-
SpringBoot整合数据库连接
JDBC
1、SQL准备
- DROP TABLE IF EXISTS `t_book`;
- CREATE TABLE `t_book` (
- `book_id` int(11) NOT NULL,
- `book_name` varchar(255) DEFAULT NULL,
- `price` int(11) DEFAULT NULL,
- `stock` int(11) DEFAULT NULL
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- /*Data for the table `t_book` */
- insert into `t_book`(`book_id`,`book_name`,`price`,`stock`) values (1,'仙逆',30,100),(2,'诛仙',20,100);
- /*Table structure for table `t_user` */
- DROP TABLE IF EXISTS `t_user`;
- CREATE TABLE `t_user` (
- `user_id` int(11) NOT NULL,
- `username` varchar(100) DEFAULT NULL,
- `balance` int(11) DEFAULT NULL
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- /*Data for the table `t_user` */
- insert into `t_user`(`user_id`,`username`,`balance`) values (1,'zhangsan',500);
java Bean
- import lombok.AllArgsConstructor;
- import lombok.Data;
- import lombok.NoArgsConstructor;
- @Data
- @NoArgsConstructor
- @AllArgsConstructor
- public class User {
- private Integer userId;
- private String username;
- private Integer balance;
- }
1
2、数据库驱动
JDBC(Java DataBase Connectivity),即Java数据库连接。简而言之,就是通过Java语言来操作数据库。
JDBC是sun公司提供一套用于数据库操作的接口.
java程序员只需要面向这套接口编程即可。不同的数据库厂商(
MySQL、Oracle、DB2、SQLServer 等),需要用实现类去实现这套接口,再把这些实现类打包(数据驱动jar包),并提供数据驱动jar包给我们使用。
驱动:就是一个jar包,里面包含了JDBC的实现类
想要通过JDBC连接并操作Mysql数据库,我们需要下载一个Mysql数据库驱动jar包。所以我们下面都能看到引入了这个依赖
- <dependency>
- <groupId>mysqlgroupId>
- <artifactId>mysql-connector-javaartifactId>
- dependency>
JDBC API主要位于JDK中的
java.sql包中(之后扩展的内容位于javax.sql包中),主要包括:- DriverManager:负责加载各种不同驱动程序(Driver),并根据不同的请求,向调用者返回相应的数据库连接(Connection)。
- Driver:驱动程序,会将自身加载到DriverManager中去,并处理相应的请求并返回相应的数据库连接(Connection)。
- Connection:数据库连接,负责与进行数据库间通讯,SQL执行以及事务处理都是在某个特定Connection环境中进行的。可以产生用以执行SQL的Statement。
- Statement:用以执行SQL查询和更新(针对静态SQL语句和单次执行)。PreparedStatement:用以执行包含动态参数的SQL查询和更新(在服务器端编译,允许重复执行以提高效率)。
- CallableStatement:用以调用数据库中的存储过程。
- SQLException:代表在数据库连接的建立和关闭和SQL语句的执行过程中发生了例外情况(即错误)。
3、JDBC编程六步
第一步:注册驱动 作用:告诉Java程序,即将要连接的是哪个数据库
通过
DriverManager.registerDriver(driver)注册驱动- String className = "com.mysql.cj.jdbc.Driver";
- //1. 注册驱动
- Class clazz = Class.forName(className);
- Driver driver = (Driver) clazz.newInstance();
- DriverManager.registerDriver(driver);
第二步:获取连接 表示JVM的进程和数据库进程之间的通道打开了,这属于进程之间的通信使用完之后一定要关闭通道
- 通过
DriverManager.getConnection(url,user,pwd)获取连接 Connection连接对象不能随意创建,最后使用完要手动关闭
- //2. 获取连接
- String url = "jdbc:mysql://127.0.0.1:3306/spring-boot-demo?serverTimezone=UTC";
- String user = "root";
- String password = "root";
- Connection conn = DriverManager.getConnection(url, user, password);
第三步:获取数据库操作对象 专门执行sql语句的对象
- 一个数据库连接对象可以创建多个数据库操作对象
- 通过
conn.createStatement()获取数据库操作对象
- //3.获取数据库操作对象
- Statement stmt = conn.createStatement();
第四步:执行SQL语句 DQL DML…
- JDBC编写SQL语句不需要以分号结尾
- 数据库管理系统会将编写好的SQL语句编译并执行
- //4.执行查询 SQL语句,返回结果集
- String username = "zhangsan";
- String sql = "select * from t_user where username= '" + username + "'";
- ResultSet rs = stmt.executeQuery(sql);
第五步:处理查询结果集 只有当第四步执行的是select语句的时候,才有这第五步处理查询结果集。如果不是的话,可以直接释放资源
根据查询结果集中字段的下标获取
- //5.通过索引来遍历读取结果集
- while (rs.next()) {
- int userId = rs.getInt(1);
- String name = rs.getString(2);
- String balance = rs.getString(3);
- System.out.println("userId:" + userId + " 姓名:" + name + " 余额:" + balance);
- }
第六步:释放资源 使用完资源之后一定要关闭资源。Java和数据库属于进程间的通信,开启之后一定要关闭一个Connection可以创建多个Statement,一个Statement可以得出多个ResultSet,所以先关闭ResultSet,再关闭Statement,最后关闭Connection
- //5.资源的释放,讲道理要写到finally语句块中
- rs.close();
- stmt.close();
- conn.close();
完整代码
- @SpringBootTest
- public class TestA {
- @Test
- public void test2() throws Exception {
- String className = "com.mysql.cj.jdbc.Driver";
- //1. 注册驱动
- Class clazz = Class.forName(className);
- Driver driver = (Driver) clazz.newInstance();
- DriverManager.registerDriver(driver);
- //2. 获取连接
- String url = "jdbc:mysql://127.0.0.1:3306/spring-boot-demo?serverTimezone=UTC";
- String user = "root";
- String password = "root";
- Connection conn = DriverManager.getConnection(url, user, password);
- //3.获取数据库操作对象
- Statement stmt = conn.createStatement();
- //4.执行查询 SQL语句,返回结果集
- String username = "zhangsan";
- String sql = "select * from t_user where username= '" + username + "'";
- ResultSet rs = stmt.executeQuery(sql);
- //5.通过索引来遍历读取结果集
- while (rs.next()) {
- int userId = rs.getInt(1);
- String name = rs.getString(2);
- String balance = rs.getString(3);
- System.out.println("userId:" + userId + " 姓名:" + name + " 余额:" + balance);
- }
- //5.资源的释放,讲道理要写到finally语句块中
- rs.close();
- stmt.close();
- conn.close();
- }
- }
4、PreparedStatement
SQL注入实例
定义SQL语句框架的时候,使用PreparedStatement数据库操作对象,这个是预编译对象,先将SQL语句框架进行了编译,
然后给参数?动态赋值。Statement 和 PreparedStatement 对比
PreparedStatement可以防止 SQL 注入,执行效率高
SQL语句对于Statement来说是:编译一次执行一次
SQL语句对于PreparedStatement来说,是编译一次执行N次
原因:数据库管理系统(DBMS)厂商实现了JDBC接口,DBMS将编译后的SQL语句保存在DBMS中,由于DBMS中有很多编译好的SQL语句,这时通过同一个PreparedStatement对象进行赋值,便会找到其对应的PreparedStatement对象,从而实现其参数的赋值,即:一次编译多次执行。
PreparedStatement是类型安全的,编译期可以检查传入参数类型
5、JDBC事务
JDBC默认情况下,事务是自动提交的:即在JDBC中执行一条DML语句就执行了一次事务- 将事务的自动提交,修改为手动提交即可避免自动提交
- 在事务执行的过程中,任何一步出现异常都要进行回滚
开启事务(设置手动提交事务):
conn.setAutoCommit(false);事务提交:
conn.commit();事务回滚:
conn.rollback();- Connection con = null;
- try {
- con = getConnection();
- con.setAutoCommit(false);
- /*
- * do what you want here.
- */
- con.commit();
- } catch (Throwable e) {
- if (con != null) {
- try {
- con.rollback();// 设定setAutoCommit(false)若没有在catch中进行Connection的rollBack操作,操作的表就会被锁住,造成数据库死锁。虽然在执行con.close()的时候会释放锁,但若应用服务器使用了数据库连接池,连接不会被断开,从而不会放锁
- } catch (SQLException e1) {
- e1.printStackTrace();
- }
- }
- throw new RuntimeException(e);
- } finally {
- if (con != null) {
- try {
- con.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
- }
SpringBoot整合JdbcTemplate
1、启动器依赖
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-jdbcartifactId>
- dependency>
- <dependency>
- <groupId>mysqlgroupId>
- <artifactId>mysql-connector-javaartifactId>
- dependency>
2、yml配置数据源
数据源DataSource有什么作用? 通过DataSource可以获取数据库连接Connection
- spring:
- datasource:
- url: jdbc:mysql://127.0.0.1:3306/spring-boot-demo?useUnicode=true&characterEncoding=UTF-8&useSSL=false&autoReconnect=true&failOverReadOnly=false&serverTimezone=GMT%2B8
- username: root
- password: root
- driver-class-name: com.mysql.cj.jdbc.Driver
3、启动时数据库初始化
- spring:
- datasource:
- url: jdbc:mysql://127.0.0.1:3306/spring-boot-demo?useUnicode=true&characterEncoding=UTF-8&useSSL=false&autoReconnect=true&failOverReadOnly=false&serverTimezone=GMT%2B8
- username: root
- password: root
- driver-class-name: com.mysql.cj.jdbc.Driver
- initialization-mode: always
- continue-on-error: true
- schema:
- - "classpath:db/schema.sql"
- data:
- - "classpath:db/data.sql"
默认加载schema.sql与data.sql。
spring.datasource.schme
schema为表初始化语句,spring.datasource.data
data为数据初始化,
spring.datasource.initialization-mode 初始化模式(springboot2.0),其中有三个值,always为始终执行初始化,embedded只初始化内存数据库(默认值),如h2等,never为不执行初始化。
spring.datasource.continue-on-error: false 遇到语句错误时是否继续,若已经执行过某些语句,再执行可能会报错,可以忽略,不会影响程序启动
4、JdbcTemplate的使用
定义一个UserDao操作 t_uer 表
- @Repository
- public class UserDao {
- @Autowired
- private JdbcTemplate jdbcTemplate;
- /**
- * 根据用户名获取用户
- *
- * @param uname 用户名
- * @return 对应的用户
- */
- public User selectByName(String uname) {
- String sql = "select * from t_user where username = ?";
- /**
- * sql是要执行的 SQL 查询。
- * rowMapper是一个回调,它将每行映射一个对象
- * args 是要绑定到查询的参数。
- */
- User user = jdbcTemplate.queryForObject(sql, new BeanPropertyRowMapper<>(User.class), uname);
- return user;
- }
- }
查一条数据为一个实体类对象
- @RunWith(SpringRunner.class)
- @SpringBootTest
- public class TestA {
- @Autowired
- UserDao userDao;
- @Test
- public void test1() {
- User user = userDao.selectByName("zhangsan");
- System.out.println(user);
- }
- }
结果

