-
大数据学习(7)-hive文件格式总结
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博>主哦🤞
Hive文件格式
为Hive表中的数据选择一个合适的文件格式,对提高查询性能的提高是十分有益的。Hive表数据的存储格式,可以选择text file、orc、parquet、sequence file等。
Text File
文本文件是Hive默认使用的文件格式,文本文件中的一行内容,就对应Hive表中的一行记录。
可通过以下建表语句指定文件格式为文本文件:
- create table textfile_table
- (column_specs)
- stored as textfile;
ORC
1)文件格式
ORC(Optimized Row Columnar)file format是Hive 0.11版里引入的一种列式存储的文件格式。ORC文件能够提高Hive读写数据和处理数据的性能。
与列式存储相对的是行式存储,下图是两者的对比:
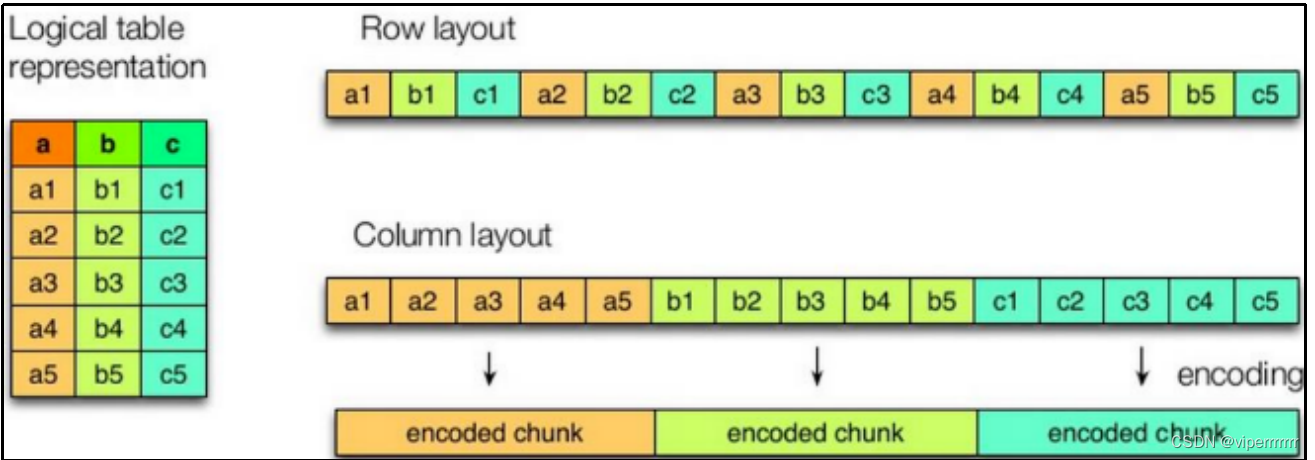
如图所示左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
(1)行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
(2)列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
前文提到的text file和sequence file都是基于行存储的,orc和parquet是基于列式存储的。
每个Orc文件由Header、Body和Tail三部分组成。
其中Header内容为ORC,用于表示文件类型。
Body由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,每个stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer。
Index Data:一个轻量级的index,默认是为各列每隔1W行做一个索引。每个索引会记录第n万行的位置,和最近一万行的最大值和最小值等信息。
Row Data:存的是具体的数据,按列进行存储,并对每个列进行编码,分成多个Stream来存储。
Stripe Footer:存放的是各个Stream的位置以及各column的编码信息。
Tail由File Footer和PostScript组成。File Footer中保存了各Stripe的其实位置、索引长度、数据长度等信息,各Column的统计信息等;PostScript记录了整个文件的压缩类型以及File Footer的长度信息等。
在读取ORC文件时,会先从最后一个字节读取PostScript长度,进而读取到PostScript,从里面解析到File Footer长度,进而读取FileFooter,从中解析到各个Stripe信息,再读各个Stripe,即从后往前读。
3)建表语句
- create table orc_table
- (column_specs)
- stored as orc
- tblproperties (property_name=property_value, ...);
ORC文件格式支持的参数如下:
参数
默认值
说明
orc.compress
ZLIB
压缩格式,可选项:NONE、ZLIB,、SNAPPY
orc.compress.size
262,144
每个压缩块的大小(ORC文件是分块压缩的)
orc.stripe.size
67,108,864
每个stripe的大小
orc.row.index.stride
10,000
索引步长(每隔多少行数据建一条索引)
Parquet
Parquet文件是Hadoop生态中的一个通用的文件格式,它也是一个列式存储的文件格式。
上图展示了一个Parquet文件的基本结构,文件的首尾都是该文件的Magic Code,用于校验它是否是一个Parquet文件。
首尾中间由若干个Row Group和一个Footer(File Meta Data)组成。
每个Row Group包含多个Column Chunk,每个Column Chunk包含多个Page。以下是Row Group、Column Chunk和Page三个概念的说明:
行组(Row Group):一个行组对应逻辑表中的若干行。
列块(Column Chunk):一个行组中的一列保存在一个列块中。
页(Page):一个列块的数据会划分为若干个页。
Footer(File Meta Data)中存储了每个行组(Row Group)中的每个列快(Column Chunk)的元数据信息,元数据信息包含了该列的数据类型、该列的编码方式、该类的Data Page位置等信息。
3)建表语句
- Create table parquet_table
- (column_specs)
- stored as parquet
- tblproperties (property_name=property_value, ...);
支持的参数如下:
参数
默认值
说明
parquet.compression
uncompressed
压缩格式,可选项:uncompressed,snappy,gzip,lzo,brotli,lz4
parquet.block.size
134217728
行组大小,通常与HDFS块大小保持一致
parquet.page.size
1048576
页大小
-
相关阅读:
【Leetcode】 406. 根据身高重建队列
使用Python处理ADC激光测距数据并绘制为图片(二)
卷积输入输出维度计算公式,Conv, Dilation Conv, Padding, Kernel_size, Output的维度计算关系
【NSFileManager常用方法之获取信息 Objective-C语言】
出详图和工程图(下)-SOLIDWORKS 2024新功能
Python输入与输出(文件读取、json格式转换)
项目网页聊天室
如何用vscode远程连接Linux服务器
新零售SaaS架构:订单履约系统的应用架构
张高兴的 Entity Framework Core 即学即用:(一)创建第一个 EF Core 应用
- 原文地址:https://blog.csdn.net/weixin_61006262/article/details/133800786