-
人工智能AI 全栈体系(六)
第一章 神经网络是如何实现的
这些年神经网络的发展越来越复杂,应用领域越来越广,性能也越来越好,但是训练方法还是依靠 BP 算法。也有一些对 BP 算法的改进算法,但是大体思路基本是一样的,只是对 BP 算法个别地方的一些小改进,比如变步长、自适应步长等。还有就是,由于训练数据存在噪声,训练神经网络时也并不是损失函数越小越好。当损失函数特别小时,可能会出现所谓的“过拟合”问题,导致神经网络在实际使用时性能严重下降。
六、过拟合问题

1. 什么是过拟合问题?

- 上图中蓝色圆点给出的是 6 个样本点,假设这些样本点来自于某个曲线的采样,但是我们又不知道原曲线是什么样子,如何根据这 6 个样本点“恢复”出原曲线呢?这就是拟合问题。下图给出了 3 种拟合方案,其中绿色的是一条直线,显然拟合的有些粗糙,蓝色曲线有点复杂,经过了每一个样本点,该曲线与 6 个采样点完美地拟合在一起,似乎是个不错的结果,但是为此付出的代价是曲线弯弯曲曲,感觉是为拟合而拟合,没有考虑 6 个样本点的分布趋势。考虑到采样过程中往往是含有噪声的,这种所谓的完美拟合其实并不完美。红色曲线虽然没有经过每个样本点,但是更能反映 6 个样本点的分布趋势,很可能更接近于原曲线,所以有理由认为红色曲线更接近原始曲线,是我们想要的拟合结果。如果我们用拟合函数与样本点的误差平方和作为拟合好坏的评价,也就是损失函数,绿色曲线由于距离样本点比较远,损失函数最大,蓝色曲线由于经过了每个样本点,误差为 0,损失函数最小,而红色曲线的损失函数介于二者之间。绿色曲线由于拟合的不够,我们称作欠拟合,蓝色曲线由于拟合过渡,我们称为过拟合,而红色曲线是我们希望的拟合结果。在神经网络的训练中,也会出现类似的欠拟合和过拟合的问题。