JdbcTemplate封装了许多SQL操作,具体可查阅官方文档JdbcTemplate (Spring Framework 6.0.12 API)
SpringBoot整合mybatis
1、依赖
不同版本的Spring Boot和MyBatis版本对应不一样,具体可查看官方文档:mybatis-spring-boot-autoconfigure – Introduction
mybatis-spring-boot-starter:
- <dependency>
- <groupId>org.mybatis.spring.bootgroupId>
- <artifactId>mybatis-spring-boot-starterartifactId>
- <version>2.1.4version>
- dependency>
- <dependency>
- <groupId>mysqlgroupId>
- <artifactId>mysql-connector-javaartifactId>
- dependency>
注意:有2种方式可以指定重新指定mysql的版本
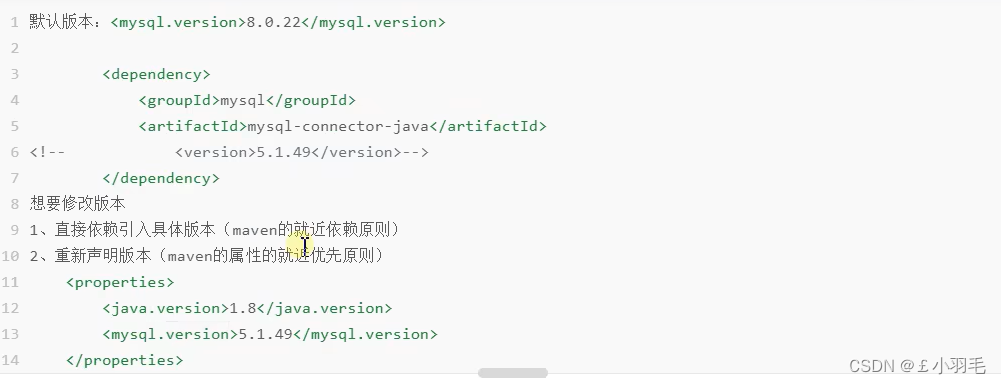
2、yml配置
- server:
- port: 8089 #tomcat端口号
- logging:
- level:
- com.atguigu.dao: debug # 配置日志
- spring:
- datasource:
- username: root
- password: 123456
- url: jdbc:mysql://127.0.0.1:3306/springboot?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai
- driver-class-name: com.mysql.cj.jdbc.Driver
- mybatis:
- type-aliases-package: com.atguigu.pojo
指定mybati sql映射文件位置


