-
ORACLE逻辑存储结构
存储结构
1数据文件
数据库存储逻辑结构是表空间-段-区段-块,数据库文件包括控制文件,联机重做日志,数据文件等。我们主要讲数据文件
1.1表空间
我们在搭建环境的第6节,创建了表空间apps_data_tablespace,创建语法中包含了数据库文件APPS_DATA_TABLESPACE.dbf,所有在该表空间下存储的数据都放在该数据文件中,
使用下列SQL查看当前表空间使用状态
SELECT a.tablespace_name "表空间名"
,total "表空间大小"
,(total - free) "已使用大小"
,free "表空间剩余大小"
,round(total / (1024 * 1024)) "表空间大小(M)"
,round((total - free) / (1024 * 1024)) "已使用大小(M)"
,round(free / (1024 * 1024)) "表空间剩余大小(M)"
,round((total - free) / total
,4) * 100 "使用率%"
FROM (SELECT tablespace_name
,SUM(bytes) free
FROM dba_free_space
GROUP BY tablespace_name) a
,(SELECT tablespace_name
,SUM(bytes) total
FROM dba_data_files
GROUP BY tablespace_name) b
WHERE a.tablespace_name = b.tablespace_name;

创建数据库时,DBCA会自动创建SYSTEM,SYSAUX,UNDOTBS1三个表空间,分别用于
存储数据字典;
存储数据字典辅助数据;
回滚段,用于保持数据一致性。
(什么是数据字典:指描述数据库及其内容的元数据。可以假设数据字典是一张表,我们的create table, alter column,grant create to 等语句,最终就会在这张“表”上进行增删操作,数据字典对我们而言是透明的,但是oracle提供了一组视图供我们查询,前缀分别是user_ ,all_,dba_,cdb_比如user_objects ,all_objects dba_objects ,分别代码能查询当前用户下创建的对象,当前用户有权限创建的对象,数据库所有对象。我们编写的视图,序列,PLSQL代码,也存储在数据字典当中,因为他们不存储数据)
一个表空间可以对应一个或多个数据文件(指定small file才能创建多个数据文件,如果创建表空间时指定关键词为bigfile,将无法为表空间创建多个数据文件,参考链接
Bigfile Type Tablespaces versus Smallfile Type | Database Journal
),从上图可以看到,我的SYSTEM和SYSAUX表空间快满了,我们可以创建为此表空间创建多个数据文件,也可以为当前表空间扩容,我来分别演示一下。
我们把创建表空间的语句拿过来分析
create tablespace apps_data_tablespace
datafile '/usr/local/oracle/oradata/ORCL/APPS_DATA_TABLESPACE.dbf'
size 200m
autoextend on next 8m maxsize 1024m
permanent
extent management local;
Autoextend表示以8m的大小自动扩展,最多扩展到1G
再次查询表空间属性

我们创建的表空间最多自动扩展到32G,可以使用下列语法,为表空间创建新的数据文件,或者修改自动扩展属性
alter database datafile '/usr/local/oracle19c/oradata/ORCL/system01.dbf' resize 2G;--将数据文件手动扩容到不超过maxsise的大小
可以看到system表空间占有率马上降下来,当然不resize也可以,因为快满了会自动扩容