- 欠拟合显然是不好的结果,过拟合会带来什么问题呢?
2. 神经网络的过拟合问题
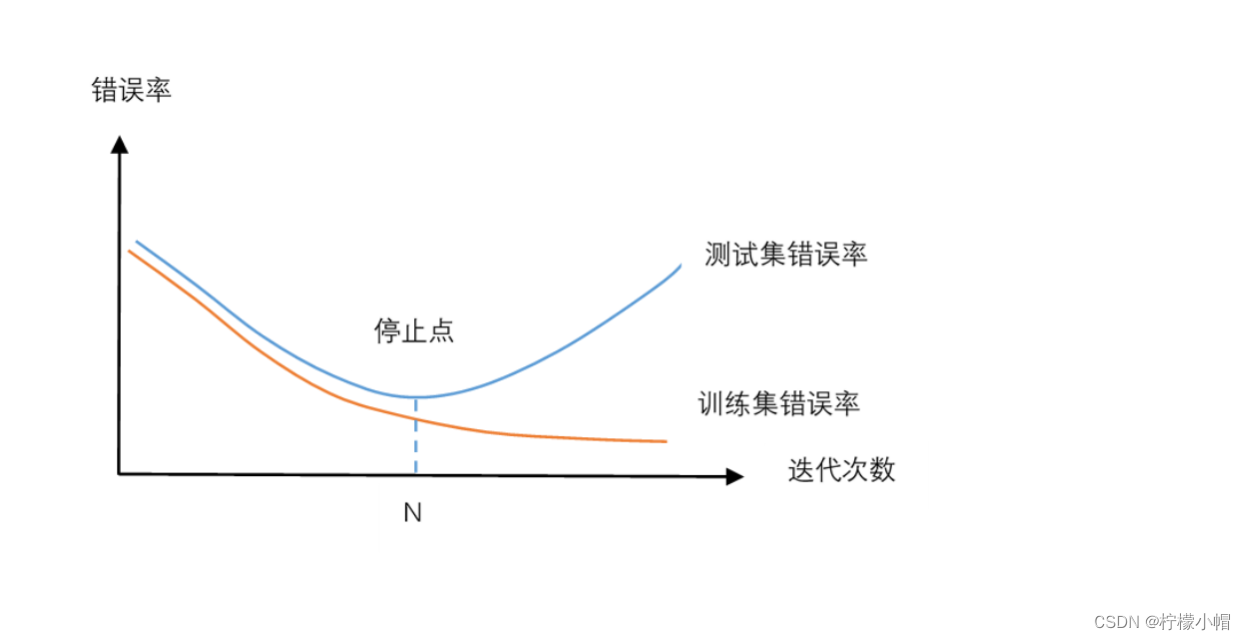
- 我们把样本集分成训练集和测试集两个集合,训练集用于神经网络的训练,测试集用于测试神经网络的性能。如上图所示,纵坐标是错误率,横坐标是训练时的迭代轮次。红色曲线是在训练集上的错误率,蓝色曲线是测试集上的错误率。每经过一定的训练迭代轮次后,就测试一次训练集和测试集上的错误率。从图中可以发现,在训练的开始阶段,由于处于欠拟合状态,无论是训练集上的错误率还是测试集上的错误率,都随着训练的进行逐步下降。但是当训练迭代轮次达到 N 次后,测试集上的错误率反而逐步上升了,这就是出现了过拟合现象。测试集上的错误率相当于神经网络在实际使用中的表现,因此我们希望得到一个合适的拟合,使得测试集上的错误率最小,所以应该在迭代轮次达到 N 次时,就结束训练,以防止出现过拟合现象。
- 训练时并不是损失函数越小越好。
- 何时开始出现过拟合并不容易判断。一种简单的方法就是使用测试集,做出像上图那样的错误率曲线,找到 N 点,用在 N 点得到的参数值作为神经网络的参数值就可以了。
- 但这种方法要求样本集合比较大才行,因为无论是训练还是测试都需要比较多的样本才行。而实际使用时往往是面临样本不足的问题。
- 为解决过拟合问题,研究者提出了一些方法,可以有效缓解过拟合问题。当然每种方法都不是万能的,只能说在一定程度上弱化了过拟合问题。
3. 减少过拟合的方法:正则化项法
- BP算法时,用的损失函数是:
E d ( w ) = ∑ k = 1 M ( t k d − o k d ) 2 E_d(w) = \sum^{M}_{k=1}{(t_{kd} - o_{kd})^2} Ed(w)=k=1∑M(tkd−okd)2
- 在这个损失函数上增加一个正则化项
∥
w
∥
2
2
\begin{Vmatrix}w\\\end{Vmatrix}_2^2
w
22 ,变成:
E d ( w ) = ∑ k = 1 M ( t k d − o k d ) 2 + ∥ w ∥ 2 2 E_d(w) = \sum^{M}_{k=1}{(t_{kd} - o_{kd})^2} + \begin{Vmatrix}w\\\end{Vmatrix}_2^2 Ed(w)=k=1∑M(tkd−okd)2+ w 22 - 其中 ∥ w ∥ 2 2 \begin{Vmatrix}w\\\end{Vmatrix}_2^2 w 22 表示权重w的2-范数, ∥ w ∥ 2 2 \begin{Vmatrix}w\\\end{Vmatrix}_2^2 w 22 表示2-范数的平方。
- w的2-范数就是每个权重
w
i
w_i
wi 平方后求和再开方,这里用的是2-范数的平方,所以就是权重的平方和了。如果用
w
i
(
i
=
1
,
2
,
.
.
.
,
N
)
w_i(i=1,2,...,N)
wi(i=1,2,...,N) 表示第i个权重,则:
∥ w ∥ 2 2 = w 1 2 + w 2 2 + ⋯ + w N 2 \begin{Vmatrix}w\\\end{Vmatrix}_2^2 = w_1^2 + w_2^2 + \cdots + w_N^2 w 22=w12+w22+⋯+wN2 - 当然这里并不局限于2-范数,也可以用其他的范数。

4. 正则化项的作用:降低模型复杂性
- 为什么增加了正则化项后就可以避免过拟合呢?
- 添加了正则化项的损失函数,相当于在最小化损失函数的同时,要求权重也尽可能地小,相当于限制了权重的变化范围。
- 以下图所示的曲线拟合为例说明,作为一般的情况,一个曲线拟合函数f(x)可以认为是如下形式:
f ( x ) = w 0 + w 1 x + w 2 x 2 + ⋯ + w n x n f(x) = w_0 + w_1x + w_2x^2 + \cdots + w_nx^n f(x)=w0+w1x+w2x2+⋯+wnxn - 如果f(x)中包含的 x n x^n xn 项越多,n越大,则f(x)越可以表示复杂的曲线,拟合能力就越强,也更容易造成过拟合。

