-
一致性 Hash 算法
是什么:
一致性 hash,是一种比较特殊的 hash 算法,它的核心思想是解决在分布式环境下, hash 表中可能存在的动态扩容和缩容的问题。
为什么会出现一致性Hash
一般情况下,我们会使用 hash 表的方式以 key-value 的方式来存储数据,但是当数据量比较大的时候,我们就会把数据存储到多个节点上,(如图)然后通过 hash 取模的方法来决定当前 key 存储到哪个节点上。
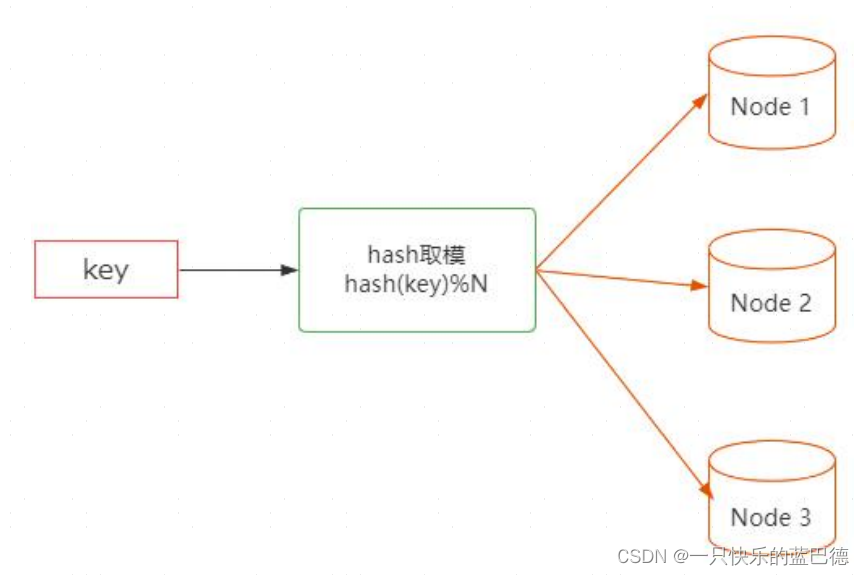
这种方式有一个非常明显的问题,就是当存储节点增加或者减少的时候,原本的映射关系就会发生变化。 也就是需要对所有数据按照新的节点数量重新映射一遍,这个涉及到大量的数据迁移和重新映射,迁移代价很大。
一致性Hash原理
而一致性 hash 就是用来优化这种动态变化场景的算法,它的具体工作原理也很简单。 首先,一致性 Hash 是通过一个 Hash 环的数据结构来实现的,(如图),这个环的起点是 0,终点是 2^32-1。 也就是这个环的数据分布范围是[0,2^32-1]。

(如图)然后我们把存储节点的 ip 地址作为 key 进行 hash 之后,会在 Hash 环上确定 一个位置。

接下来,(如图)就是把需要存储的目标 key 使用 hash 算法计算后得到一个 hash 值, 同样也会落到 hash 环的某个位置上。 然后这个目标 key 会按照顺时针的方向找到离自己最近的一个节点进行数据存储。

为什么一致性Hash比普通hash算法好
假设现在需要新增一个节点(如图)node4,那数据的映射关系的影响范围只限于node3 和 node1, 只有少部分的数据需要重新映射迁移就行了。

如果是已经存在的节点 node1 因为故障下线了(如图),只那只需要把原本分配在 node1 上的数据重新分配到 node2 上就行了。 同样对数据影响的范围非常小。

所以,一致性 hash 算法的好处是扩展性很强,在增加或者减少服务器的时候,数据迁移范围比较小。 另外,在一致性 Hash 算范里面,为了避免 hash 倾斜导致数据分配不均匀的情况,我 们可以使用虚拟节点的方式来解决。
-
相关阅读:
【MATLAB】制作一幅钻石沿着圆周运动的动画
计算机毕业设计之java+ssm 精准扶贫系统
bluecmsv1.6代码审计
nodejs + express 实现 http文件下载服务程序
WindowsNT下的OpenGL
索引-定义、创建(CREATE INDEX)、删除(DROP INDEX)
开源模型应用落地-业务优化篇(八)
【Java SE】如何解读Java的继承和多态的特性?
一阶微分形式不变性
力扣第216 组合总和 ||| c++ 回溯 + 注释
- 原文地址:https://blog.csdn.net/qq_43276879/article/details/133386982