--为表空间创建第二个数据文件
add tablespace SYSAUX add datafile '/usr/local/oracle19c/oradata/ORCL/sysaux02.dbf' size 8m;
--设置数据文件自动扩展
alter database datafile '/usr/local/oracle19c/oradata/ORCL/sysaux02.dbf' autoextend on next 8m maxsize 2g;
--删除新创建的数据文件
Alter tablespace SYSAUX drop datafile '/usr/local/oracle19c/oradata/ORCL/sysaux02.dbf';
--删除表空间(同时删除数据文件)
drop tablespace tablespacename including contents and datafiles;
--为临时表空间创建第二个数据文件
alter tablespace temp add tempfile '/usr/local/oracle19c/oradata/DUPDB/temp02.dbf' size 8m;
--修改系统默认临时表空间
ALTER DATABASE DEFAULT TEMPORARY TABLESPACE TEMP;
select * from database_properties where property_name='DEFAULT_TEMP_TABLESPACE';
--修改用户默认临时表空间
ALTER USER apps TEMPORARY TABLESPACE TEMP;
SELECT USERNAME, TEMPORARY_TABLESPACE FROM DBA_USERS d where d.username='APPS'
这里我就不一一演示了。
表空间有一个属性logging,表示是否产生重做日志,我们在大批量insert和临时表也会接触这个logging,不产生重做日志的临时表和日志表,才是性能较好的表。
表空间是逻辑概念,数据文件是物理概念,我们可以设置表空间脱机或者在线,重命名表空间,设置表空间只读等。对于数据文件,可以调整大小,增删数据文件等。感兴趣自行搜索
多提一句,后面会介绍表分区和索引分区,分区的核心就是,根据分区策略,将表数据拆分到不同的表段中,每个段放在相同(相同的表空间并没有充分体现分区表,索引的优越性)或不同的表空间中。什么是段,下面进行讲解
1.2段
一个表空间有1个多G,这个文件不可能只存一张表的数据,比如所有CUX下的表都存储在表空间APPS_TS_TX_DATA中,如果把表空间比作一个文件夹,文件夹下的每一个文件就是“段”。段是表空间的主要组织结构,比如下面创建表的语句
create table cux_test2(a number,b clob) tablespace APPS_DATA_TABLESPACE;
create index cux_test2_n1 on cux_test2(a) tablespace APPS_IDX_TABLESPACE;
上面的语句一共创建了几个段?
答案是0个,因为创建表时未指定segment creation immediate关键词,就会以默认的SEGMENT CREATION DEFERRED延迟段创建。
当我们写入一条数据之后(这时候才真正分配区段),我们查询一下新创建的段

新创建了四个段,虽然我没有对clob字段创建索引,却产生了lobindex段,搜了一下是数据库默认行为。
你可以把段理解成一个对象,我们创建了一张非分区表,一个索引,一个clob字段,一个clob索引(虽然我并没有为clob创建索引),有四个对象,对应四个段。a作为number字段为什么不会创建段,因为clob全称叫character large object,字符型大对象,表段CUX_TEST1的b字段会存一个clob对象的指针,然后通过这个指针去clob段SYS_LOB0000101534C00002$$取得clob对象。
1.3块
块是数据库可操作的最小存储单元,是一个逻辑概念,好比扇区是磁盘的最小存储单元,簇是操作系统的最小存储单元。块默认是8KB,8KB是默认的,你可以指定2KB 3KB等

块的结构如下

图来源:Data Blocks, Extents, and Segments
从上到下分别为,
首部:用于标识是表块还是索引块,并存储了有关事务信息,当发生DML操作时,标志“脏”块(感兴趣的搜一下关键词“块清除”)
表目录:一个块有8K,因此一个块有可能存放了超过一张表的数据,用表目录记录这个块上到底有哪些表的数据(这个是官方的解释,但是有点不认同,因为两个不同的表,肯定对应两个不同的表段,每一个表段对应不同的区段,区段都不一样了,怎么会存放在同一个块内呢?)
行目录:数据块的这部分包含有关块中实际行的信息(包括行数据区中每个行段的地址)。
空闲空间:空闲空间被分配用于插入新行和更新需要额外空间的行
数据:用于存储实际的数据,首部,表目录和行目录不存储数据,有点类似TCP协议的首部
尾部
1.4区段
存储结构是表空间-段-区段-块。我们把逻辑存储连续的块,就叫做区段。(定长数组是在内存中物理和逻辑都连续的数据结构,链表是在内存中逻辑连续,物理不连续的数据结构,区段就点类似链表)因为这种不连续导致的跨扇区扫描,可以类比成磁盘碎片。
当我们创建表并写入第一条数据的同时,数据库创建段并分配第一个区段,区段的大小一般是8个块大小,也就是64KB的区段。下一次分配也是8个块,总共分配16次,满了之后开始分配逻辑连续的128个块的区段……(这是官方解释,实际测试第一次的8个块满了就开始分配128个块了),如下图

