-
28 drf-Vue个人向总结-1
前后端分离开发展示
实际上我们在真正的生产环境之下,采用的都是后端开发后端,前端开发前端的,后端只负责向对应的url传递数据,前端设置,在访问对应的网页的时候,如何去提取对应的数据,这边仅以后端程序员的角度进行分析。
开发阶段的基本流程:
先在服务器上设置,远程连接:

然后之后你在编译器上进行每天写代码后,就可以维护版本,或者说使用服务器的编译器进行构造,多人效率大大提升。

然后就是关于后端项目的启动:


启动之后到你的服务器的对应端口进行浏览器查看,是否后端已经部署完成:

出现了对应提供数据的端口,证明后端启动成功。然后下面就是前端的开发,这边由于本系列前面没有介绍过Vue,这边就不进行详细介绍,这边就告诉个大概,前端此时就有选择了,可以选择在服务器的另一个文件夹下开发,也可以选择本地开发,这边按照本地进行介绍,当然这并不意味着,前端之后不部署到服务器上,这边由于大家不懂,就不详细介绍,大概介绍个流程,让大家理解前后端分离。
对于前端来说:我们来到axios的路径配置的那个文件夹,我们先了解一下,前端所做的事情就是合理组织我们传递到每个url的数据,然后组合成一个页面,所以不论部署到本地,还是部署到服务器上,我们需要的事情都是在每个页面,都到对应的url提取数据,由于我们的数据是部署到后端,也就是前面的那些东西,所以我们需要向 服务器的对应端口处,进行请求数据。

然后就是启动前端项目,和后端一样编辑配置:


然后启动前端(后端如果没有配置nginx,记得后端也需要启动的哈OvO):

至此,我们大概对于前后端分离的架构思路有了一定的理解。
项目项补充知识
开发问题
浏览器解决跨域问题
谷歌设置为非安全模式
C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --user-data-dir="C:/MyChromeDevUserData" --test-type --disable-web-security- 1
再创建一个新的快捷方式,将他的后缀改成这个样子,并且记得到C:/MyChromeDevUserData创建这个文件夹,或者你也可以修改成别的文件夹名称。
drf 小tips
设置资源root目录
先想一下为什么需要设置资源文件位置,原因就是我们往往项目设计的时候并不仅仅只有一个app,以及一些额外的app,但把这些app都放在项目的外面,这明显不是一个好的方法,我们更希望集合到一起。

这个时候我们就把项目的apps都放到了一个文件app包当中了,第三方插件放到了extra_apps当中了,但是此时我们仍然希望,我们在使用import的时候不需要进行改变,不需要改成from apps.goods import 啥啥啥这样子,我们仍然希望可以直接from goods import 啥啥啥 这样子,我们此时就需要设置资源路径:第一种方法就是在setting.py当中加入这种:
import sys sys.path.insert(0, os.path.join(BASE_DIR, 'apps')) sys.path.insert(0, os.path.join(BASE_DIR, 'extra_apps'))- 1
- 2
- 3
第二种方式实际上和第一种是一样的,只不过使用可视化替代了上述操作:

