-
串联起深度学习的整体,以及其他领域
一、测度空间, 相空间,观察到的实体,实体内部不同要素
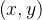 ,以及要素之间的关系
,以及要素之间的关系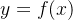
二、实体对人类的重要性不言而喻
1、从模型拟合(收敛)数据关系出发:
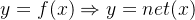
2、f从简单的一层和两层连接开始,发展;
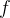 被表示成
被表示成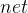
3、如何判断收敛:
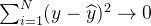 ,即目标函数
,即目标函数4、如何界定任务:
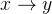 ,
,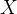 表示什么?
表示什么?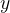 表示什么?,例如y表示房价、经济增长率、工资收入、地心引力大小、引力波的幅度等等
表示什么?,例如y表示房价、经济增长率、工资收入、地心引力大小、引力波的幅度等等5、如何定义模型
,也就是如何定义网络,比如CNN、RNN、Transformer等等6、如何收集数据:
 ,样本数据,例如:人的需求指向
,样本数据,例如:人的需求指向7、如何训练:
a、计算预测
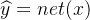 ,
,b、计算损失
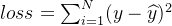 ,
,c、计算梯度
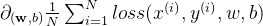 ,
,d、更新参数
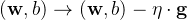
8、梯度是什么?不同层的梯度?怎么计算梯度?
计算梯度:1)链式法则;2)自动微分
9、优化算法是什么?即
 的设定方式,固定的,还是变化的,怎么变化。有哪些?
的设定方式,固定的,还是变化的,怎么变化。有哪些?10、小批量数据训练,批量指\(\)
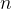 大小:
大小: 
11、前向传播:计算
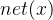
12、后向传播,计算梯度,更新参数
13、
包括什么?1)、网络架构 2)、参数14、参数初始化?方法
15、如何添加层?扩大net的规模?
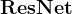 ,以
,以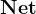 为对象,做
为对象,做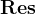 操作。
操作。16、更新参数
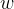 的方式:
的方式: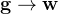 ,梯度
,梯度17、模型有哪些?怎么发展的?如何设计
18、生成式人工智能?
19、概率
20、过拟合指什么?
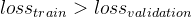
21、什么是泛化?
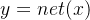 ,实际中(或者条件发生变化的时候) 的结果好使不?
,实际中(或者条件发生变化的时候) 的结果好使不?22、怎么判断泛化能力?取决于验证的数据集,看
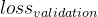 的大小
的大小23、参数与模型之间的关系?模型 = 网络架构 + 参数
24、什么叫大模型?参数规模超过10,0000,0000,100亿或更大,GPT的参数规模13700亿。
25、大模型的挑战?收敛并有效,好用
26、现实中训练模型所面临的挑战?梯度消失、梯度爆炸、过拟合、欠拟合、数据分布
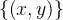 发生变化、计算量大(计算性能不够)
发生变化、计算量大(计算性能不够)27、数据预处理,raw data:
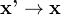
28、结果:想要的,
29、串联其他领域的知识,例如:信息论领域的,对目标函数或代价函数的设定,数据生成的概率,特定的模式等等,
串联的方式有:
;挑选的方式,依据,设定预期方向(符合大多数人的预期方式)30、串联数学,
,真实的关系,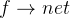 , 用
, 用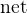 表示的
表示的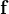
31、目标在时间的展开,序列数据:
, 对目标或对象的表示与处理32、目标在空间的展开,图像数据,又称为二维像素网格:
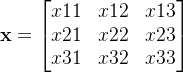
33、
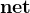 的变化:
的变化: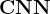 、
、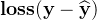 或其他
或其他34、
的展开:内部构造,不同的层,块,参数35、变与不变:
1)不变:
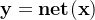 ,
,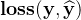 ,(注意,与的区别),
,(注意,与的区别),2)可变:
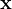 , ,
, , 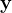 ,
,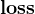 都可变。还有:
都可变。还有: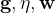 等
等3)过程:
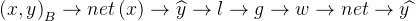
36、
的形式1: 注意力汇聚函数注意力机制下的神经网络
,注意力汇聚函数模型(网络),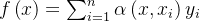
变化形式:
替换 , 分别取名查询query,键key,值value,\(f\left ( \textbf{q},(\textbf{k}_{1},\textbf{v}_{1}) ,...(\textbf{k}_{m},\textbf{v}_{m})\right )=\sum_{i=1}^{m}\alpha \left ( \textbf{q},\textbf{k}_{i} \right )\textbf{v}_{i}\)