如数据库里这个字段是这样的user_id,实体类里是这样的userId。mybatis默认不开启驼峰命名规则。即默认情况下无法匹配。
mybatis默认不开启驼峰命名规则。即默认情况下无法匹配。
不用去指定全局配置文件mybatis-config.xml; 而使用mybatis.configuration去代替它。

3、@Mapper注解
mybatis接口要创建代理对象,原来是通过sqlSession.getMapper(UserMapper.class),现在加上@Mapper才行
告诉mybatis这是一个Mapper接口,来操作数据库
- @Mapper
- public interface AccountMapper{
- public Account getAcct(Long id);
- }
当然,每一个mapper接口都加的话太麻烦了,直接在启动类里做处理就好了
@MapperScan(basePackage=“”),扫描包,提供代理对象
- @SpringBootApplication
- @MapperScan(basePackages = "com.atguigu.dao")
- public class Application {
- public static void main(String[] args) {
- SpringApplication.run(Application.class,args);
- }
- }
在测试类 MybatisTest【一定要被启动类覆盖】
- @RunWith(SpringJUnit4ClassRunner.class) //指定Junit核心运行类
- @SpringBootTest //自动提供IOC容器
- public class MybatisTest {
- @Autowired
- private UserMapper userMapper ;
- @Test
- public void findAll() {
- List
users = userMapper.selectAll(); - System.out.println(users);
- }
- }

