -0.579920 南 2013-01-04 0.924016 -1.022019 删除任何缺少数据的行。
psdf1.dropna(how='any')A B C D E 2013-01-01 0.912558 -0.795645 -0.289115 0.187606 1.0 2013-01-02 -0.059703 -1.233897 0.316625 -1.226828 psdf1.fillna(value=5)A B C D E 2013-01-01 0.912558 -0.795645 -0.289115 0.187606 1.0 2013-01-02 -0.059703 -1.233897 0.316625 -1.226828 1.0 2013-01-03 0.332871 -1.262010 -0.434844 -0.579920 5.0 2013-01-04 0.924016 -1.022019 -0.405249 -1.036021 5 操作
统计数据
执行描述性统计:
psdf.mean()A 0.470519
B -1.041829
C -0.157720
D -0.334542
dtype: float64
Spark配置PySpark 中的各种配置可以在 Spark 上的 pandas API 内部应用。例如,您可以启用 Arrow 优化来极大地加快内部 pandas 转换。另请参阅 PySpark 文档中的 Pandas 使用 Apache Arrow 的 PySpark 使用指南。
- prev = spark.conf.get("spark.sql.execution.arrow.pyspark.enabled") # Keep its default value.
- ps.set_option("compute.default_index_type", "distributed") # Use default index prevent overhead.
- import warnings
- warnings.filterwarnings("ignore") # Ignore warnings coming from Arrow optimizations.
- spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", True)
- %timeit ps.range(300000).to_pandas()
每个循环 900 ms ± 186 ms(7 次运行的平均值 ± 标准差,每次 1 个循环)
- spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", False)
- %timeit ps.range(300000).to_pandas()
每个循环 3.08 s ± 227 ms(7 次运行的平均值 ± 标准差,每次 1 个循环)
- ps.reset_option("compute.default_index_type")
- spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", prev) # Set its default value back.
分组
我们所说的“分组依据”是指涉及以下一个或多个步骤的过程:
-
根据某些标准将数据分组
-
独立地将函数应用于每个组
-
将结果组合成数据结构
- psdf = ps.DataFrame({'A': ['foo', 'bar', 'foo', 'bar',
- 'foo', 'bar', 'foo', 'foo'],
- 'B': ['one', 'one', 'two', 'three',
- 'two', 'two', 'one', 'three'],
- 'C': np.random.randn(8),
- 'D': np.random.randn(8)})
- psdf
A B C D 0 foo one 1.039632 -0.571950 1 bar one 0.972089 1.085353 2 foo two -1.931621 -2.579164 3 bar three -0.654371 -0.340704 4 foo two -0.157080 0.893736 5 bar two 0.882795 0.024978 6 foo one -0.149384 0.201667 7 foo three -1.355136 0.693883 分组后求和:psdf.groupby('A').sum()C D A bar 1.200513 0.769627 foo -2.553589 -1.361828 按多列分组形成分层索引,我们可以再次应用 sum 函数。
psdf.groupby(['A', 'B']).sum()C D A B foo one 0.890248 -0.370283 two -2.088701 -1.685428 bar three -0.654371 -0.340704 foo three -1.355136 0.693883 bar two 0.882795 0.024978 one 0.972089 1.085353 绘图
