-
【ElasticSearch】基于Docker 部署 ElasticSearch 和 Kibana,使用 Kibana 操作索引库,以及实现对文档的增删改查
文章目录
前言
Elasticsearch 和 Kibana 是强大的工具,用于构建实时搜索和数据可视化解决方案。Elasticsearch 是一个分布式、高性能的搜索引擎,可以用于存储和检索各种类型的数据,从文本文档到地理空间数据。Kibana 则是 Elasticsearch 的可视化工具,用于实时分析和可视化大规模数据集。
在本文中,将探讨如何使用 Docker 进行快速部署 Elasticsearch 和 Kibana,搭建一个强大的搜索和分析平台。我们将从基础开始,逐步介绍如何配置和管理这两个工具,以满足不同应用场景的需求。随后,将重点关注使用 Kibana 操作索引库的各种任务,包括创建、获取、修改和删除索引。这些任务对于数据管理和搜索引擎的构建至关重要,将帮助您更好地组织和利用数据。
通过阅读本文,希望能够帮助我们掌握 Elasticsearch 和 Kibana 的核心概念,具备构建强大搜索引擎和可视化工具的能力,以及解决中文分词和文档管理方面的专业知识。
一、使用 Docker 部署 ElasticSearch 和 Kibana
因为需要使用 Docker 部署 ElasticSearch 和 Kibana ,并且它们相互之间需要进行网络通信,所有首先创建一个虚拟网络,然后在运行容器的时候,加入这个网络即可。
docker network create es-net- 1
1.1 部署 ElasticSearch
- 获取 ElasticSearch 镜像:
首先我们需要从 DockerHub 中拉取 ElasticSearch 镜像:
DockerHup 地址:https://hub.docker.com/_/elasticsearch。
docker pull elasticsearch- 1
注意,ElasticSearch 的镜像体积比较大,如果能找到镜像的
tar包的话,最好使用tar包加载。此时我使用的是7.12.1版本的镜像:
使用命令加载这个
tar包:docker load -i es.tar- 1
- 运行 ElasticSearch 容器
运行 Docker 命令,部署单点的 ElasticSearch 服务:
docker run -d \ --name es \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network es-net \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:7.12.1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
上述 Docker 命令是为了运行 Elasticsearch 容器。下面是对命令的解释:
-
docker run -d: 这部分表示在后台运行容器。 -
--name es: 为容器指定一个名字,这里是 “es”。 -
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m": 设置 Java 虚拟机的参数,包括初始堆内存大小 (-Xms) 和最大堆内存大小 (-Xmx),这里都设置为 512MB。 -
-e "discovery.type=single-node": 设置 Elasticsearch 的节点发现机制为单节点,因为在这个配置中只有一个 Elasticsearch 实例。 -
-v es-data:/usr/share/elasticsearch/data: 将容器内 Elasticsearch 的数据目录挂载到宿主机的名为 “es-data” 的卷上,以便数据持久化。 -
-v es-plugins:/usr/share/elasticsearch/plugins: 类似上面,将容器内 Elasticsearch 的插件目录挂载到宿主机的名为 “es-plugins” 的卷上。 -
--privileged: 赋予容器一些特权,可能会有一些安全风险,需要慎用。 -
--network es-net: 将容器连接到名为 “es-net” 的网络上,目的是为了与其他容器进行通信。 -