测试结果:因为没有重写toString
4、整合mybatis-plus
- <dependency>
- <groupId>com.baomidougroupId>
- <artifactId>mybatis-plus-boot-starterartifactId>
- <version>3.1.0version>
- dependency>
配置文件
- spring:
- datasource:
- url: jdbc:mysql://127.0.0.1:3306/spring-boot-demo?useUnicode=true&characterEncoding=UTF-8&useSSL=false&autoReconnect=true&failOverReadOnly=false&serverTimezone=GMT%2B8
- username: root
- password: root
- driver-class-name: com.mysql.cj.jdbc.Driver
- type: com.zaxxer.hikari.HikariDataSource
- initialization-mode: always
- continue-on-error: true
- schema:
- - "classpath:db/schema.sql"
- data:
- - "classpath:db/data.sql"
- hikari:
- minimum-idle: 5
- connection-test-query: SELECT 1 FROM DUAL
- maximum-pool-size: 20
- auto-commit: true
- idle-timeout: 30000
- pool-name: SpringBootDemoHikariCP
- max-lifetime: 60000
- connection-timeout: 30000
- logging:
- level:
- com.xkcoding: debug
- com.xkcoding.orm.mybatis.plus.mapper: trace
- mybatis-plus:
- mapper-locations: classpath:mappers/*.xml
- #实体扫描,多个package用逗号或者分号分隔
- typeAliasesPackage: com.xkcoding.orm.mybatis.plus.entity
- global-config:
- # 数据库相关配置
- db-config:
- #主键类型 AUTO:"数据库ID自增", INPUT:"用户输入ID",ID_WORKER:"全局唯一ID (数字类型唯一ID)", UUID:"全局唯一ID UUID";
- id-type: auto
- #字段策略 IGNORED:"忽略判断",NOT_NULL:"非 NULL 判断"),NOT_EMPTY:"非空判断"
- field-strategy: not_empty
- #驼峰下划线转换
- table-underline: true
- #是否开启大写命名,默认不开启
- #capital-mode: true
- #逻辑删除配置
- #logic-delete-value: 1
- #logic-not-delete-value: 0
- db-type: mysql
- #刷新mapper 调试神器
- refresh: true
- # 原生配置
- configuration:
- map-underscore-to-camel-case: true
- cache-enabled: true
mybatis-plus配置类
- @Configuration
- @MapperScan(basePackages = {"com.atguigu.mapper"})
- @EnableTransactionManagement
- public class MybatisPlusConfig {
- /**
- * 性能分析拦截器,不建议生产使用
- */
- @Bean
- public PerformanceInterceptor performanceInterceptor() {
- return new PerformanceInterceptor();
- }
- /**
- * 分页插件
- */
- @Bean
- public PaginationInterceptor paginationInterceptor() {
- return new PaginationInterceptor();
- }
- }
SpringBoot整合JPA
1、依赖
spring data JPA 对 hibernate做了封装,底是Hibernate
添加Spring Data JPA的起步依赖
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-data-jpaartifactId>
- dependency>
- <dependency>
- <groupId>mysqlgroupId>
- <artifactId>mysql-connector-javaartifactId>
- dependency>
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-testartifactId>
- dependency>
2、yml配置
在application.yml中配置数据库和jpa的相关属性
日志级别:
fatal error warn info debug 级别越低,信息越多- logging:
- level:
- com.atguigu.dao: debug # 配置日志
- server:
- port: 8089 #tomcat端口号
- spring:
- datasource:
- url: jdbc:mysql://127.0.0.1:3306/spring-boot-demo?useUnicode=true&characterEncoding=UTF-8&useSSL=false&autoReconnect=true&failOverReadOnly=false&serverTimezone=GMT%2B8
- username: root
- password: root
- driver-class-name: com.mysql.cj.jdbc.Driver
- jpa:
- database: mysql # 数据库类型
- show-sql: true
- generate-ddl: true #生成表结构
- hibernate:
- ddl-auto: update
- naming_strategy: org.hibernate.cfg.ImprovedNamingStrategy #表名字和字段名字的命名策略
spring.jpa.hibernate.ddl-auto的属性有以下几种参数:
create:每次加载hibernate会自动创建表,以后启动会覆盖之前的表,所以这个值基本不用,会导致的数据的丢失。
create-drop : 每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除,下一次启动会重新创建。
update:加载hibernate时根据实体类model创建数据库表,这是表名的依据是@Entity注解的值或者@Table注解的值,sessionFactory关闭表不会删除,且下一次启动会根据实体model更新结构或者有新的实体类会创建新的表。
validate:启动时验证表的结构,不会创建表。
none:启动时不做任何操作。
3、User实体类
很重要的一个类,会根据这个类在数据库中生成表
@Entity定义对象将会成为被JPA管理的实体,将映射到指定的数据库表。
@Table指定数据库的表名。
@Id定义属性为数据库的主键,一个实体里面必须有一个。
@GeneratedValue 设置主键自增@Column定义该属性对应数据库中的列名。
@Embeddable注释,表示此类可以被插入某个entity中
- import lombok.Data;
- import javax.persistence.*;
- @Entity
- @Table(name = "jpa_user")
- @Data
- @NoArgsConstructor
- public class User {
- @Id
- @GeneratedValue(strategy = GenerationType.IDENTITY)
- private Long id;
- @Column(name = "username")
- private String username;
- @Column(name = "password")
- private String password;
- @Column(name = "age")
- private Integer age;
- }
项目跑起来,让自动创建表jpa_user

