-
深度学习_2_数据处理

import os是一个Python的内置模块,用于与操作系统进行交互。通过导入os模块,你可以使用其中提供的函数和方法来执行各种与操作系统相关的任务。import os os.makedirs(os.path.join('..', 'date'), exist_ok=True)##将创建一个名为date的文件夹,位于当前目录的上一级目录中- 1
- 2
- 3

代码:import os os.makedirs(os.path.join('..', 'date'), exist_ok=True)##将创建一个名为date的文件夹,位于当前目录的上一级目录中 data_file = os.path.join('..', 'date', 'house_tiny.csv')##路径名 with open(data_file, 'w') as f: ##第一个参数是文件路径(在此处为 data_file),第二个参数 'w' 表示以写入模式打开文件。如果文件不存在,它将被创建;如果文件已存在,它将被覆盖。 f.write("NumRooms,Alley,Price\n") f.write("NA,Pave,127500\n") f.write("2,NA,127500\n") f.write("NA,NA,127500\n")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

import os import pandas as pd import numpy as np os.makedirs(os.path.join('..', 'date'), exist_ok=True)##将创建一个名为date的文件夹,位于当前目录的上一级目录中 data_file = os.path.join('..', 'date', 'house_tiny.csv')##路径名 # with open(data_file, 'w') as f: # ##第一个参数是文件路径(在此处为 data_file),第二个参数 'w' 表示以写入模式打开文件。如果文件不存在,它将被创建;如果文件已存在,它将被覆盖。 # f.write("NumRooms,Alley,Price\n") # f.write("NA,Pave,127500\n") # f.write("2,NA,127500\n") # f.write("NA,NA,127500\n") data = pd.read_csv(data_file) print(data) inputs, outputs = data.iloc[:,0:2], data.iloc[:, 2]#inputs所有行前两列,out所有行的第三列 # inputs = inputs.fillna(inputs.mean().astype(float)) numeric_columns = inputs.select_dtypes(include=[np.number]).columns # 选择数值型的列 inputs[numeric_columns] = inputs[numeric_columns].fillna(inputs[numeric_columns].mean()) # 对数值型列进行填充 print(inputs)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

include=[np.number] 参数指定了要选择的数据类型为数值型(即包括整数和浮点数)
np.number 是 numpy 库中定义的数值类型的父类,它包括 int、float 和 complex 等类型
.columns 属性用于获取筛选出来的数值型列的列名。它会返回一个包含列名的列表,存储在变量 numeric_columns 中。uts[numeric_columns] 是将数据框 inputs 中的数值型列(由变量 numeric_columns 确定)赋值给数据框 uts 中相应的列。
.fillna(inputs[numeric_columns].mean()) 是对所选的数值型列进行填充操作。在这里使用了 .mean() 方法来计算每个数值型列的均值,并将缺失值用均值进行填充。数据填充,已存在数据的均值

将pave和NaN变成0或1
pd.get_dummies() 函数将分类变量转换为虚拟变量(哑变量)后的结果。其中包含了三列:NumRooms、Alley_Pave 和 Alley_nan。
NumRooms 列是一个数值型列,表示房间数量。
Alley_Pave 列是一个虚拟变量列,用于表示巷道类型是否为 “Pave”,即铺设路面。
Alley_nan 列是一个虚拟变量列,用于表示巷道类型是否为缺失值。
可以看出:
第一行数据中,房间数量为 3.0,巷道类型为 “Pave”(True),而不是缺失值(False)。
第二行数据中,房间数量为 2.0,巷道类型不是 “Pave”(False),而是缺失值(True)。
第三行数据中,房间数量为 4.0,巷道类型不是 “Pave”(False),而是缺失值(True)。
第四行数据中,房间数量为 3.0,巷道类型不是 “Pave”(False),而是缺失值(True)。
这种转换可以方便地将分类变量表示为虚拟变量,以便在机器学习等任务中使用。代码:
inputs = pd.get_dummies(inputs, dummy_na = True, dtype= int) print(inputs)- 1
- 2
- 3

代码:
x, y = torch.tensor(inputs.values), torch.tensor(outputs.values)##将csv文件转变成一个张量 print(x) print(y)- 1
- 2
- 3

至此整个CSV文件就化为了一个张量

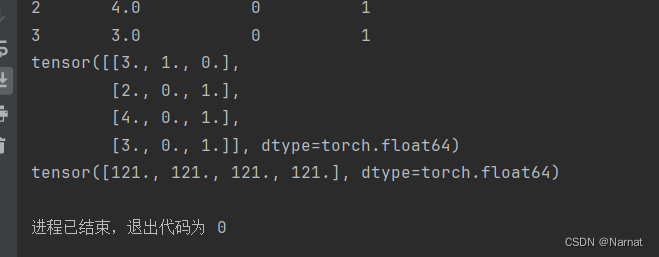
完整代码:import torch import os import pandas as pd import numpy as np os.makedirs(os.path.join('..', 'date'), exist_ok=True)##将创建一个名为date的文件夹,位于当前目录的上一级目录中 data_file = os.path.join('..', 'date', 'house_tiny.csv')##路径名 # with open(data_file, 'w') as f: # ##第一个参数是文件路径(在此处为 data_file),第二个参数 'w' 表示以写入模式打开文件。如果文件不存在,它将被创建;如果文件已存在,它将被覆盖。 # f.write("NumRooms,Alley,Price\n") # f.write("NA,Pave,127500\n") # f.write("2,NA,127500\n") # f.write("NA,NA,127500\n") data = pd.read_csv(data_file) print(data) inputs, outputs = data.iloc[:,0:2], data.iloc[:, 2]#inputs所有行前两列,out所有行的第三列 # inputs = inputs.fillna(inputs.mean().astype(float)) numeric_columns = inputs.select_dtypes(include=[np.number]).columns # 选择数值型的列 inputs[numeric_columns] = inputs[numeric_columns].fillna(inputs[numeric_columns].mean()) # 对数值型列进行填充 print(inputs) inputs = pd.get_dummies(inputs, dummy_na = True, dtype= int) print(inputs) #所有缺失的值变成了值那么就可以转换成张量 x, y = torch.tensor(inputs.values), torch.tensor(outputs.values)##将csv文件转变成一个张量 print(x) print(y)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
-
相关阅读:
区块链:一文了解区块链,在生活中的应用,代码实现,图导,区块链智能合约
软件设计师_数据结构与算法基础_学习笔记
DcatAdmin使用模版文件时模板标签不生效
【实战技能】单片机bootloader的CANFD,I2C,SPI和串口方式更新APP视频教程(2022-08-01)
使用oss对象存储服务的两种方式
跨境资讯站
计算机视觉与模式识别实验2-2 SIFT特征提取与匹配
如何给win11安装安卓应用
[nlp] pointwise,pairwise,listwise
助力数据中心双碳发展,存储如何变得越来越绿?
- 原文地址:https://blog.csdn.net/xyint/article/details/133778019