-p 9200:9200 -p 9300:9300: 将容器内部的端口映射到宿主机上,这里分别是 Elasticsearch 的 HTTP REST API 端口(9200)和节点间通信的端口(9300)。 -
elasticsearch:7.12.1: 指定要运行的 Docker 镜像的名称和版本号,这里是 Elasticsearch 7.12.1 版本。
这个命令配置了 ElasticSearch 的运行参数、数据卷、网络等,使其能够在后台运行,并且可以通过指定的端口访问 Elasticsearch 的 API。
当运行完这个命令之后,我们可以在浏览器中访问
宿主机IP:9200,即可看到 ElasticSearch 的响应结果: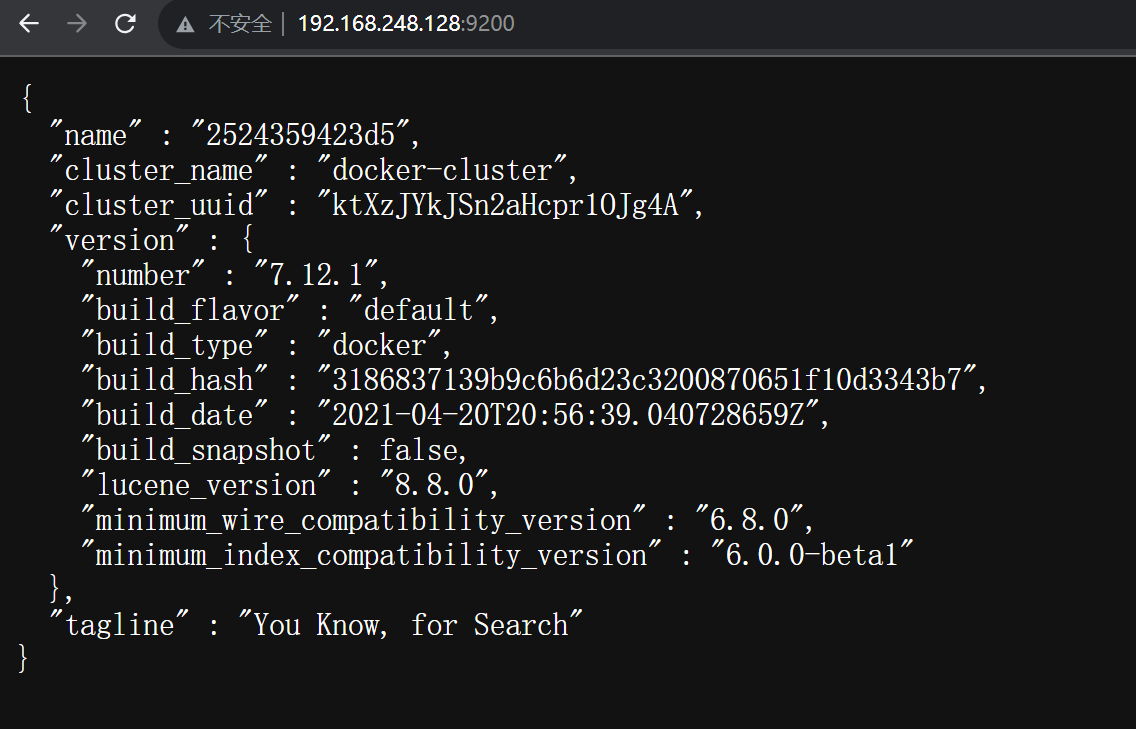
1.2 部署 Kibana
- 获取 Kibana 镜像
Kibana 是 Elastic 官方提供的一个 ElasticSearch 的可视化界面,通过这个界面可以更好地对 ElasticSearch 进行操作。
想要使用 Docker 部署 Kibana,首先同样需要从 DockerHub 中获取镜像:
DockerHub:https://hub.docker.com/_/kibana。
docker pull kibana- 1
同样的,Kibana 镜像的大小也超过了一个 G,因此如果能找到
tar的话,尽量使用load获取镜像:
docker load -i kibana- 1
- 运行 Kibana 容器
使用 Docker 命令运行 Kibana 容器:
docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://es:9200 \ --network=es-net \ -p 5601:5601 \ kibana:7.12.1- 1
- 2
- 3
- 4
- 5
- 6
这 Docker 命令是为了运行 Kibana 容器,它与 Elasticsearch 一同组成了 ELK(Elasticsearch, Logstash, Kibana)技术栈的一部分。下面是对命令各个部分的解释:
-
docker run -d: 在后台运行容器。 -
--name kibana: 为容器指定一个名字,这里是 “kibana”。 -
-e ELASTICSEARCH_HOSTS=http://es:9200: 设置 Kibana 运行时连接的 Elasticsearch 节点的地址,这里指定了 Elasticsearch 服务的地址为http://es:9200,其中 “es” 是 Elasticsearch 服务的容器名,而不是具体的 IP 地址。这是因为在--network=es-net中指定了容器连接到 “es-net” 网络,容器名会被解析为相应的 IP 地址。 -
--network=es-net: 将容器连接到名为 “es-net” 的网络上,确保 Kibana 能够与 Elasticsearch 容器进行通信。 -
-p 5601:5601: 将容器内部的 5601 端口映射到宿主机上,允许通过宿主机的 5601 端口访问 Kibana 的 Web 界面。 -
kibana:7.12.1: 指定要运行的 Docker 镜像的名称和版本号,这里是 Kibana 7.12.1 版本。
这个命令会在启动 Kibana 的同时连接到 Elasticsearch 服务,并映射 Kibana 的 Web 界面端口到宿主机,以便通过浏览器访问 Kibana 的用户界面进行 Elasticsearch 数据的可视化和管理。
当运行了这个命令之后,可以在浏览器中访问
宿主机IP:5601,然后就会进入 Kibana 的可视化界面:
1.3 利用 Kibana 演示 Elasticsearch 分词效果
在 Kibana 的可视化界面中,提供了一个 DevTools,在这个界面中我们就可以来编写 DSL 命令来操作 ElasticSearch,并且对 DSL 语句有提示和自动补全功能。
1. 打开 Kibana DevTools
首先,在 Kibana 的界面中找到左侧导航栏中的 “DevTools”,点击进入 DevTools 页面。