4、UserDao
JpaRepository接口同时拥有了基本CRUD功能以及分页功能。当我们需要定义自己的
Repository接口的时候,我们可以直接继承JpaRepository,从而获得SpringBoot Data JPA为我们内置的多种基本数据操作方法- import org.springframework.data.jpa.repository.JpaRepository;
- import java.util.Optional;
- public interface JpaUserDao extends JpaRepository
- Optional
findByUsername(String username); - }
如内置方法:
S save(S entity); 保存一个实体Optional
findById(ID id); //根据id查询对应的实体 -----------
扩展:因为接⼝支持多继承
- public interface UserDao extends JpaRepository
{ - }
继承JpaRepository这个接口可以实现一些这个接口已经给我们提供好的方法对数据库进行查询。
JpaSpecificationExecutor接口的功能:动态查询。
- public interface JpaSpecificationExecutor
{ - Optional
findOne(@Nullable Specification var1) ; - List
findAll(@Nullable Specification var1) ; - Page
findAll(@Nullable Specification var1, Pageable var2) ; - List
findAll(@Nullable Specification var1, Sort var2) ; - long count(@Nullable Specification
var1) ; - }
Specification就是代表查询的条件,我们可以动态去拼接不同的查询条件,用调用这里的方法的形式来实现我们的查询,只需要把查询条件以参数的形式(Specification)传递过来就可以了。
- 实现Specification<查询对象的类型>接口(这里使用匿名内部类)
- 实现toPredicate方法,构造查询条件,toPredicate方法参数的两个参数
- @RunWith(SpringRunner.class)
- @SpringBootTest
- public class TestA {
- @Autowired
- JpaUserDao jpaUserDao;
- @Test
- public void test1() {
- User user = new User();
- user.setUsername("zhangsan");
- user.setPassword("123456");
- user.setAge(20);
- User user1 = jpaUserDao.save(user);
- System.out.println("保存成功后返回的userId=" + user1.getId());
- Optional
user2 = jpaUserDao.findById(user1.getId()); - System.out.println("查询得到user:" + user2.get());
- }
- }

SpringBoot事务管理器
1、准备工作
使用mybatis-plus
实体类
- @Data
- public class Book {
- private Integer bookId;
- private String bookName;
- private Integer price;
- private Integer stock;//库存
- }
- @Data
- public class User {
- private Integer userId;
- private String username;
- private Integer balance;
- }
mapper
- @Component
- public interface UserMapper extends BaseMapper
{ - }
- @Component
- public interface BookMapper extends BaseMapper
{ - }
service接口
- public interface UserService extends IService
{ - //更新用户余额
- boolean updateBalance(Integer bookId, Integer userId);
- }
- public interface BookService extends IService
{ - void buyBook(Integer bookId, Integer userId);
- }
service接口实现类
- @Service
- public class BookServiceImpl extends ServiceImpl
- @Override
- public void buyBook(Integer bookId, Integer userId) {
- //查询图书的价格
- Integer price = bookDao.getPriceByBookId(bookId);
- //更新图书的库存
- bookDao.updateStock(bookId);
- //更新用户的余额
- bookDao.updateBalance(userId, price);
- }
- }
1
- public interface UserService extends IService
{ - //更新用户余额
- boolean updateBalance(Integer bookId, Integer userId);
- }
2、开启事务的注解驱动
当然在之后的springboot项目中,就不这么麻烦了,直接在启动类上加
@EnableTransactionManagement

- 事务:针对连接对象,连接由数据源dataSource提供
- 原生的:connection连接对象来管理事务
开启后通过注解@Transactional所标识的方法或标识的类中所有的方法,都会被事务管理器处理事务
- @Target({ElementType.TYPE, ElementType.METHOD})
- public @interface Transactional {
- }
3、场景一:买书
如果实际的业务中,需要将一条数据同时存放到两张表中, 并且要求两张表中的数据同步,那么此时就需要使用事务管理机制,保证数据同步。如果出现错误情况,比如表一插入数据成功,表二插入数据失败,那么就回滚,终止数据持久化操作。
模拟场景:买书
模拟买书三步骤,需要进行事务管理
- 查询图书价格(t_book)
- 更新图书库存(t_book)
- 更新用户余额(t_user)
没有事务管理的情况
BookServiceImpl中的买书方法,注意此时buyBook()上没有加@Transactional。
- public interface BookService {
- void buyBook(Integer bookId, Integer userId);
- }
- @Override
- public void buyBook(Integer bookId, Integer userId) {
- //查询图书的价格
- Integer price = bookDao.getPriceByBookId(bookId);
- //更新图书的库存
- bookDao.updateStock(bookId);
- //更新用户的余额
- bookDao.updateBalance(userId, price);
- }
测试如下代码:
- @RunWith(SpringJUnit4ClassRunner.class)
- @ContextConfiguration("classpath:applicationContext.xml")
- public class BookControllerTest {
- @Autowired
- private BookController bookController;
- @Test
- public void test1(){
- bookController.buyBook(1,1);
- }
- }
报错是情理之中,

因为:从下面2表数据(测试方法执行前)可看得出,admin这个用户余额只有80,它买一本价格为100的《斗破苍穹》就会报错,因为表结构中余额是无符号整数。

那么由于我们没有事务管理,此时表中的数据就不对劲了
t_user中数据不会变化,因为执行这条sql的时候报错了嘛,但是t_book这个表里面的库存减一了,也就是“买书三步骤”中的第三步报错了,但是第二步依旧没回滚。
加入事务管理解决
以 @Transactional 注解为植入点的切点,这样才能知道@Transactional注解标注的方法需要被代理。
如何避免上面那种错呢,很简单就是加一个注解@Transactional,搞定!
- @Override
- @Transactional
- public void buyBook(Integer bookId, Integer userId) {
- //查询图书的价格
- Integer price = bookDao.getPriceByBookId(bookId);
- //更新图书的库存
- bookDao.updateStock(bookId);
- //更新用户的余额
- bookDao.updateBalance(userId, price);
- }
我们把t_book中的库存,改回为100,再执行一遍测试代码
bookController.buyBook(1,1);报错肯定是要报错的,

