-
深度学习-学习率调度,正则化,dropout
正如前面我所说的,各种优化函数也依赖于学习率,保持学习率恒定总是有所限制,在执行梯度下降过程中,我们可以使用各种方法来调节训练过程的学习率,这里只是稍微介绍一下,不会写代码实现的。同时,顺便几种其他的手段防止过拟合。
1.学习率调度
(1).幂调度,学习率随着迭代次数下降,而下降的指数为幂指数,幂指数可以为1

c就是幂指数,一般取1,t代表迭代次数,s是超参数,
 代表初始的学习率
代表初始的学习率(2).指数调度

随着迭代的输出减少
(3)分段恒定调度
对一些轮数使用一个固定的学习率,到了另外一些使用较小的学习率
(4).性能调度
没N次查看一次误差,当误差下降的时候,减少学习率
(5)一周期调度1
在最开始的训练周期中,将学习率线性提高,然后再线性降低到原来的学习率,在后面的几个轮次中降低几个数量级。
在tensorflow中都有相应的方法
2.正则化
如果懂得线性回归,这个就很容易理解,使用L1正则化和L2正则化在线性回归中很常见,分别式LOASS回归和岭回归。神经网络一样有这两种正则化方式,用来限制Omega的调整范围,L1正则化用来稀疏模型,他会使得参数为0。L2正则化会使参数很小。L1正则化适合做特征选择,模型剪枝,L2正则化适合提升模型泛化。
3.dropout
这种方法目前没有合理的解释,深度学习的很多理论好像本来无法解释,所以不要在意这些了,在一些先进的网络里面用这个技术,也很得到不错的提升。
这个算法很简单,就是在每个训练迭代过程中,每次都"删除"一些神经元,每个神经元被删除的概率为p,删除之后,就没有信号从它这里流过去了,但是下一次它可能又会出现。
这个算法只会在训练过程中使用,在预测的适合,所有的神经元都要处于活动状态。
有一个问题,预测过程中,每个神经元都承担了平时1/p的信号量,那么相对的,就要在训练结束后,让他们的输入参数乘以p,或者输出参数乘以1/p,两者效果等价。
还有两个比较小众的方法写在下面,一个式蒙特卡洛dropout,一个是最大正则化。
(1)蒙特卡洛dropout会在测试期间使得dropout继续运行,对测试集多次重复预测,得到一个结果,然后除以重复的次数,就能得到一个预测概率和置信区间,这么看确实比较合理,可以用来做风险评估。
(2).最大正则化算法是使用L2正则化,限制传入连接的权重w,使得
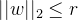 ,r是你设定的常数,这个算法不会使用到误差函数更新,而是将每次的传入权重进行缩放,使之满足条件。
,r是你设定的常数,这个算法不会使用到误差函数更新,而是将每次的传入权重进行缩放,使之满足条件。 -
相关阅读:
对数据“投入”却没有“产出”?听听 Gartner 的最新分析
【软考 系统架构设计师】项目管理④ 软件质量管理
Verlog-串口发送-FPGA
【网页设计】基于HTML在线图书商城购物项目设计与实现_(图书商城10页) bootstarp响应式
题目 1096:扫雷舰
torch.nn.Conv3d()
return语句
合并k个已排序的链表
FPGA代码设计规范一些探讨
4、Linux:如何在zip压缩文件中搜索指定内容
- 原文地址:https://blog.csdn.net/weixin_42581560/article/details/133328546