然后编译器就会自动的去添加了。使用自定义的user表
第一步就是新建一个user的app
然后在模型类当中去继承原本的user,而不是原本继承的models.Model
class UserProfile(AbstractUser): """ 用户 """ name = models.CharField(max_length=30, null=True, blank=True, verbose_name="姓名") birthday = models.DateField(null=True, blank=True, verbose_name="出生年月") gender = models.CharField(max_length=6, choices=(("male", u"男"), ("female", "女")), default="female", verbose_name="性别") mobile = models.CharField(null=True, blank=True, max_length=11, verbose_name="电话") email = models.EmailField(max_length=100, null=True, blank=True, verbose_name="邮箱") class Meta: verbose_name = "用户" verbose_name_plural = verbose_name def __str__(self): return self.username- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
接着去setting当中:
AUTH_USER_MODEL = 'users.UserProfile'- 1
如此只是改变了寻找user表的路径,然后讲一下在使用的时候该怎么进行使用。
from django.contrib.auth import get_user_model User = get_user_model() User此时就是我们定义的那个对应的类了。- 1
- 2
- 3
- 4
- 5
设置资源路径media
到setting中设置:
MEDIA_URL = "/media/" MEDIA_ROOT = os.path.join(BASE_DIR, "media")- 1
- 2
数据库补充删除表中数据
TRUNCATE 清空数据 (还原主键,自增的 ID 会重新从 1 开始)
DELETE 删除数据 (删除数据,自增的 ID 会继续递增)如果整张的表的数据不想要了,我们可以使用上面的那个删除的操作。
从逻辑上说,TRUNCATE 语句与 DELETE 语句作用相同,但是在某些情况下,两者在使用上有所区别:
- DELETE 是 DML 类型的语句;TRUNCATE 是 DDL 类型的语句。它们都用来清空表中的数据。
- DELETE 是逐行一条一条删除记录的;TRUNCATE 则是直接删除原来的表,再重新创建一个一模一样的新表,而不是逐行删除表中的数据,执行数据比 DELETE 快。
使用方式:
TRUNCATE [TABLE] 表名- 1
单页面与多页面模式
虽然这个实际上和前端相关,但是后端也了解一下吧。
对于个人的理解的话,先讲区别吧,区别就是实际上你的生成的时候生成的是一个页面还是多个页面,(静态资源),就是你在前端代码运行生成出来的文件时一个还是多个,hh,个人水平有限,看上面的链接,单页面也是大厂很喜欢的一种模式,当然对于SEO很不友好,但是谁管SEO呢,hh。
过滤
之前的drf当中确实讲解过过滤,但是没有讲解到自定义过滤器,给出官网的快速入门进行理解。
配置:
# settings.py INSTALLED_APPS = [ ... 'rest_framework', 'django_filters', ] REST_FRAMEWORK = { 'DEFAULT_FILTER_BACKENDS': ( 'django_filters.rest_framework.DjangoFilterBackend', ... ), }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这边给出一部分简单的解析,深层次的到我给的官方文档里面进行查看:
首先先创建一个新的py文件(对应应用中)filters.py:
from django_filters import rest_framework as filters class GoodsFilter(filters.FilterSet): pricemin = filters.NumberFilter(field_name="shop_price", lookup_expr='gte') pricemax = filters.NumberFilter(field_name="shop_price", lookup_expr='lte') name =filters.CharFilter(field_name = "name",lookup_expr = 'icontains') #contains代表包含,i代表不区分大小写- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后到view视图进行具体使用的时候:
class GoodsListViewSet(viewsets.ReadOnlyModelViewSet) : ''' 这么少的代码,实现了 商品列表,分页,搜索,过滤,排序 ''' queryset = Goods.objects.all() serializer_class = GoodsSerializer pagination_class = GoodsPagination filter_backends = [ DjangoFilterBackend,filters.SearchFilter,filters.OrderingFilter] # filterset_fields = [ 'name', 'shop_price' ] #根据model中的名字进行设置 filter_class=GoodsFilter search_fields = ['name', 'goods_brief', 'goods_desc'] ordering_fields = [ 'sold_num', 'shop_price' ]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
根据上面我们可以发现我们自定义的filter_class实际上用到的就是DjangoFilterBackend内部的选项,我们讲我们自定义的覆盖了其。
多层自关联
在子查询的时候,我们普通查询出来的数据,仅仅只是第一层的数据,比如说parent_id = null的,但是我们可能想要展示的数据包含着第二层的数据,乃至第三层的数据,而且我们想要全部都进行展示,按照一定的json格式进行展示,当然可以使用嵌套类进行完成,但鉴于这种子查询的层数一般不会太多,这边采用一种比较方便的做法,例子:
先展示模型类(只展示重点代码,以及具体处理的方式):
class GoodsCategory(models.Model): """ 商品类别 """ parent_category = models.ForeignKey("self", null=True, blank=True, verbose_name="父类目级别", help_text="父目录",related_name="sub_cat",on_delete=models.CASCADE) 其他略- 1
- 2
- 3
- 4
- 5
- 6
重点在意那两列即可:

然后就是具体的展示子查询的方式,修改serializer的序列化功能即可,因为我们发现我们的级别最多只有三层,那么这边进行调用三次即可,值得关注的是sub_cat这个名字不是乱取的,这个名字是自关联的model当中定义的。class CategorySerializer3(serializers.ModelSerializer): class Meta: model = GoodsCategory fields = "__all__" class CategorySerializer2(serializers.ModelSerializer): sub_cat = CategorySerializer3(many=True) class Meta: model = GoodsCategory fields = "__all__" class CategorySerializer(serializers.ModelSerializer): sub_cat = CategorySerializer2(many=True) class Meta: model = GoodsCategory fields = "__all__"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这样子执行就有了相关的三层数据,这种做法好好理解一下,这边的all很有学问。
后端提交的数据到底是什么
学了很久前后端,但是始终没有明说前后端分离下,后端每一个url所提交的数据到底是什么,这边说一下,因为博主在开发的时候,发现前端的想要的数据和后端提供的数据发生了不一样的地方,这边就提一嘴,并且给出博主错误的原因

但这些都只是纸面上谈谈,具体的格式协商需要和前端程序员进行协商,一般都不会采用全局设置,因为全局设置之后,后面想要再个性化设置不论是数据发生了改变,代码层面也不适合阅读调试。jwt token登录设置
首先引入一下,为什么需要使用jwt token进行登录,我们之前写的那个session登录不是不是很完美吗?上一章也介绍过了,是很完美,但是在面对分布式的情况下,session只存储在其中一台服务器上,当请求发送到另一台服务器,那么这就造成了登录不上的问题了,所以这个时候就需要使用token进行登录,使用token解码来进行实现即使发送的请求到不同的服务器上,也能通过这个token,来进行分辨出你到底登录没有,以及登录的信息(这个详细理论可见之前的网络通信那一边有进行介绍-----不过当时实现的是虚假的token)。这边稍微提一嘴,session遵循base64解码,后面不说了OxO。
相同的jwt又是什么呢?和普通的jwt登录又有什么区别,这个不急,先理解普通的token
普通的 token 原理
普通的token实际上就是一个随机字符串,他和Session最大的区别就是,Session做的事情太多了,每次提交一次网页都需要进行对于session-id,然后提取出数据,然后base64解码,这边就很有问题,token简化了这一个过程在你成功登录之后,就会以cookie的方式给你派发一个随机字符串token,然后把这个token存储到数据库当中,而对应的这张表当中的数据的第一列:token码,第二列:你的user_id,这就极大的方便了流程,
其实好像还好,但是确实可以减少步骤。而使用token进行登录之前也稍微提了一嘴,这边会稍微再提一点。
具体使用:
首先到setting当中加上’rest_framework.authentication.TokenAuthentication’REST_FRAMEWORK = { 'DEFAULT_AUTHENTICATION_CLASSES': [ 'rest_framework.authentication.BasicAuthentication', 'rest_framework.authentication.SessionAuthentication', 'rest_framework.authentication.TokenAuthentication', ]}- 1
- 2
- 3
- 4
- 5
- 6
实际上是最后一个起效果。
然后app当中加入对应的app
INSTALLED_APPS = [ ... 'rest_framework.authtoken']- 1
- 2
- 3
这时我们执行 migrations 和 migrate 就会产生一张表,token的上面讲述原理的那张表
接着就是,到对应的urls当中加入:
from rest_framework.authtoken import views urlpatterns += [ re_path(r'^api-token-auth/', views.obtain_auth_token) ]#向这个 url post 我们的用户名和密码就会返回我们的 token- 1
- 2
- 3
- 4
- 5
然后实际上后面进行使用的话,就是控制登录之后,访问这个url,返回对应的token,给前端。
使用流程解析
经过上面的步骤之后配置好了url,此时我们具体的使用流程就是:
-
向 http://·········/api-token-auth/提交用户名和密码,就会得到一个token。
数据的格式
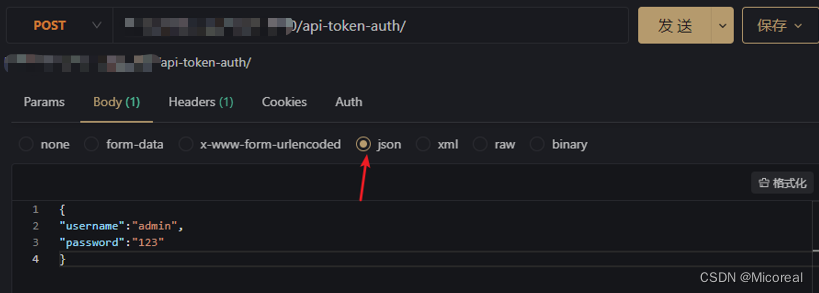
-
然后是记得把Headers加上这个字段Content-Type: application/json:

-
然后就会返回一个token:3a5bfe2e6daaf83c483510b50461a1808cb39dcc 此时服务器已经做到了将这个token存储到你的数据库当中,并且也存入了你的对应的use_id.
-
最后自然就是关于如何去使用:随便查询一个页面,并在header当中加上:Authorization,值为Token xxxxxxxxxx,如此之后就可以进行识别了。

jwt token原理
使用了token之后,我们还是觉得不太好,上面的分布式的问题还是没有进行解决,如果每一次登录,我们都需要到分布式集群当中去一个个查找,这样子效率就实在太低了,所以自然诞生了jwt token,说人话,其实他就是不去查询数据库的做法,他在你第一次登录的情况下,已经做到了将你的部分不重要的(注意不重要,因为编码可破译base64)但是可以标明你是谁的信息放到了这个token当中,然后我们在访问服务器的时候,就根据破译这个token就可以获取你登录的信息到底是什么了。
上面是部分比较碎嘴化的东西,主要讲解的就是为什么会有这种东西,后面讲解jwt token的格式。
首先先明白jwt token其实分为三个部分 头部 负载 签名,并且jwt其实存在一个私钥(私钥的作用就是唯一标识),这个服务器会隔一定的时间就进行修改。我们先生成一个jwt token,再进行原理剖析。
然后就是关于对称加密,非对称加密,散列加密,可见我的另一篇博客,杂谈处。
使用流程 与 原理剖析
官网:链接
下载:
pip install djangorestframework-jwt- 1
- 2
使用:
REST_FRAMEWORK = { 'DEFAULT_PERMISSION_CLASSES': ( 'rest_framework.permissions.IsAuthenticated', ), 'DEFAULT_AUTHENTICATION_CLASSES': ( 'rest_framework_jwt.authentication.JSONWebTokenAuthentication', 'rest_framework.authentication.SessionAuthentication', 'rest_framework.authentication.BasicAuthentication', ), } # 以及设置过期时间 JWT_AUTH = { 'JWT_EXPIRATION_DELTA': datetime.timedelta(days=1), }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在 urls.py 添加以下 URL 路由以启用通过 POST 获取令牌时,包含用户的用户名和密码。
from rest_framework_jwt.views import obtain_jwt_token #... urlpatterns = [ '', # ... url(r'^jwt-auth/', obtain_jwt_token), ]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
向http://远程服务器:8000/jwt-auth/ 发送请求

然后就会接收到一个jwt-token:{ "token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNjQ5MjE2ODkwLCJlbWFpbCI6IjEyM0BxcS5jb20ifQ.guIU-TJ6ECjNKUKxer6wki9mvj9Gb-duManEFwyKNbw" }- 1
- 2
- 3
- 4
我们可以看出他明显分成三个部分 什么什么.什么什么.什么什么
其实就是一对一相对应的:
第一部分:header
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9- 1
我们拿base64解析一下:

其实就告诉了我们他的type是jwt 他的加密算法是HS256然后第二部分:
eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNjQ5MjE2ODkwLCJlbWFpbCI6IjEyM0BxcS5jb20ifQ- 1
继续拿base64解析一下:

此时就可以发现你个人的部分信息是存储到这里面了。第三部分就没办法解析了,第三部分就是拿前两部分之和加上服务器的一把私钥,合起来一起加密的,使用哪个HS256加密算法,进行的加密,这边演示不出来。
详细可见上面给的博客,那边讲的很详细,也很好。