但是这时候,t_book表中的库存并没有改,说明事务回滚了!nice

在实际开发中好多都是业务逻辑出错导致的回滚:如库存不够和余额不够。
就拿卖书的例子来说,要是我们没有把金额设置为无符号整数,对数据库来说,整数也可以为负,从逻辑来说,金额不能为负,所以解决方案有2种:
- 1、从数据库方面来解决:无符号整数unsigned
- 2、从Java代码方面来解决:没有异常给造一个异常
4、事务属性
@Transactional就是用来定位连接点,可以标识在类或方法上。
@Transactional注解:通过该注解所标识的方法或类中所有的方法会被事务管理器处理事务
- @Transactional原理是aop 对调用的目标方法进行了扩展
- 1.方法调用前开启事务
- 2.方法调用时它对方法进行了try...catch,如果进入到catch中则回滚事务
- 3.如果try的最后一行代码能执行到则提交事务
@Transactional 事务的属性
事务的属性有 只读、超时时间、回滚策略、隔离级别、传播行为
- @Transactional(
- readOnly = false,
- timeout = 30,
- //noRollbackForClassName = "java.lang.ArithmeticException",
- noRollbackFor = ArithmeticException.class,
- isolation = Isolation.DEFAULT,
- propagation = Propagation.REQUIRES_NEW
- )
但是不要慌,事务的这些属性都有默认值
1、事务的只读
通过@Transactional注解的readOnly属性设置,默认值为false
若当前的事务设置为只读,则会在数据库层面去优化该操作,比如不加锁!
注意:只有事务中只有查询功能时,才可以设置事务的只读,即readOnly = true
若设置为只读的事务中有任何的增删改操作,则抛出异常:
java.sql.SQLException: Connection is read-only.2、事务的超时时间
通过@Transactional注解的timeout属性设置,默认值为-1,表示往死里等(单位秒)
因为事务针对连接来操作,如果连接一直处于阻塞,就会无限制等待下去
注意:若当前事务设置了事务的超时时间,但是在指定时间内没有执行完毕则抛出事务超时异常TransactionTimedOutException,并将事务强制回滚
我们可以让线程阻塞! TimeUnit.SECONDS.sleep(5);
- @Override
- @Transactional(
- timeout = 3
- )
- public void buyBook(Integer bookId, Integer userId) {
- try {
- //线程暂停5秒,可读性强
- TimeUnit.SECONDS.sleep(5);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- //查询图书的价格
- Integer price = bookDao.getPriceByBookId(bookId);
- //更新图书的库存
- bookDao.updateStock(bookId);
- //更新用户的余额
- bookDao.updateBalance(userId, price);
- }
运行结果,不出所料

3、事务的回滚策略
声明式事务 默认只针对运行时异常回滚,编译时异常不回滚。
-
运行时异常:不受检异常,没有强制要求try-catch,都会回滚。例如:ArrayOutOfIndex,OutofMemory,NullPointException
-
编译时异常:受检异常,必须处理,要么try-catch要么throws,都不回滚。例如:FileNotFoundException
通过@Transactional注解的rollbackFor、rollbackForClassName、noRollbackFor、noRollbackForClassName设置
rollbackFor和rollbackForClassName指定的异常必须回滚 ,一般不设置
noRollbackFor和noRollbackForClassName指定的异常不用回滚
rollbackFor和noRollbackFor通过异常的class对象设置
rollbackForClassName和noRollbackForClassName通过异常的全类名设置rollbackFo举例
rollbackFor 指定回滚的情况。spring默认是回滚RuntimeException或这error才回滚。当然自定义的RuntimeException异常类也是可以的。
如果希望spring能够回滚别类型的异常,那就需要使用rollbackFor去指定(当然如果是指定异常的子类,也同样会回滚)
@Transactional(rollbackFor=Exception.class)
----------------------------------
noRollbackFor举例
用80去买价格为50一本的《斗罗大陆》,是可以正常买成功的;
但是我们程序最后加了一个数学运算异常,那么按道理来说,会回滚事务。
但是加了noRollbackFor之后,再发生数学运算异常的时候,事务就不会回滚了。。
- @Override
- @Transactional(noRollbackFor = ArithmeticException.class)
- public void buyBook(Integer bookId, Integer userId) {
- //查询图书的价格
- Integer price = bookDao.getPriceByBookId(bookId);
- //更新图书的库存
- bookDao.updateStock(bookId);
- //更新用户的余额
- bookDao.updateBalance(userId, price);
- System.out.println(1/0);
- }
结果就是,发生了数学运算异常,但是事务没有回滚,数据库数据依旧发生了改变