37、
的形式2:循环神经网络 RNN\(x_{t}\sim P(x_{t}|x_{t-1},...,x_{1})\)
整个序列的估计值,通过概率形式来获得
\(P(x_{1},...,x_{T})\)
上述概率可以写成
\(P(x_{1},...,x_{T})=\prod_{t=1}^{T}P(x_{t}|x_{t-1},...x_{1})\)
38、
的形式3:多层感知机MLP38、
的形式4:编码器,将输入序列转换(编码)成上下文变量:\(\left ( x_{1},... x_{T} \right )\rightarrow \textbf{c}\)
具体实现过程:\(\textbf{h}_{t}=f\left ( \textbf{x}_{t},\textbf{h}_{t-1} \right )\), \(\textbf{c}=f\left ( \textbf{h}_{1},...,\textbf{h}_{T} \right )\)
变换成神经网络的实现:\(\textbf{h}_{t}=net_{1}\left ( \textbf{x}_{t},\textbf{h}_{t-1} \right )\),\(\textbf{c}=net_{2}\left ( \textbf{h}_{1},...,\textbf{h}_{T} \right )\)
\(net=net_{1}+net_{2}+...\)
外扩机制是神经网络最突出的特点(永远在进化)
39、\(\textbf{x}\)的变形1:序列;\(\textbf{x}\)的变形2:图像;\(\textbf{x}\)的变形3:信号;\(\textbf{x}\)的变形4:系统
40、
的变化形式:1)、理解1:与人们想要的高度之间的差距,也可以理解为理想与现实之间的距离:
\(\left \| \textbf{Reality}-\textbf{Expectation} \right \|\),
理想也会调整,人们对现实的努力,达到自己相对理想的状态
41、
的变化形式:1)、人们想要的一些东西,比如财富、价值、良好的(用户)体验、幸福感等等
42、\(\textbf{g}\)的变化形式
43、\(\textbf{w}\)的变化,暂退法和权重衰减,
43、权重衰减是改变
,\(L+\frac{\lambda }{2}\left \| \textbf{w} \right \|^{2}\)44、优化算法:
凸函数在深度学习中的应用:虽然深度学习问题通常不是凸优化问题,但凸函数理论和凸优化算法仍然在深度学习中发挥重要作用。例如,在深度学习中,很多损失函数(
)(如均方误差损失)是凸函数,优化这些损失函数可以采用凸优化算法,如随机梯度下降(SGD)。45、凸优化与目标函数
\(loss\left ( y-\widehat{y} \right )=loss\left ( y-net_{w,b}\left ( x \right ) \right )\),
其中,\(loss\)也是设定好的,
和为已知(设定好的),的架构是设定好的,\(w,b\)是需要搜索的点,凸优化就是通过搜索找到\(loss\)较小的点。\(loss\)是个函数,是个凸函数,所以与凸优化有关。函数中的未知是\(w,b\)。再看过程: \(\left ( x,y \right )_{B}\),输入的数据
\(net_{w_{1},b_{1}}\left ( x \right )\rightarrow\widehat{y_{1}}\rightarrow loss_{1}\rightarrow g\rightarrow net_{w_{2},b_{2}}\left ( x \right )\rightarrow \widehat{y_{2}}\rightarrow loss_{2}\)
整体结果需要:\(loss_{2}< loss_{1}\)
简单来说,深度学习就是在干上面的事情,挑战在于非常复杂的问题和庞大的真实数据集上,能够获得效果好的模型,模型也会非常大。参数量超过1000亿,1万亿,还能够收敛。
所有的工作,简单概括来看,要么与任务\(Task\)有关,与\(\left ( x,y \right )_{B}\)有关,或者与\(net,w,b\)有关,或者与\(loss\)有关,或者与\(g\)有关。整个深度学习也是围绕这些方面展开的,可以去对照落座。
46、多模态是指多个模态的数据,可以简单表示为:
\(\textbf{X}=\left \{ \mathbf{x}_{acoustic},\mathbf{x}_{image},\mathbf{x}_{text},\mathbf{x}_{electronic}...\right \}\),
完整数据集:\(\left \{ \left (\textbf{ X},\textbf{y} \right )_{1},\left (\textbf{ X},\textbf{y} \right )_{2},... \right \}_{N}\)
多模态任务指想要的
,所需要的关系,转变为大模型,是的一种估计,可以记为\(\widehat{\textbf{f}}\):\(\mathbf{y}=\textbf{f}(\textbf{X})\Rightarrow \mathbf{y}=\widehat{\textbf{f}}(\textbf{X})\Rightarrow\mathbf{y}=\textbf{net}(\textbf{X})\).
\(\widehat{\textbf{f}}=\textbf{net}\),
大数据、大算力也是围绕此展开的,
大数据是指\(\left (\textbf{ X},\textbf{y} \right )_{N}\), \(N>10,0000,0000,0000\), 10万亿。
大算力围绕大的参数规模展开,计算梯度需要,GPT-4的参数规模达到了惊人的1.8万亿。
具体例证:
1、GPT-4的训练数据规模达到了惊人的13万亿token,这是何为token?token可以理解为语言中的基本单元,例如单词、词组或句子等。训练数据量的增加意味着模型能够基于更多的实例来学习语言规律,从而提高其性能。
47、多头注意力融合了来自多个注意力汇聚的不同知识,这些知识的不同来源于,查询、键和值的不同的表示子空间。
Multi-head attention combines knowledge of the same attention pooling via different representation subspaces of queries, keys, and values.
-
相关阅读:
docker下安装fastdfs,并使用java操作api
基于Ray的分布式版本的决策树与随机森林
面试公司ETL工程师(实习生)——笔试面试题(SQL)
03 RocketMQ - Broker 源码分析
RabbitMQ:发布确认高级
手把手写深度学习(16):用CILP预训练模型搭建图文检索系统/以图搜图/关键词检索系统
国产时序数据库IotDB安装、与SpringBoot集成
【数据科学赛】2023年亚太眼科学会大数据竞赛 #$15000 #阿里天池 #分类
Django系列:Django开发环境配置与第一个Django项目
字节跳动八进八出,offer到手,发现项目不重要算法才最重要
- 原文地址:https://blog.csdn.net/xw555666/article/details/133696204