上图显示了段名CUX_TEST2,所在表空间,以及段空间是A(aotu)SSM自动段空间管理。
然后再看一下我打红框的内容,BYTES字段表示已经为我分配了8个块大小(65535/1024/8=8,一个块8KB,65535B=8个块大小),INITIAL_EXTENT表示初始分配的区段为8个块,下一次分配的区段是128个块,因为CLOB数据会放在CLOB对应的段里,我们通过上一节内容得到对应的段名是SYS_LOB0000101534C00002$$(如果要查CUX_TEST2段,则必须alter add 一个 varchar2列,各位可以自己用这个段测试)
现在开始我们的测试

上图显示clob字段对应的段不是表对应的段CUX_TEST2,而是一个CLOB段,初始化给了16个块,一个英文字符是1B,我写入131072(128K,将会占用16个块)个A字符,看看段状态(一个块是8K,但是可用的部分并不是8K,因为有块首部,所以可能我写到80000个的时候,就开始分配下一个区段了)
测试脚本如下:
declare
a clob;
begin
DBMS_LOB.createtemporary(lob_loc => a,cache => true);
a:='A';
for i in 1..17 loop--2^17=131072
dbms_lob.append(a,a);
end loop;
insert into cux_test2(b)values(a);
DBMS_OUTPUT.put_line(DBMS_LOB.getlength(a) );
end;
此时我们还未提交,但是数据已经真正写入磁盘了,我们查看一下段空间

(上面的extents=3是因为我查错段名了,查成CUX_TEST2,然后觉得怎么没反应,又多点了一次执行。)
我执行了两次,且都没提交或回滚,数据已经发生了写入并一共分配了三次区段,新写入的数据在数据文件中,旧的数据放在UNDO回滚段中(回滚段也在数据文件中,如果没有空闲空间分配给回滚段,会发生什么?回滚段不能无限扩展,当回滚段中没有可用的块时将覆盖旧的块,导致快照过旧),现在我进行rollback,然后查询段空间
段空间并没有发生收缩,也就是这段空间其实是被浪费掉了,频繁的对insert进行rollback
实际上是先insert再delete,将会导致大量的空间浪费,IO开销也会很大.
我们再查询一下区段信息

很清楚的看到进行了三次扩展(不过为什么第二次只扩展了8个块,而不是128个块或者连续的16次8个块,难道都是第一次扩展都是8个,各位有兴趣可以创建一个varchar2字段测试一下表段的扩展情况,我是用clob段测试的,因为clob段很容易写入1m也就是128个块数据)
每个数据文件对应一个位图(什么是位图,我们在讲索引的时候会谈论到它,可以先理解成一个数组,数组的值只存0和1),每一个块就作为位图的一个条目,当该块作为区段的一部分被分配出去了(所以区块应该是最小的分配单元),就将对应位图的值由0改成1,想要逻辑连续的区段,就在位图上寻找连续的一段1,然后拿到这些1的物理磁盘地址,进行分配。创建表空间时,通过指定关键词 uniform size 来统一设置区段的大小(如果你的表特别大(非lob段,单纯就是行数特别多),对应的区段就特别多,就需要设置较大的uniform size ,比如一个区段大小是200M,减少因区段管理带来的性能损耗。当然也可以分区,但是即使是分10个区,每一个区段还是1m这么小,效果不如增加区段大小来的明显
)
LMT 中的范围大小由UNIFORM和AUTOALLOCATE子句确定。如果指定了 UNIFORM,则表空间内的所有范围的大小都相同,默认范围大小为 1M。该AUTOALLOCATE子句允许您调整初始范围的大小,让 Oracle 确定后续范围的最佳大小,最小值为 64K。
什么时候使用这个uniform size,比如你的表空间中段很大,使用这个将一次性分配好。
小结一下,一个表空间里面有多个表对应的段,但是每个表段只能放在单独的一个表空间内。(因为CUX下的表,不能存放到APPS表空间内),段以区段进行空间分配,区段内都是逻辑连续的块,块是最小的存储单元。
1.5段空间管理
当insert一行数据时,数据库通过查询数据文件附带的位图查询空块,然后往里写入数据。这时我们进行update的时候,比如我们的varchar2类型和clob类型,假如新的数据是varchar(4000),老的数据是null,新的比旧的大,导入该块满了,就会发生行迁移,数据库会找一个新的空块写入我们update之后的数据,然后再删掉旧块上对应的数据,并维护一个指针,由旧块指向新块。那么如果由于大量的UPDATE导致大量的行迁移,从而导致IO数量大量上涨(索引维护的是旧块的物理地址ROWID,但是旧块上已经发生行迁移了,需要从旧块的指针查询到新块的物理地址,然后取出数据,增加了一次IO,要想更新索引维护新块的ROWID,可以使用alter table shrink 或者使用分区表,分区表会自动更新ROWID)。当然合理设置参数PCTFREE能大大减小行迁移,PCTFRE用于告诉ORACLE预留多少空间用于更新,正是因为更新导致块可用空间不足,才会导致行迁移(缺点是假如这个表很少发生update,设置较大的PCTFREE将会很占用磁盘空间,毕竟一个块设置PCTFREE部分都不能被insert)。
使用下列SQL查询行迁移情况
- 查询表sys.chained_rows是否存在,如果不存在,去$ORCLE_HOME/rdmbs/admin下执行utlchain.sql脚本创建该表,具体操作跟安装statspark一模一样
- 执行ANALYZE TABLE apps.cux_test2 list chained rows;分析表