- pser = pd.Series(np.random.randn(1000),
- index=pd.date_range('1/1/2000', periods=1000))
- psser = ps.Series(pser)
- psser = psser.cummax()
- psser.plot()
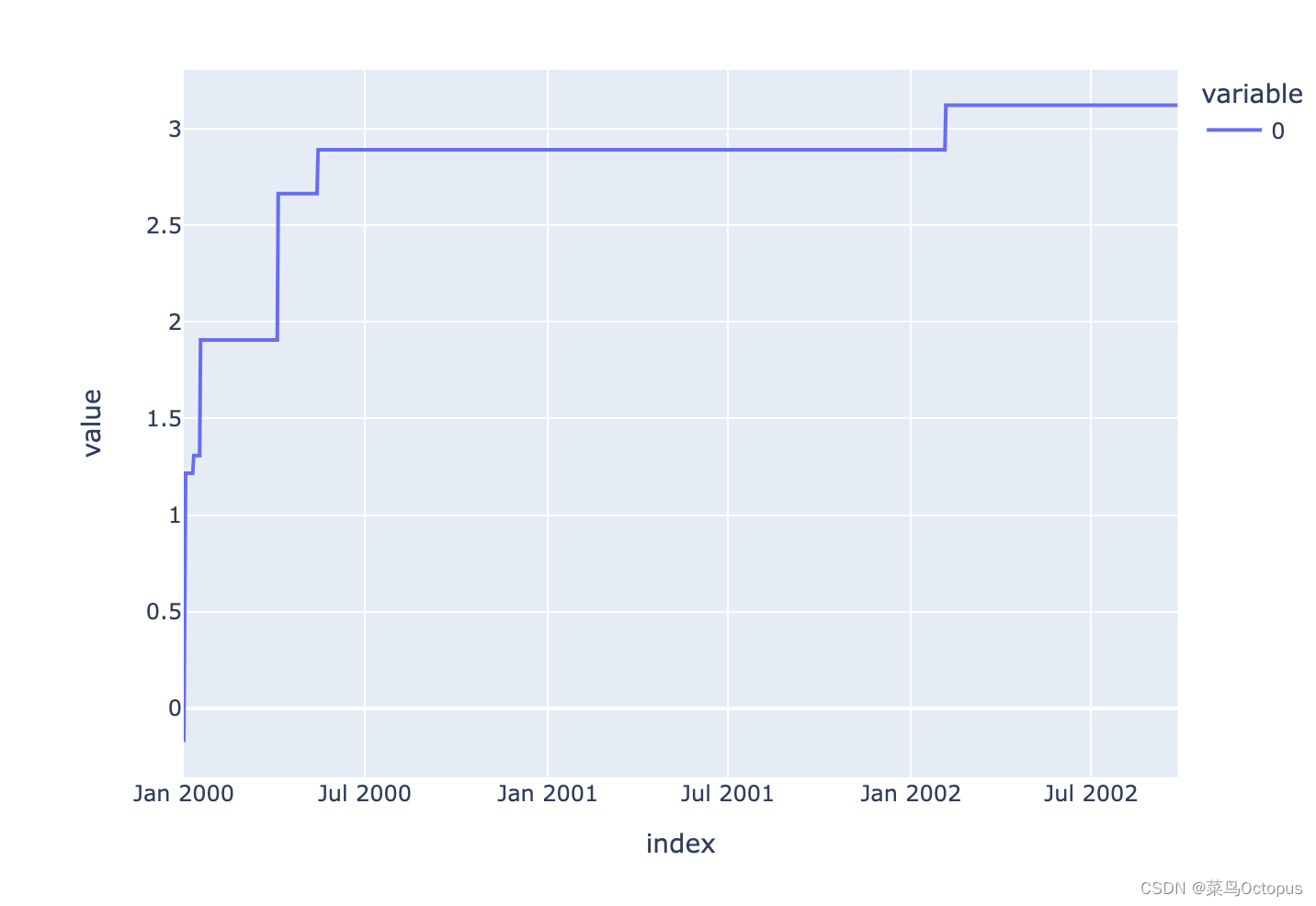
在 DataFrame 上,plot()方法可以方便地绘制带有标签的所有列:
- pdf = pd.DataFrame(np.random.randn(1000, 4), index=pser.index,
- columns=['A', 'B', 'C', 'D'])
- psdf = ps.from_pandas(pdf)
- psdf = psdf.cummax()
- psdf.plot()
 有关更多详细信息,请参阅绘图文档。
有关更多详细信息,请参阅绘图文档。获取数据输入/输出
CSV
CSV 简单且易于使用。请参阅此处写入 CSV 文件,并参阅此处读取 CSV 文件。
- psdf.to_csv('foo.csv')
- ps.read_csv('foo.csv').head(10)
A B C D 0 -1.187097 -0.134645 0.377094 -0.627217 1 0.331741 0.166218 0.377094 -0.627217 2 0.331741 0.439450 0.377094 0.365970 3 0.621620 0.439450 1.190180 0.365970 4 0.621620 0.439450 1.190180 0.365970 5 2.169198 1.069183 1.395642 0.365970 6 2.755738 1.069183 1.395642 1.045868 7 2.755738 1.069183 1.395642 1.045868 8 2.755738 1.069183 1.395642 1.045868 9 2.755738 1.508732 1.395642 Parquet
parquet是高效和压缩的数据格式,支持快速的读写;下图是它读写的例子。
- psdf.to_parquet('bar.parquet')
- ps.read_parquet('bar.parquet').head(10)
A B C D 0 -1.187097 -0.134645 0.377094 -0.627217 1 0.331741 0.166218 0.377094 -0.627217 2 0.331741 0.439450 0.377094 0.365970 3 0.621620 0.439450 1.190180 0.365970 4 0.621620 0.439450 1.190180 0.365970 5 2.169198 1.069183 1.395642 0.365970 6 2.755738 1.069183 1.395642 1.045868 7 2.755738 1.069183 1.395642 1.045868 8 2.755738 1.069183 1.395642 1.045868 9 2.755738 1.508732 1.395642 1.556933 Spark IO
另外,pandas API能很好支持Spark多种数据源结构,例如ORC和其他的数据源,这里看他写入的数据源和读取数据源。
- psdf.to_spark_io('zoo.orc', format="orc")
- ps.read_spark_io('zoo.orc', format="orc").head(10)
A B C D 0 -1.187097 -0.134645 0.377094 -0.627217 1 0.331741 0.166218 0.377094 -0.627217 2 0.331741 0.439450 0.377094 0.365970 3 0.621620 0.439450 1.190180 0.365970 4 0.621620 0.439450 1.190180 0.365970 5 2.169198 1.069183 1.395642 0.365970 6 2.755738 1.069183 1.395642 1.045868 7 2.755738 1.069183 1.395642 1.045868 8 2.755738 1.069183 1.395642 1.045868 9 2.755738 1.508732 1.395642 1.556933 这里看输入和输出文档获取更多的细节。
-
相关阅读:
【Java进阶】字符串和常见集合
aj-report 报表设计器如何添加组件
【云原生之Docker实战】使用Docker部署Homepage应用程序仪表盘
JUC中的AQS底层详细超详解
WPF元素绑定
Win10卸载KB5014699补丁教程
Flink之Watermark策略代码模板
[附源码]Python计算机毕业设计Django电影推荐网站
ARTS 打卡第一周
分布式事务-TCC异常-空回滚
- 原文地址:https://blog.csdn.net/zy345293721/article/details/133815364