然后接着讲使用:使用的化就是头部需要加上:
Authorization:JWT eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNTczMDQyNjAyLCJlbWFpbCI6ImRheHVlbHVAZm94bWFpbC5jb20ifQ.KReyfJjrARcHVw6bNc3FghnGLXAlhmuykszc63SoqTE- 1
然后进行模拟发包,如此之后,就可以做到大厂现在最常使用的jwt登录,OvO。
然后就是关于登录的理解:
由于前后端分离的性质,这边给出vue的前端代码:
login({ username:this.userName, //当前页码 password:this.parseWord }).then((response)=> { console.log(response); //本地存储用户信息 cookie.setCookie('name',this.userName,7); cookie.setCookie('token',response.data.token,7) //用来存储 token //存储在 store // 更新 store 数据 that.$store.dispatch('setInfo'); //跳转到首页页面 this.$router.push({ name: 'index'}) })- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
整个流程我们可以看到实际上我们只需要把上面的jwt的url修改成login,即可进行访问了,整个登录的流程就是:首先我们先打开一个点击网页当中的登录界面(当然这个页面就是前端进行构建的)

然后我们填写账号密码之后,点击登录,看那个前端代码,我们会向后端提交账户名和密码,然后后端会进行验证,至于登录的验证,这边由于我们使用的是jwt的view,所以不需要我们写,是否从数据库当中得到,账号密码一致这样子,我们除非我们需要重写一部分登录的东西,就需要重写(后文会进行介绍)。当我们后端判断无误后,我们会返回一个jwt token给前端,然后前端将之存储到token,并且跳转到首页,完成这一系列的功能,然后之后的访问,实际上浏览器就是通过这个token进行身份识别并且操作的。
下面进行介绍,如何重写相关的检测函数,首先就是由于user的检测是由框架自己去实现的,所以这边的检测就需要我们去重写相关的函数,以及将执行的那个函数指向到我们的函数:
第一步自然是去setting当中去修改:
AUTHENTICATION_BACKENDS = ( 'users.views.CustomBackend', )- 1
- 2
- 3
这个的意思就是把这个身份验证的路径转到我们的users.view.CustomBackend当中,也即到我们自己写的类当中去执行相对应的检测。
第二步也自然是去对应的view当中进行修改:
from django.contrib.auth import get_user_model from django.db.models import Q User = get_user_model() class CustomBackend(ModelBackend): """ 自定义用户验证 """ def authenticate(self, request,username=None, password=None, **kwargs): try: user = User.objects.get(Q(username=username)|Q(mobile=username)) if user.check_password(password): return user except Exception as e: return None- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
也就是这边进行检测的,我们修改了这个检测的逻辑从而让我们的项目更加完整。
用户手机注册
这边使用的是yunpian的验证码发送。
测试的代码
import json import requests class YunPian(object): def __init__(self, api_key): self.api_key = api_key self.single_send_url = "https://sms.yunpian.com/v2/sms/single_send.json" def send_sms(self, code, mobile): parmas = { "apikey": self.api_key, "mobile": mobile, "text": "【啥啥啥公司】您的验证码是{code}。如非本人操作,请忽略本短信".format(code=code) } response = requests.post(self.single_send_url, data=parmas) re_dict = json.loads(response.text) return re_dict if __name__ == "__main__": yun_pian = YunPian("阿巴阿巴") yun_pian.send_sms("8888", "110")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
这边给出发送手机短信的功能,根据这个来即可。
-
相关阅读:
基于Python开发的五子棋小游戏(源码+可执行程序exe文件+程序配置说明书+程序使用说明书)
jmeter-11-Ant接口自动化及持续集成整合
Python 爬虫之urllib库,及urllib库的4个模块基本使用和了解
【力扣】300. 最长递增子序列 <动态规划>
Pandas数据处理分析系列6-数据特征分析
Maven系列第4篇:仓库详解
Keras CIFAR-10分类 SVM 分类器篇
一招解决IDEA使用Junit4自动创建的测试类无内容问题
Android 面试问题 2024 版(其一)
springboot265基于Spring Boot的库存管理系统
- 原文地址:https://blog.csdn.net/Micoreal/article/details/133299185
