-
我们要不要使用 ORM?
本次主要来聊聊关于 ORM 的内容,欢迎评论交流,欢迎批评指正
分别从如下 4 个方面来展开
- ORM 他是个啥?
- 为什么要用 ORM?
- ORM 给我们带来了哪些问题?
- 如何去考虑是否要使用 ORM?
ORM 他是个啥?
一提到 ORM 很多同学知道他是跟数据库相关的一个内容,但是并不清楚他到底是这个啥,自己需不需要,到底怎么玩?
实际上 ORM 就那么一回事,从这三个字母就可以看到
O:Object
R:Relational
M:Mapping
对象关系映射,即关系型数据库和我们的实体业务对象来进行一个映射,对与我们使用 ORM 对象来说,就直接去使用其对应的各种方法即达到自动持久化的目的,无需关注具体的 sql 细节
因为 ORM 已经为你隐藏了关于 sql 的部分,让不熟悉 sql 的 xdm 也可以很好的上手
只要你知道如何使用函数,使用对象里面的方法到底你的数据操作目的即可
为什么要用 ORM?
为什么要使用 ORM 呢?难道出了一个新的东西,我们就一定要用吗?自然是要知道他的好,我们才会去使用
结论先放在前面,使用 ORM
- 可以减少我们重复的写垃圾代码,可以提高我们的工作效率,降低开发成本
- 访问数据的时候,可以使用抽象的方式,用起来非常简洁
- 以及 orm 带来的各种奇淫巧技
举一个 gorm 的例子
在 GO 中我们访问 mysql 关系型数据库,数据库中提前先创建好了数据库,数据表,以及 3 条记录

GO 中有给我们提供对应的库
import "database/sql" import _ "github.com/go-sql-driver/mysql"- 1
- 2
我们可以使用 sql.Open() 连接 mysql 数据库
func Connect() (*sql.DB, error) { db, err := sql.Open("mysql", "root:123456@/test_gorm") if err != nil { return nil, err } return db, nil }- 1