4、事务的隔离级别
通过@Transactional注解的isolation设置事务的隔离级别,一般使用数据库默认的隔离级别.
隔离级别越高,数据一致性就越好,但并发性越弱。
- isolation = Isolation.DEFAULT;//表示使用数据库默认的隔离级别
- isolation = Isolation.READ_UNCOMMITTED;//表示读未提交
- isolation = Isolation.READ_COMMITTED;//表示读已提交
- isolation = Isolation.REPEATABLE_READ;//表示可重复读
- isolation = Isolation.SERIALIZABLE;//表示串行化
5、事务的传播行为
事务的传播:当A事务方法调用了B事务方法,A方法在执行时,就会将其本身的事务传播给B方法
B方法执行的过程中,使用A传播过来的事务,也可以使用其本身即B的事务更详细的可以参考:
22-05-13 西安 jdbc(03) 事务的ACID属性、并发问题、隔离级别;事务传播行为、本地事务_£小羽毛的博客-CSDN博客_jdbc事务 并发场景模拟:结账
创建CheckoutServiceImpl,这里我们有个很重要的事情,就是结账:checkout()
它是一个事务方法,它调用了BookServiceImpl的事务方法buyBook()
- 场景模拟:结账
- @Service
- public class CheckoutServiceImpl implements CheckoutService {
- @Autowired
- private BookService bookService;
- @Override
- @Transactional
- public void checkout(int[] bookIds, int userId) {
- for (int bookId : bookIds) {
- bookService.buyBook(bookId, userId);
- }
- }
- }
在默认情况下,即不改变事务的默认属性:

测试:修改用户的余额为120,目的为了让用户可以买第一本书,但是在买第二本的时候,会因为余额不够而报出异常。
bookController.checkout(new int[]{1,2},1);此时,观察数据库结果发现俩张表数据都无变化,当“有一本书不能买,那就一本书都买不了”
默认的事务传播属性就是,propagation = Propagation.REQUIRED
表示使用A方法传播到B中的事务,若B方法执行的过程中,只要有抛出异常,整个A方法都要回滚,这是默认
---------------------------------------
可以通过propagation属性设置事务的传播行为,现在,不用默认属性了。改为
propagation = Propagation.REQUIRES_NEW
表示在B方法执行中不使用A方法传播到B中的事务,而是开启一个新事务,即使用B本身的事务。
若B方法执行的过程中,只要有抛出异常,B事务方法回滚,A不会回滚,即不影响A中的其他事务的执行(如第二次买书失败不影响第一次买书成成功)修改代码,重新测试

继续用上面的测试代码测试,提醒一下,现在用户余额是120,他买的起第一本书,买不起第二本
bookController.checkout(new int[]{1,2},1);测试后,数据库数据发生了改变,也就是从以前的"有一本书不能买,那就一本书都买不了",变成了现在的“能买几本买几本”。

5、事务失效
数据库一次执行数据的单元(要么这个事务(执行的sql)都成功,要么都失败)
- service没有托管给spring
spring事务生效的前提是,service必须是一个bean对象- 方法不是public的
@Transactional只能用于public的方法上,否则会失效- 调用本类方法
调用该类自己的方法,而没有经过spring的代理类,默认只有在外部调用事务才会生效- 异常被吃
将异常try catch 没有throw出来。回滚异常没有,无法回滚- 异常类型错误
- spring默认只会回滚非检查异常和error异常
- 如果是抛出受检异常,需要在注解@Transactional加属性rollbackFor
- final修饰方法
因为spring事务是用动态代理实现,因此如果方法使用了final修饰,则代理类无法对目标方法进行重写,植入事务功能====================
spring的事务是声明式事务,而声明式事务的本质是SpringAOP,SpringAOP的本质是动态代理。事务要生效必须是代理对象在调用。
自调用问题
通过this调用同一个service中的方法,this是指service实现类对象本身,不是代理对象,就相当于方法中的代码粘到了大方法里面,相当于还是一个方法。(会导致事务失效)
- @Override
- @Transactional
- public void bigSave(SpuVo spuVo) {
- /// 1.保存spu相关
- // 1.1. 保存spu基本信息 spu_info
- Long spuId=saveSpu();
- // 1.2. 保存spu的描述信息 spu_info_desc
- this.saveSpuDesc(spuVo, spuId);
- //1.3、保存spu的基本属性
- this.saveSpuBaseAttrs(spuVo, spuId);
- // 2. 保存sku相关信息
- this.saveSkus(spuVo, spuId);
- //给mq中发送消息
- this.sendMessage(spuId);
- }
自调用问题-解决办法一
通过其他service对象(spuDescService)调用,这个service对象本质是动态代理对象