- 比如在上图所示的3条曲线,绿色曲线是个直线,其形式为:
f ( x ) = w 0 + w 1 x f(x) = w_0 + w_1x f(x)=w0+w1x - 只含有x项,只能表示直线,所以就表现为欠拟合。而对于其中的蓝色曲线,其形式为:
f ( x ) = w 0 + w 1 x + w 2 x 2 + w 3 x 3 + w 4 x 4 + w 5 x 5 f(x) = w_0 + w_1x + w_2x^2 + w_3x^3 + w_4x^4 + w_5x^5 f(x)=w0+w1x+w2x2+w3x3+w4x4+w5x5
含有5个 x n x^n xn 项,表达能力比较强,从而造成了过拟合。而对于其中的红色曲线,其形式为:
f ( x ) = w 0 + w 1 x + w 2 x 2 f(x) = w_0 + w_1x + w_2x^2 f(x)=w0+w1x+w2x2
含有2个 x n x^n xn 项,对于这个问题来说,可能刚好合适,所以体现了比较好的拟合效果。但是在实际当中呢,我们很难知道应该有多少个 x n x^n xn 项是合适的,有可能 x n x^n xn 项是比较多的,通过在损失函数中加入正则化项,使得权重w尽可能地小,在一定程度上可以限制过拟合情况的发生。比如对于蓝色曲线:
f ( x ) = w 0 + w 1 x + w 2 x 2 + w 3 x 3 + w 4 x 4 + w 5 x 5 f(x) = w_0 + w_1x + w_2x^2 + w_3x^3 + w_4x^4 + w_5x^5 f(x)=w0+w1x+w2x2+w3x3+w4x4+w5x5
虽然它含有5个 x n x^n xn 项,但是如果我们最终得到的 w 3 w_3 w3 、 w 4 w_4 w4 、 w 5 w_5 w5 都比较小的话,那么也就与红色曲线:
f ( x ) = w 0 + w 1 x + w 2 x 2 f(x) = w_0 + w_1x + w_2x^2 f(x)=w0+w1x+w2x2
比较接近了。 - 对于一个复杂的神经网络来说,一般具有很强的表达能力,如果不采取专门的方法加以限制的话,很容易造成过拟合。
5. L2(2-范数)正则化项

6. L1(1-范数)正则化项

7. 减少过拟合的方法:舍弃法(Dropout)
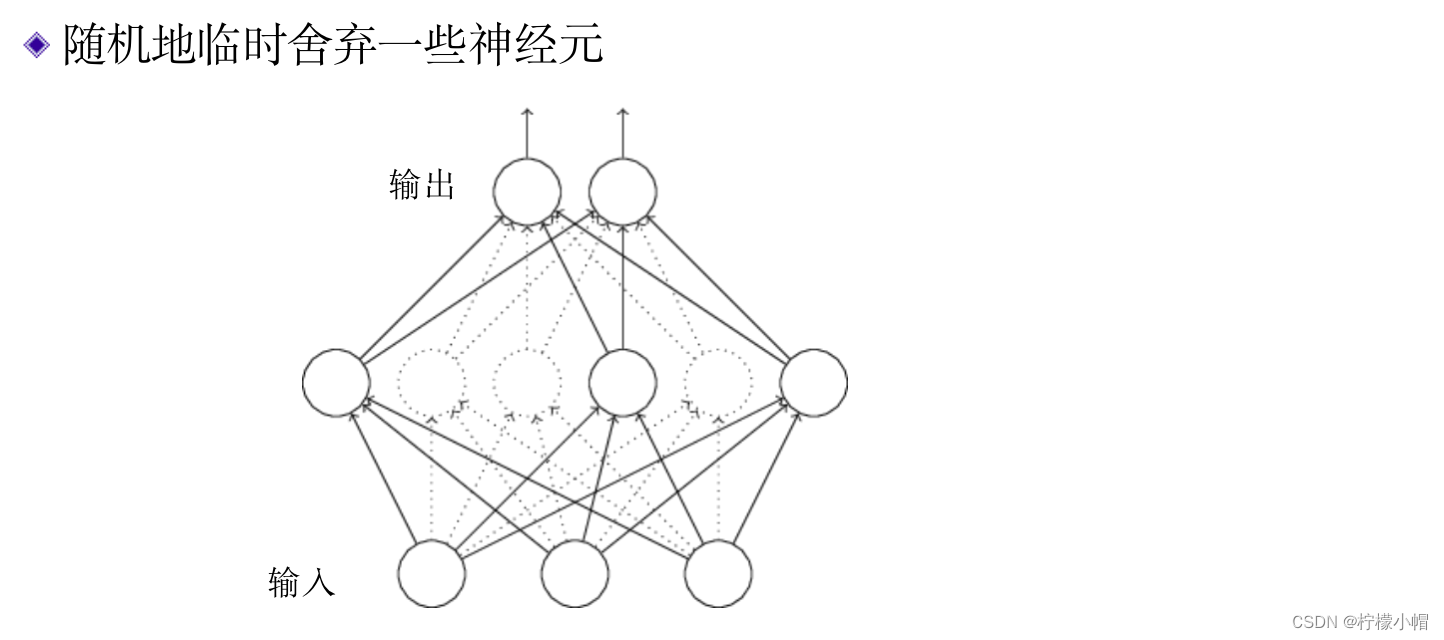
- 所谓的舍弃法,就是在训练神经网络的过程中,随机地临时删除一些神经元,只对剩余的神经元进行训练。哪些神经元被舍弃是随机的,并且是临时的,只在这次权重更新中被舍弃,下一次更新时哪些神经元被舍弃,再重新随机选择,也就是说每进行一次权重更新,都要重新做一次随机舍弃。下图给出了一个舍弃示意图,图中虚线所展示的神经元表示被临时舍弃了,可以认为这些神经元被临时从神经网络中删除了。舍弃只发生在训练时,训练完成后在使用神经网络时,所有神经元都被使用。
- 一个神经网络含有的神经元越多,表达能力越强,越容易造成过拟合。所以简单地理解就是在训练阶段,通过舍弃减少神经元的数量,得到一个简化的神经网络,降低了神经网络的表达能力。但是由于每次舍弃的神经元又是不一样的,相当于训练了多个简化的神经网络,在使用神经网络时又是使用所有神经元,所以相当于多个简化的神经网络集成在一起使用,既可以减少过拟合,又能保持神经网络的性能。举一个例子说明这样做的合理性。比如有 10 个同学组成一个小组做实验,如果 10 个同学每次都一起做,很可能就是两三个学霸在起主要作用,其他同学得不到充分的训练。但是如果引入“舍弃机制”,每次都随机地从 10 名同学中选取 5 名同学做实验,这样会有更多的同学得到了充分的训练。当 10 名同学组合在一起开展研究时,由于每个同学都得到了充分的训练,所以 10 人组合在一起会具有更强的研究能力。
- 舍弃是在神经网络的每一层进行的,除了输入层和输出层外,每一层都会发生舍弃,舍弃的比例大概在50%左右,也就是说在神经网络的每一层,都大约舍弃掉50%左右的神经元。
8. 减少过拟合的方法:数据增强法
- 在曲线拟合中,如果数据足够多,过拟合的风险就会变小,因为足够多的数据会限制拟合函数的激烈变化,使得拟合函数更接近原函数。