- 2
- 3
- 4
- 5
- 6
- 7
获取到 db 句柄之后,我们可以通过这样的方式,输入 sql 语句来查询数据
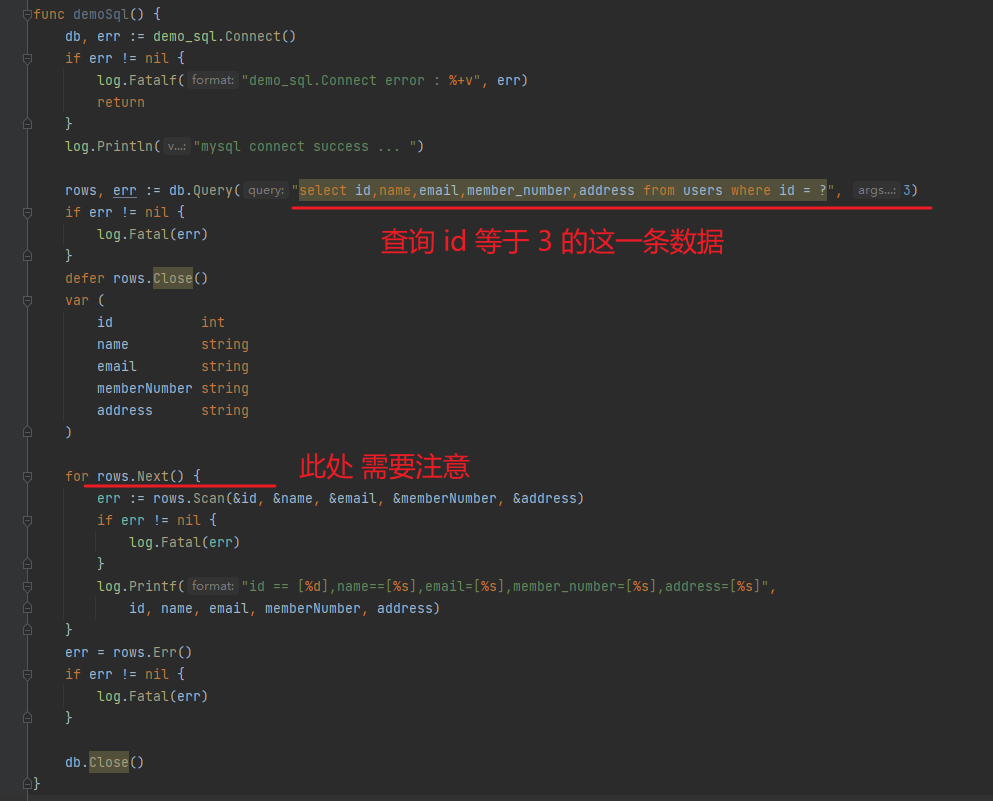
可以发现,本次的查询语句是
select id,name,email,member_number,address from users where id = ?,我们再一条数据一条数据的读取出来(此处需要注意使用读取 rows.Next() 的时候,需要读取完毕之后,关闭句柄,否则会资源泄漏)
那么如果我们换成别的查询语句,或者其他增删改的语句呢?
回顾一下以前各种疯狂写重复代码 sql 代码的情况,流程是一样的,代码结构也是类似的,写着差不多的代码,过着差不多的人生吗?
甚至这一块的代码很多或许都是复制粘贴,然后改改 sql,改改响应结果
这也太无聊和重复了,咱们还真的是个码农了?别人搬砖,我们搬代码?
这不,这个时候,我们就可以使用 ORM 来帮助我们提高生产效率, 减少我们的低价值重复劳动,可以留更多的时间来进行思考和优化
这样,我们使用 gorm 的话,连接数据我们就可以这样来写
func Connect(user, pwd, ip, port string) (*gorm.DB, error) { db, err := gorm.Open("mysql", fmt.Sprintf("%s:%s@tcp(%s:%s)/test_gorm?charset=utf8&parseTime=True&loc=Local", user, pwd, ip, port)) if err != nil { return nil, err } return db, nil }- 1
- 2
- 3
- 4
- 5
- 6
- 7
上述的查询就会变成这样的