自调用问题-解决办法二
this.方法名()替换成this代理对象.方法名()即可。在类中获取代理对象分三个步骤:
-
导入aop的场景依赖:spring-boot-starter-aop
-
开启AspectJ的自动代理,同时要暴露代理对象:@EnableAspectJAutoProxy(exposeProxy=true)
-
获取代理对象:SpuInfoService proxy = (SpuInfoService) AopContext.currentProxy();
数据库连接池
1、数据库连接池
数据库连接池(connection pool)概念:本质上是个集合容器,里面存放着数据库的连接。并对外暴露数据库连接获取和返回方法。
- 外部使用者可通过 getConnection 方法获取连接
- 使用完毕后再通过 close 方法将连接返回
- 系统初始化时,创建一定数量的连接对象放入连接池。
- 当有需要时,从连接池中获取空闲的连接对象,对数据库进行操作
- 使用完毕后,将该连接对象归还至连接池,方便后续复用
数据库连接池的设计思想:
消除频繁创建对象和释放资源带来的延迟,提高系统性能
2、DataSource数据源
数据源使用 javax.sql.DataSource来表示,DataSource只是一个接口。数据库连接池就是 DataSource 的一个实现。习惯上也经常把 DataSource称为连接池
springboot中经常能看到这样的配置
- spring:
- datasource:
- url: jdbc:mysql://127.0.0.1:3306/spring-boot-demo?useUnicode=true&characterEncoding=UTF-8&useSSL=false&autoReconnect=true&failOverReadOnly=false&serverTimezone=GMT%2B8
- username: root
- password: root
- driver-class-name: com.mysql.cj.jdbc.Driver
实际上,如上配置,JDBC内核API的实现下,就已经可以实现对数据库的访问了,那么我们为什么还需要连接池呢?主要出于以下几个目的:
- 封装关于数据库访问的各种参数,实现统一管理
- 通过对数据库的连接池管理,节省开销并提高效率
3、Hikari 数据源
Springboot默认支持的4种数据源,定义在
org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration 分别是:
- org.apache.tomcat.jdbc.pool.DataSource
- com.zaxxer.hikari.HikariDataSource
- org.apache.commons.dbcp.BasicDataSource
- org.apache.commons.dbcp2.BasicDataSource
对于这4种数据源,当 classpath 下有相应的类存在时,Springboot 会通过自动配置为其生成DataSource Bean,DataSource Bean默认只会生成一个,四种数据源类型的生效先后顺序如下:Tomcat--> Hikari --> Dbcp --> Dbcp2 。
注:springboot1.0时数据源默认使用的是tomcat,2.0以后换成了hikariHikari的配置参数就是
spring.datasource.hikari.*形式- spring:
- datasource:
- url: jdbc:mysql://127.0.0.1:3306/spring-boot-demo?useUnicode=true&characterEncoding=UTF-8&useSSL=false&autoReconnect=true&failOverReadOnly=false&serverTimezone=GMT%2B8
- username: root
- password: root
- driver-class-name: com.mysql.cj.jdbc.Driver
- type: com.zaxxer.hikari.HikariDataSource
- hikari:
- minimum-idle: 5
- connection-test-query: SELECT 1 FROM DUAL
- maximum-pool-size: 20
- auto-commit: true
- idle-timeout: 30000
- pool-name: SpringBootDemoHikariCP
- max-lifetime: 60000
- connection-timeout: 30000
这些配置的含义:
spring.datasource.hikari.minimum-idle: 最小空闲连接,默认值10,小于0或大于maximum-pool-size,都会重置为maximum-pool-sizespring.datasource.hikari.connection-test-query: 用于测试连接是否可用的查询语句spring.datasource.hikari.maximum-pool-size: 最大连接数,小于等于0会被重置为默认值10;大于零小于1会被重置为minimum-idle的值spring.datasource.hikari.idle-timeout: 空闲连接超时时间,默认值600000(10分钟),大于等于max-lifetime且max-lifetime>0,会被重置为0;不等于0且小于10秒,会被重置为10秒。spring.datasource.hikari.pool-name:连接池的用户定义名称,主要出现在日志记录和JMX管理控制台中以识别池和池配置spring.datasource.hikari.max-lifetime: 连接最大存活时间,不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短spring.datasource.hikari.connection-timeout: 连接超时时间:毫秒,小于250毫秒,否则被重置为默认值30秒
4、Druid数据源
还可以选择使用其他第三方的数据源,例如:Druid、c3p0等。以使用Druid数据源为例。
- <dependency>
- <groupId>com.alibabagroupId>
- <artifactId>druid-spring-boot-starterartifactId>
- <version>1.1.6version>
- dependency>
定义数据源
使用注解@Bean 创建一个DataSource Bean并将其纳入到Spring容器中进行管理即可。- spring:
- datasource:
- druid:
- # 数据库访问配置, 使用druid数据源
- type: com.alibaba.druid.pool.DruidDataSource
- driver-class-name: oracle.jdbc.driver.OracleDriver
- url: jdbc:oracle:thin:@localhost:1521:ORCL
- username: test
- password: 123456
- # 连接池配置
- initial-size: 5
- min-idle: 5
- max-active: 20
- # 连接等待超时时间
- max-wait: 30000
- # 配置检测可以关闭的空闲连接间隔时间
- time-between-eviction-runs-millis: 60000
- # 配置连接在池中的最小生存时间
- min-evictable-idle-time-millis: 300000
- validation-query: select '1' from dual
- test-while-idle: true
- test-on-borrow: false
- test-on-return: false
- # 打开PSCache,并且指定每个连接上PSCache的大小
- pool-prepared-statements: true
- max-open-prepared-statements: 20
- max-pool-prepared-statement-per-connection-size: 20
- # 配置监控统计拦截的filters, 去掉后监控界面sql无法统计, 'wall'用于防火墙
- filters: stat,wall
- # Spring监控AOP切入点,如x.y.z.service.*,配置多个英文逗号分隔
- aop-patterns: com.springboot.servie.*
切换默认数据源,不需要吗???通过在核心配置中通过spring.datasource.type属性指定数据源的类型
-
相关阅读:
RabbitMQ面经
upload-labs通关(Pass01-Pass05)
Dom操作指南
【Java】672. 灯泡开关 Ⅱ
Linux编辑器-vim的使用
mybatisplus开启sql打印的三种方式
信号与线性系统分析(吴大正,郭宝龙)(5-系统定义与典型系统)
SolidWorks模型导入到MATLAB(Simulink-Simscape)详细过程
NoSQL数据库之Redis2
SQL中的函数:单值函数、聚合函数
- 原文地址:https://blog.csdn.net/m0_56799642/article/details/133469576