- 查询下列SQL,返回的行数确定了有多少行发生了行迁移
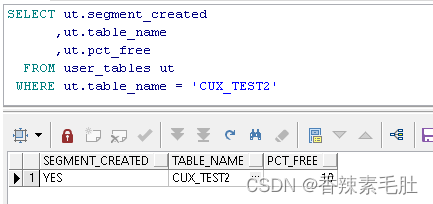
SELECT count(*) FROM sys.chained_rows WHERE table_name = 'CUX_TEST2'
下图显示我们创建的CUX_TEST2表PCT_FREE为10%,也就是只预留了10%空间作为保留空间,如果有频繁update(insert和delete会产生行迁移吗?为什么,如果全部都是非空的定长varchar,或者可以为空的number类型呢?),建议预留50%-70%空间作为保留空间
(我们在后面会接触到很多“手动管理”和“自动管理”,如果你不是资深DBA,大多数情况使用自动管理更好,段空间管理同样也是,所以我只能告诉你有这个手动控制,自动控制下我们能做的比较少,ORACLE会自动优化好一切,我们在自动控制下可以通过调参进行调优,所谓的调参,控制,你可以理解成“定制化”,深度定制的性能更好,但是不适于频繁变化的环境)
当delete很多行数据时,会将很多块清空,并标记数据文件位图为0,但是块逻辑上连续但物理上不连续,全表扫描的时候,仍然会扫描到这些空块,(如果是物理连续就可以直接找到非空的块,然后往下进行扫描了),举个极端的例子,你insert 100万条数据,然后delete from table,delete前后,查询count(*)(未建立唯一性索引情况下,count(*)会进行全表扫描),查询时间应该是一模一样的,这种现象叫“高水位”(高HWM,当然还有低HWM),高水位的核心就是全表扫描块时,有很多半满,或者空的块,但是你又不能跳过这些块不扫描。了解这个特性了,即使由于频繁删除导致高水位现象,在索引读取的时候并不会有性能的减慢,而至于count(*)这种全表扫描,只要合理维护唯一性索引(唯一性索引不允许为空,所以每个节点都有索引条目)或者维护合理的函数索引(不return null),也能进行优化。当然没有上述操作,你也可以手动进行段压缩,类似碎片整理,回收空间。
小结一下
使用alter table shrink能减少由于update导致的行迁移的索引性能问题,也能减少由于delete导致产生大量空块的全表扫描性能问题,现在我们实战一下
- 压缩lob段
我们的CUX_TEST2表字段B没有数据,对应的LOB段进行了两次段扩展,尝试把LOB段压缩一下
ALTER TABLE APPS.CUX_TEST2 MODIFY LOB(B) (SHRINK SPACE CASCADE);
虽然这个语法是官方给出的,但是没有什么效果,只能手动移动段空间
我们先查询一下当前LOB段的执行情况
SELECT de.file_id
,ddf.file_name
,ddf.bytes / 1024 / 1024 "File size (MB)"
,block_id first_block
,block_id + de.blocks - 1 last_block
,segment_name
FROM dba_extents de
,dba_data_files ddf
WHERE de.tablespace_name = 'APPS_DATA_TABLESPACE'
AND de.file_id = ddf.file_id
and segment_name='SYS_LOB0000101534C00002$$'