有没有发现,对应的地方,使用 orm 的方式,对于咱们来说,其实就是需要查询一条数据,完全都不需要去关心 sql ,只需要按照对象去应用方法就可以查询我们想要的数据

看到这里,有没有初步觉得 ORM 还是很香的,至少咱们写数据持久化的时候,就不需要写那么多重复代码了,使用 ORM 方便高效
gorm 简述和提醒
看了上述例子是否会有这些疑问,
- Import 包的时候为什么导入了又不用?
- 为什么连接数据库的时候需要带上
mysql字符串?
import _ "github.com/go-sql-driver/mysql"- 1
首先,一个库如果不用的话,那当然是没有必要导入的,导入了正式因为需要使用
可以看到 mysql 包中的 init 函数,实际上就是做一个注册,用一个有效的名字,对一个这一个数据库引擎
func init() { sql.Register("mysql", &MySQLDriver{}) }- 1
- 2
- 3
Register 实现如下

可以看到在
sql包里面有一个全局map,里把存放了mysql这个名字的driver
再来查看 gorm.Open() 的实现就一目了然了
gorm.Open 中调用了 sql.Open , sql.Open 中去从全局的 map
driver中获取mysql字符串对应的引擎gorm.Open

sql.Open

这一块就到这里,如果需要系统的学习和了解 gorm,可以从这里进入:
- https://www.topgoer.cn/docs/gorm/gorm-1c54sbcda16o6
- https://gorm.io/
- gorm.Open 为什么要带上
charset=utf8&parseTime=True&loc=Local
其中
charset是表示字符编码parseTime为 True ,表示处理数据的时候,会去解析时间loc=Local表示入库的时候,使用的是本地时区以及 gorm 有没有其他的坑?
实际上在应用 gorm 的时候,还是会有很多坑等着咱们,此处先给大家避避坑
与其说是坑,实际上还是自己去应用一个技术的时候对其不够了解,认知没有对齐导致的
- 创建数据表的坑
使用 gorm 创建数据表的时候,会先要定义一个基本的数据模型,表示数据表中有哪些字段,其中 gorm 默认给我们提供了一些默认 model,根据实际情况使用即可
type Model struct { ID uint `gorm:"primary_key"` CreatedAt time.Time UpdatedAt time.Time DeletedAt *time.Time `sql:"index"` }- 1
- 2
- 3
- 4
- 5
- 6
例如我们子定义的表结构是这样的:

创建出来的表格名为
users,我们可以使用如下语句禁用表名复数,或者自定义一个表名都是可以的db.SingularTable(true)- 1
- 解析时间的坑
上述使用 gorm.Open() 连接数据库的时候,咱们指定了
parseTime=True,那么后续处理时间类型的数据就不会有问题,如果不指定的话,gorm 处理时间类型的数据会处理出错- 想当然的坑
ORM 固然用起来方便,不动 sql 的人用起来也很爽,但是一些基本的操作还是要注意的,否则会对性能影响非常大
例如,查询一批数据的时候获取会想当然的这样来写
// 伪代码,示意一波 userList:=[]int{1, 3, 5} user := dao.User{} for _,v := range userList { db.First(&user, v) }- 1
- 2
- 3
- 4
- 5
- 6
或许在写其他逻辑的时候这样写好像没啥问题,但是你要明白现在是操作数据库,怎么可以循环操作数据库呢?如果 demo 中的 userList 足够的大,那么结果可想而知
在 gorm 完全可以使用 where 的方式来达到我们的查询目的,还是需要我们理解了之后,灵活使用,不要生搬硬套,例如
users := make([]dao.User, 0) db.Where("id in (?)", []int{1, 2, 3}).Find(&users)- 1
- 2
ORM 给我们带来了哪些问题?
Xdm 闭着眼睛想一下,原来是直接就使用 sql 去操作数据库的,现在咱们通过了一层 gorm 对象,自然是会对我们的性能带来影响的,而且 ORM 是多层系统的
- ORM 里面需要去管理多个关联和映射,需要消耗资源
- 需要咱们学习新知识,增加学习成本
- 会产生依赖,长期不用 sql,慢慢的可能你就不会完整的 sql 了
- 稍不注意可能就会写出低性能的代码
- … 等等,欢迎补充
如何去考虑是否要使用 ORM?
那么我们知道了 ORM 的优劣,那么我们是否要去选择并使用它呢?
根据我们实际项目的需要来定,如果项目比较大,对性能要求较高,那么还是不要使用了
如果项目不大,并且有很多简单的,重复的,低效的数据操作,那么还是可以使用的,使用起来确实非常方便,方便到让你忘记 sql
总的来说,要还是不要,是个问题,如果是你,你会怎么选?
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力

技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
文中提到的技术点,感兴趣的可以查看这些文章:
- GO 语言 Web 开发实战一
可以进入地址进行体验和学习:https://xxetb.xet.tech/s/3lucCI
-
相关阅读:
【JavaScript高级】01-this的指向
【JavaEE初阶】 Callable 接口
Django AssertionError: .accepted_renderer not set on Response
【C语言函数调用详解】——传值调用&传址调用
虹科示波器 | 汽车免拆检修 | 2012 款上汽大众帕萨特车 发动机偶尔无法起动
字节跳动或将强制实行1075工作制,加班需申请
目标检测YOLO实战应用案例100讲-基于深度学习的可见光遥感图像目标检测(下)
[Vite]import.meta.glob批量引入svg图片
微信CRM系统在旅游行业的应用
io_uring之liburing库安装
- 原文地址:https://blog.csdn.net/m0_37322399/article/details/133608226