2. 编写分词演示 DSL 命令
在 DevTools 中,我们可以直接编写 DSL(Domain Specific Language,领域特定语言)命令来与 Elasticsearch 进行交互。以下是一个简单的演示,我们将使用 analyze API 来查看文本在分词阶段的效果。
什么是 DSL?
领域特定语言(Domain-Specific Language,DSL)是一种专注于解决特定问题领域的编程语言。与通用编程语言(如Java、Python)不同,DSL 被设计用来解决某一领域的具体问题,通常具有更高的表达能力和更简洁的语法。例如,现在使用了
standard分析器,它是 Elasticsearch 默认的分析器之一。要分析的文本是 “Elasticsearch is a powerful search engine.”。POST _analyze { "analyzer": "standard", "text": "Elasticsearch is a powerful search engine." }- 1
- 2
- 3
- 4
- 5
点击三角符号向 ElasticSearch 服务发送 HTTP 请求:

- 查看分词效果

上述结果显示了文本被分解成了多个词条(tokens),每个词条都有其在文本中的起始和结束位置。这样的分析对于搜索引擎来说是关键的,因为它决定了搜索时如何匹配文本。另外,Elasticsearch 支持多种分析器,如:
simple、whitespace、english等,每个分析器有其自己的特性。选择不同的分词器,分词所得的结果也会有所不同。二、解决中文分词的问题
2.1 默认分词器对中文分词的问题
在 Elasticsearch 中,默认的分词器在处理中文文本时可能会遇到一些问题,无法很好地将中文文本切分成有意义的词条。
例如下面的例子:
POST _analyze { "analyzer": "standard", "text": "Elasticsearch 是一个强大的搜索引擎。" }- 1
- 2
- 3
- 4
- 5
使用上面的 DSL 语句得到的分词结果为:

此时发现,对于中文的分词是一个字就被分成了一个词条,要解决这个问题可以使用 IK 分词器。2.2 引入 IK 分词器
当需要处理中文分词使,一般都会使用 IK 分词器。
项目下载地址: https://github.com/medcl/elasticsearch-analysis-ik。
为 ElasticSearch 引入 IK 分词器有两种方法:
1. 在线按照 IK 插件
按照的步骤和命令如下:
a)进入 ElasticSearch 容器内部
docker exec -it elasticsearch /bin/bash- 1
b)在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip- 1
c)退出 ElasticSearch 容器
exit- 1
d)重启 ElasticSearch 容器
docker restart elasticsearch- 1
2. 离线按照 IK 插件
a)查看数据卷目录
安装插件需要知道 ElasticSearch 的
plugins目录位置,我们中运行 ES 容器的时候实现了数据卷的挂载,因此需要查看 ES 容器的数据卷目录,通过下面命令查看:docker volume inspect es-plugins- 1

b)进入挂载目录,然后之间将下载好的 IK 插件解压重命名后放到这个挂载目录下


c)重启 ES 容器
docker restart es- 1
通过命令
docker logs -f es查看 ES 容器的启动日志,就可以发现已经成功加载了 IK 分词器:

2.3 IK 分词器的两种分词模式
IK 分词器是一款专为中文文本设计的分词器,在 Elasticsearch 中包含两种主要的分词模式:
ik_smart和ik_max_word。这两种模式在分词的细粒度上有所不同,适用于不同的应用场景。下面演示两种模式的区别:
a)
ik_smart模式DSL 语句:
POST _analyze { "analyzer": "ik_smart", "text": "Elasticsearch 是一个强大的搜索引擎。" }- 1
- 2
- 3
- 4
- 5
分词结果:

在ik_smart模式下,IK 分词器会进行最少切分,尽量保留专有名称和词组,以提高整体的可读性。b)
ik_max_word模式DSL 语句:
POST _analyze { "analyzer": "ik_max_word", "text": "Elasticsearch 是一个强大的搜索引擎。" }- 1
- 2
- 3
- 4
- 5
分词结果:

在ik_max_word模式下,IK 分词器会进行最细粒度的切分,尽量将文本拆分成单个词语,包括专有名称的切分。例如,对于 “搜索引擎”来说还进一步细分成了:“搜索”、“索引”、“引擎”。2.4 IK 分词器存在的问题
尽管 IK 分词器可以针对中文进行分词,但是随着互联网的不断发展,越来越多的网络用语和新的词汇在不断的产生,例如下面的例子:
POST _analyze { "analyzer": "ik_smart", "text": "鸡你太美,鸡哥,坤坤,奥利给,啦啦啦,么么么,哒哒哒" }- 1
- 2
- 3
- 4
- 5
此时对于上述词汇的分词结果为:

通过这个结果可以发现,IK 分词器并不能对新的网络用语进行分词,并且一些语气词也需要参与分词。2.5 IK 分词器拓展词库和停用词条
要解决上面使用 IK 分词器存在的问题可以对词典进行拓展和停用一些不必要或者敏感的词汇。
拓展词库:
要拓展 IK 分词器的词库,只需要修改 IK 分词器目录中的
config目录下的IkAnalyzer.cfg.xml文件:DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置comment> <entry key="ext_dict">ext.dicentry> properties>- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后在名为
ext.dic的文件中,添加想要拓展的词语即可:
停用词条:
要禁用某些不需要参与分词或者某些敏感词条,也是需要修改 IK 分词器目录中的
config目录中的IkAnalyzer.cfg.xml文件:<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">stopword.dic</entry> </properties>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
然后在名为
stopword.dic的文件中,添加想要停用的词语即可:

配置完成,重启 ES 容器,再次运行刚才的 DSL 语句:
POST _analyze { "analyzer": "ik_smart", "text": "鸡你太美,鸡哥,坤坤,奥利给,啦啦啦,么么么,哒哒哒" }- 1
- 2
- 3
- 4
- 5
此时的运行结果:

至此,就成功为 IK 分词器拓展和停用了词条。三、使用 Kibana 操作索引库
三、使用 Kibana 操作索引库
3.1 Mapping 属性
在使用 Kibana 操作索引库之前,了解索引的 mapping 属性是非常重要的。Mapping 是对索引库中文档的结构和字段的约束,它定义了文档中每个字段的数据类型、分词器等属性。以下是一些常见的 mapping 属性:
1.
type字段数据类型-
字符串类型:
text:用于存储可分词的文本,通常用于全文搜索。keyword:精确匹配的关键字,不分词,常用于过滤、聚合等场景。
-
数值类型:
long,integer,short,byte,double,float:用于存储数值。
-
布尔类型:
boolean:存储布尔值。
-
日期类型:
date:存储日期和时间。
-
对象类型:
object:存储复杂结构的对象。
2.
index是否创建索引- 默认为
true,表示创建索引。可以设置为false,表示不创建索引,该字段不可搜索。
3.
analyzer使用的分词器- 定义字段使用的分词器,影响搜索和分词行为。
4.
properties子字段- 如果字段是对象类型,可以定义子字段的 mapping。
示例:
PUT /my_index { "mappings": { "properties": { "title": { "type": "text", "analyzer": "standard" }, "price": { "type": "double" }, "is_available": { "type": "boolean" }, "created_at": { "type": "date" }, "category": { "type": "keyword" }, "details": { "type": "object", "properties": { "description": { "type": "text" }, "manufacturer": { "type": "keyword" } } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
上述示例定义了一个索引的 mapping,包含了不同类型的字段以及它们的属性。理解 mapping 对于在 Kibana 中正确操作索引非常重要,它影响了索引中文档的结构和 Elasticsearch 的行为。
3.2 创建和获取索引
在 Elasticsearch 中,创建和获取索引是操作索引库的基本步骤之一。下面是如何在 Kibana 中执行 DSL 代码来创建和获取索引的详细说明:
- 创建索引
DSL 代码:
PUT /demo { "mappings": { "properties": { "info": { "type": "text", "analyzer": "ik_smart" }, "email":{ "type": "keyword", "index": false }, "name":{ "properties": { "firstName":{ "type":"keyword" }, "lastName":{ "type":"keyword" } } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
说明:
- 使用
PUT请求创建一个名为demo的索引库。 - 在
mappings中定义了不同字段的属性,如info使用了中文分词器ik_smart。 email字段设置了index为false,表示不对该字段创建索引,该字段不可搜索。name字段是一个对象类型,包含firstName和lastName两个子字段。
执行结果:
在 Kibana 的 DevTools 中执行上述代码,会成功创建名为
demo的索引库。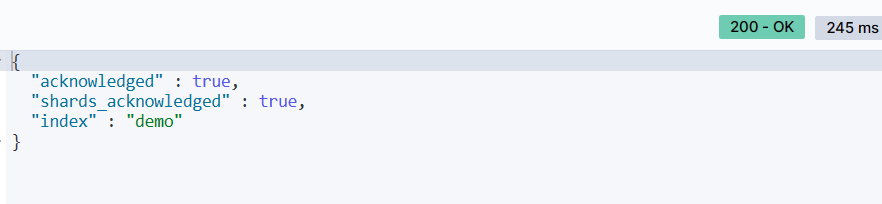
- 获取索引
DSL 代码:
GET /索引名- 1
说明:
- 使用
GET请求获取名为demo的索引库的信息。
执行结果:
在 Kibana 的 DevTools 中执行上述代码,会获取刚刚创建的
demo索引的信息。通过以上步骤,可以成功创建索引并获取索引的信息。在实际应用中,创建和管理索引是构建 Elasticsearch 数据结构的基础,对于数据的存储和检索具有重要作用。
3.3 修改索引库
在 Elasticsearch 中,一旦索引库和其对应的 mapping 创建后,mapping 一般无法直接修改。但是,我们可以通过添加新的字段的方式来间接修改索引库。下面是具体的操作步骤:
DSL 代码:
PUT /demo/_mapping { "properties": { "age": { "type": "integer" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
说明:
- 使用
PUT请求修改demo索引库的 mapping。 - 在
properties中定义了一个新的字段age,数据类型为integer。
执行结果:
在 Kibana 的 DevTools 中执行上述代码,成功为
demo索引库添加了一个新的字段age。
通过这种方式,我们可以对索引库进行修改,添加新的字段,以满足数据结构的演进和变化需求。需要注意的是,对于已经存在的文档,新添加的字段默认是
null或者空值,具体行为取决于字段的数据类型。3.4 删除索引库
在 Elasticsearch 中,如果需要删除一个索引库,可以使用
DELETE请求。以下是删除demo索引库的操作步骤:DSL 代码:
DELETE /demo- 1
执行结果:
在 Kibana 的 DevTools 中执行上述代码,成功删除了名为
demo的索引库。
注意:
- 删除索引库是一个慎重的操作,会删除索引库中的所有数据和 mapping。
- 如果尝试获取已删除的索引,将会得到 404 错误。

通过删除索引库,可以清空数据和结构,适用于重新创建索引或者不再需要的索引的情况。
四、使用 Kibana 实现对文档的增删改查
4.1 新增文档
在 Elasticsearch 中,新增文档是将数据存储到索引库中的过程。以下是在 Kibana DevTools 中使用 DSL 语法新增文档的详细说明:
DSL 代码:
POST /demo/_doc/1 { "info": "五虎上将之一", "email": "zy@demo.cn", "name": { "firstName": "云", "lastName": "赵" }, "age": 18 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
说明:
- 使用
POST请求将文档新增到demo索引库中。 _doc表示文档类型,1是文档的唯一标识符。- 文档内容包括字段
info、email、name和age。
执行结果:
在 Kibana 的 DevTools 中执行上述代码,成功新增了一个文档到
demo索引库中。
通过新增文档,可以将数据灵活地存储到 Elasticsearch 中,以便后续的检索和分析。
4.2 获取和删除文档
1. 获取文档
语法:
GET /索引库名/_doc/文档id- 1
例如,获取刚才新增的文档:
GET /demo/_doc/1- 1
执行结果:

2. 删除文档
删除文档使用的方法是
DELETE,DSL 语法如下:DELETE /索引库名/_doc/文档id- 1
例如,删除刚才新增的文档:
DELETE /demo/_doc/1- 1
文档删除成功后,Elasticsearch 会返回一个包含删除信息的 JSON 响应。通过上述操作,我们可以灵活地对文档进行获取和删除,适用于不同的数据管理需求。
4.3 修改文档:全量修改和增量修改
在 Elasticsearch 中,对文档的修改主要分为全量修改和增量修改两种方式。
1. 全量修改
全量修改使用的方法是
PUT,它会删除旧文档并添加新文档。全量修改的语法如下:PUT /索引库名/_doc/文档id { "字段1": "值1", "字段2": "值2", // ... 省略 }- 1
- 2
- 3
- 4
- 5
- 6
例如,对刚才新增的文档进行全量修改:
PUT /demo/_doc/1 { "info": "五虎上将之一", "email": "ZhaoYun@demo.cn", "name": { "firstName": "云", "lastName": "赵" }, "age": 18 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
执行结果如下:

实际上,全量修改相当于删除原有的文档内容,然后进行新增操作。因此,此处
PUT的作用也相当于新增。** 2. 增量修改**
增量修改使用的方法是
POST,它可以修改指定字段的值。增量修改的语法如下:POST /索引库名/_update/文档id { "doc": { "字段名": "新的值", } }- 1
- 2
- 3
- 4
- 5
- 6
例如,对刚才新增的文档进行增量修改:
POST /demo/_update/1 { "doc":{ "email":"ZYun@demo.cn" } }- 1
- 2
- 3
- 4
- 5
- 6
执行结果如下:

通过上述操作,我们可以实现对文档内容的全量修改和增量修改,具体选择哪种方式取决于业务需求和数据管理的策略。全量修改适用于需要更新整个文档内容的场景,而增量修改则更灵活,可以选择性地更新部分字段。
4.4 文档的版本号
什么是文档的版本号:
在 Elasticsearch 中,每个文档都有一个版本号(version),用于标识文档的变更历史。当对文档进行修改时,版本号会随之递增,每次修改都会生成一个新的版本。
为什么需要文档的版本号:
文档的版本号在并发写入和更新的场景中起到了重要的作用。当多个客户端同时尝试修改同一文档时,通过版本号可以确保写入的顺序和一致性。在分布式系统中,版本号还用于控制数据的一致性和冲突解决。
例如,对于 id 为 1 的文档:
1. 新增时,
_version为 1
2. 第一次修改后,
_version变为 23. 再次修改后,
_version变为 3
通过上面的操作,可以发现一个规律。那就是每修改一次文档,那么该文档的版本号就会加 1。
版本号的作用:
版本号在处理并发写入、更新和冲突解决时非常重要。通过版本号,Elasticsearch 可以确保在并发修改的情况下,数据的一致性和正确性。当多个客户端尝试修改同一文档时,只有最新的版本会被接受,避免了数据的混乱和冲突。
版本号的使用让 Elasticsearch 成为一个强大的分布式数据库,能够处理大规模的并发写入和更新操作。
4.5 动态 Mapping 映射
在 Elasticsearch 中,我们有时会遇到需要向索引中添加新字段的情况。这就涉及到了动态 Mapping 映射的概念。动态 Mapping 是 Elasticsearch 在插入文档时自动识别字段类型并进行映射的机制。
让我们通过一个具体的例子来说明动态 Mapping 的工作原理。假设我们向索引中插入以下文档:
PUT /demo/_doc/2 { "info": "五虎上将之一", "email": "zf@demo.cn", "name": { "firstName": "飞", "lastName": "张" }, "age": 35, "score": [98.5, 98.9, 97.9, 99.2], "isMarried": false, "birthday": "1988-05-20", "city": "上海" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
执行结果:

这个文档中包含了索引中之前未见过的字段,例如
score、isMarried、birthday和city。然而,Elasticsearch 并没有报错,而是成功插入了文档。这是因为 Elasticsearch 会自动进行动态 Mapping 映射。动态 Mapping 映射的规则如下:
JSON类型 Elasticsearch类型 字符串 日期格式字符串:date 类型;普通字符串:text 类型,并添加 keyword 类型子字段 布尔值 boolean 类型 浮点数 float 类型 整数 long 类型 对象嵌套 object 类型,并添加 properties 数组 由数组中的第一个非空类型决定 空值 将被忽略 通过动态 Mapping,Elasticsearch 能够灵活地处理文档中新增的字段,为我们提供了方便和便利。这种功能使得 Elasticsearch 能够智能地适应不断变化的数据结构,为索引的管理提供了灵活性。
-
相关阅读:
PCB layout 小功率板子减小干扰方法
相关性分析中如何用标准差判断差异大小
VR全景如何应用在房产行业,VR看房有哪些优势
MongoDB增改删操作
【springboot】1、快速入门
pip-script.py‘ is not present Verifying transaction: failed
算法体系-12 第 十二 二叉树的基本算法
tensorflow数据统计
EmguCV-C#版本Opencv图像识别和处理
[附源码]java毕业设计疫情防控期间人员档案追寻系统设计与实现论文
- 原文地址:https://blog.csdn.net/qq_61635026/article/details/133645483