9. 如何获得更多的数据?
- 除了尽可能收集更多的数据外,可以利用已有的数据产生一些新数据。比如想识别猫和狗,我们已经有了一些猫和狗的图片,那么可以通过旋转、缩放、局部截取、改变颜色等方法,将一张图片变换成很多张图片,使得训练样本数量数十倍、数百倍地增加。实验表明,通过数据增强可以有效提高神经网络的性能。

10. 总结

- 由于数据存在噪声等原因,在神经网络的训练过程中并不是损失函数越小越好,因为当训练到一定程度后,进一步减少训练集上的误差,反而会加大在测试集上的误差。这一现象称为过拟合。
- 有三种减少过拟合的方法:
(1)正则项法。也就是在损失函数中增加正则项,让权重尽可能地小,达到防止过拟合的目的。
(2)舍弃法。在训练过程中,随机地临时舍弃一部分神经元,每次舍弃都相当于只训练一个子网络。其结果相当于训练了多个子网络再集成在一起使用,网络的每个部分都得到了充分的训练,从而提高了神经网络的整体性能。
(3)数据增强法。一般来说,训练数据越大,训练的神经网络性能会越好。当没有足够多的训练数据时,可以通过对已有数据进行处理产生新的数据的办法,增大训练数据。这一方法称为数据增强方法。比如对于图像数据,可以通过旋转、缩放、局部截取、改变颜色等方法,将一张图片变换成很多张图片,使得训练样本数量数十倍、数百倍地增加。
-
相关阅读:
事务回滚异常
用CSS实现宽度自适应100%,宽高比例为16: 9的矩形
二硒化钨纳米粒WSe2修饰多肽cTAT/RVG29/SP94/GE11/CPP/R8/CTT2/CCK8(cTAT-WSe2)
Minio多节点多驱动分布式部署官网文档翻译
界面控件Telerik UI for WPF中文教程 - 用RadSvgImage升级应用程序UI
Mybatis-plus-generator 自定义模板生成自定义 DTO、VO等
3D目标检测实战 | 详解2D/3D检测框交并比IoU计算(附Python实现)
MNN实践[C++版本]
分享一些可以提升生信分析效率的vscode插件
uniApp开发小程序基础教程(一)
- 原文地址:https://blog.csdn.net/sgsgkxkx/article/details/133281146