-
机器学习(22)---信息熵、纯度、条件熵、信息增益
1、信息熵
1. 信息熵(information entropy)是度量样本集合纯度最常用的一种指标。信息的混乱程度越大,不确定性越大,信息熵越大;对于纯度,就是信息熵越大,纯度越低。
2. 纯度的通俗理解:一个盒子里只有白球,说明这个盒子很纯,纯度很高。一个集合里只有一类样本,比如表示男女的样本集合 U = U= U={男,男,…},都是男的,那么就说这个集合纯度很高。
3. 信息熵公式如下所示,其中 n n n表示随机变量的可能取值数, x x x表示随机变量, p ( x ) p(x) p(x)表示随机变量的概率函数。

2、信息增益
1. 条件熵:在 X X X给定条件下, Y Y Y的条件概率分布的熵对 X X X的数学期望。


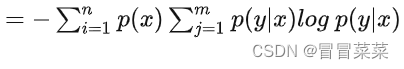
同理可知:

2. 信息增益:以某特征划分数据集前后的熵的差值。熵 A A A-条件熵 B B B,是信息量的差值,表示此条件对于信息熵减少的程度。也就是说,一开始是 A A A状态,用了条件后变成了 B B B状态,则条件引起的变化是 A − B A-B A−B,即信息增益。
熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合 D D D划分效果的好坏。
结论:好的条件就是信息增益越大越好,即变化完后熵越小越好(熵代表混乱程度,最大程度地减小了混乱)。因此我们在树分叉的时候,应优先使用信息增益最大的属性,这样降低了复杂度,也简化了后边的逻辑。3. 信息增益的公式如下。其中 A A A就是一个特征, D D D是原始的数据集, D ∣ A D∣A D∣A是在 A A A分类下的数据集。
3、例题分析
1. 例子分析信息熵


2. 例子分析信息增益编号 身高(特征1) 颜值(特征2) 喜欢喝酒程度(特征3) 是否渣男(分类结果) 1 中 1 3 否 2 低 2 1 否 3 低 3 3 是 4 高 2 3 否 5 高 1 2 否 身高、颜值、喝酒都是特征,是否渣男是分类结果。我们来算已知 A A A事件为身高情况下的信息增益:
3. 例子分析信息增益


-
相关阅读:
HashMap为什么线程不安全?
Java面试八股文宝典:初识数据结构-数组的应用扩展之HashTable
如何扫描到最新可用的http代理ip?
戴口罩 目标检测数据集-12000张
windows 锁屏时执行某个程序
磨金石教育摄影技能干货分享|上海随手拍——叶落满街,秋意未尽
如何优雅的加密配置文件中的敏感信息
【springboot笔记】程序可用性检测ApplicationAvailability
香港服务器的速度为什么比较快
C++语言基础篇
- 原文地址:https://blog.csdn.net/m0_62881487/article/details/133797777