然后执行LOB段移动
alter table PPS.CUX_TEST2 move lob(B) store as( tablespace APPS_DATA_TABLESPACE);

现在扩展的前两区段已经被收缩掉了,查询表user_segments也能得出同样的效果
(我执行这个语句特别卡,不知道是不是因为在同一个表空间进行收缩的原因)
- 压缩表段,处理高水位,也能处理行迁移
先写入数据
BEGIN
FOR i IN 1 .. 100000
LOOP
INSERT INTO cux_test2 (a) VALUES (1);
END LOOP;
COMMIT;
END;
然后删除数据
Delete from cux_test2;
收集统计信息然后查询块使用情况
BEGIN
dbms_stats.gather_table_stats(ownname => 'APPS'
,tabname => 'CUX_TEST2'
,estimate_percent => dbms_stats.auto_sample_size
,method_opt => 'FOR ALL COLUMNS SIZE AUTO');
END;
SELECT a.owner
,a.table_name
,b.blocks "所有块"
,a.blocks "已用块"
,a.empty_blocks "空块"
,(b.blocks - a.empty_blocks - 1)
FROM dba_tables a
,dba_segments b
WHERE a.table_name = b.segment_name
AND a.owner = b.owner
AND a.blocks <> (b.blocks - a.empty_blocks - 1)
AND a.table_name = 'CUX_TEST2'
ORDER BY a.empty_blocks DESC
如果所有块远远大于已用块,说明发生了高水位现象
查询区段扩展情况

扩展了16个段,使用user_extend表可以查看具体扩展状态,如下

现在delete表之后进行段压缩
delete from cux_test2;
启用表行移动(副作用见链接http://www.dba-oracle.com/t_enable_row_movement.htm,建议压缩完毕之后禁用掉,如果使用ROWID进行查询可能不准确,因为后续操作会更新ROWID指向新的块)
查看表是否启动行移动

alter table APPS.CUX_TEST2 enable row movement;
压缩表段
alter table APPS.CUX_TEST2 shrink space cascade;
这里指定cascade关键词表示同时压缩索引,如果只压缩段不移动高水位的话,需要指定关键词compact
然后查询区段使用情况(不压缩段的话,即使delete 然后commit,仍然不会主动回收空间)

只有初始区段了。(段和区段是两个东西,区段是连续的块,我上面说的可能没有注明是段还是区段,记住segment表是段,extend表是区段)
压缩段不仅能处理高水位现象,也能处理行迁移带来的性能问题,那么
- 重建索引也能解决行迁移问题吗?
- 一个块是8K,如果一行数据本来就有9K,第一次写入的时候,在一个块中放不下,带来的性能问题是什么,如何去优化?
更多关于如何降低高水位的处理方式可以参考链接
http://www.dba-oracle.com/t_lower_table_high_water_mark.htm
总结:
存储结构除了数据文件,我们还会接触到临时文件(比如临时表空间不足的问题),用于排序的和用于回滚的undo文件以及trace文件,闪回文件,控制文件,重做日志文件redo(由于重做日志过小导致日志频繁切换,切换日志时整个系统相当于被“挂起”)。。可以按关键词去搜索都是什么东西。我们学习了dba_data_files表,segment表,extend表,分别对应表空间数据文件,段,区段。(有没有块表?可以自行搜索)用这些表就能去分析上面提到的所有问题。下一次我们从内存入手,分析内存体系结构和对应的调优策略。
-
相关阅读:
【javaSE】 枚举与枚举的使用
含文档+PPT+源码等]精品基于PHP实现的计算机学院师生招聘系统[包运行成功]计算机PHP毕业设计项目源码
OutlinePass色差问题
content向background发送消息的异步消息返回
「JVS低代码开发平台」关于逻辑引擎的触发讲解
TensorFlow开发者认证通过心得
Python字符串切片(s[::-1])巧解回文字符串判定
目标检测YOLO实战应用案例100讲-基于深度卷积网络的无人机 图像目标检测(续)
LogTAD:无监督跨系统日志异常域检测
2023年优化算法之之霸王龙优化算法(TROA),原理公式详解,附matlab代码
- 原文地址:https://blog.csdn.net/qq_34153210/article/details/133787210