-
【1++的Linux】之进程(三)
👍作者主页:进击的1++
🤩 专栏链接:【1++的Linux】一,什么是进程地址空间?
我们先来看一幅图
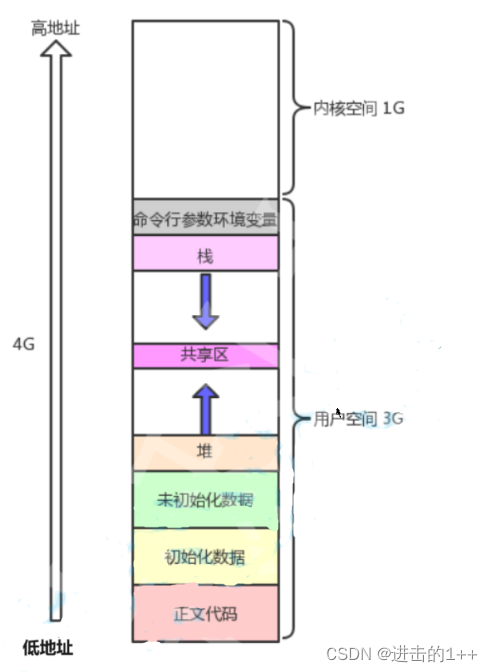
这就是我们的进程地址空间的分布。
其分为了内核空间和用户空间。从具体进程的角度来看,每个进程可以拥有4G字节的虚拟地址空间(也叫虚拟内存)。其中每个进程有各自的私有用户空间(0~3G),这个空间对系统中的其他进程是不可见的。最高的1GB内核空间则为所有进程以及内核所共享。
而用户空间又被细分为我们所熟知的:堆区,栈区,代码区…
接下来我们对用户空间的分布进行验证:#include#include int global=3; int uninit_global; int main() { printf("正文代码:%p\n",main); printf("初始化数据:%p\n",&global); printf("未初始化数据:%p\n",&uninit_global); int* ptr=(int*)malloc(sizeof(int)); printf("堆区:%p\n",ptr); printf("栈区:%p\n",&ptr); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
运行结果:

由此我们可以基本得出,我们所谓的数据在进程地址空间中就是那样分布的。
还需要补充的就是:堆栈相对而生;static修饰的变量本质是将其开辟在全局区域。在来一个有意思的小实验:
代码如下:#include#include int global=0; int main() { size_t ret=fork(); if(ret<0) { perror("进程错误"); } else if(ret==0) { global=3; printf("child::pid:%d---global:%d---address:%p\n",getpid(),global,&global); sleep(1); } else{ printf("father::pid:%d---global:%d---address:%p\n",getpid(),global,&global); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

我们观察结果可以发现:全局变量global在父子进程的值不一样,但是其地址却是相同的。
我们可以得出:
其首先变量的内容内容不同,其肯定不是同一个变量。
然后不同变量,但地址却相同,其肯定不是物理地址。
那是什么呢?
这就是虚拟地址—也就是我们今天要将的进程地址空间。
我们编写代码时所说的地址都是虚拟地址。而我们的数据都是通过虚拟地址—页表—物理地址
这样的映射关系与物理内存产生联系的。如下图-----同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映射到了,不同的物理地址!我们在后面会对这部分做出详细的说明。

二,进程地址空间是怎么设计的?
地址空间本质是一种数据结构,其里面至少要有各个区域的划分,将来要和一个特定的进程相关联。也就是说,每一个进程都会有一个地址空间,因此也就有了上述例子中地址相同的情况。
区域划分本质就是在一个范围里定义start和end。
我们的程序在编译时,编译器就形成了地址空间中的各个区域,并且采用和内核中一样的编址方式,给每一行代码,每一个变量都进行了编制。所以在程序编译时,每一个字段就已经有了虚拟地址。只有当程序加载到内存中,其才会有物理地址。地址空间,页表最开始的数据则是由磁盘给的。
那么操作系统是如何管理地址空间的呢?
我们直到OS是通过PCB来管理进程的,每个进程都有一个独立的地址空间,我们前面一直提到的管理方式:先描述,后组织。对于地址空间的管理也是一样的,我们将其组织成为一种数据结构,在PCB中会有一个指向地址空间的指针mm_struct。OS通过这个指针就可以间接的对进程的地址空间进行管理。三,为什么要有进程地址空间?
原因一:
对于物理内存来,它是可以任意进行读写的,因此若没有地址空间,用户直接对内存进行操作,则会引起安全问题。凡是非法的访问或映射,OS都会识别到,并且终止掉这个进程(也就是说:所有的进程奔溃就是进程的退出)地址空间和页表是由OS创建的,所以凡是想要通过地址空间和页表进行映射,都要在OS的监控下,那么就保护了物理内存中的数据的安全。原因二:
因为有了地址空间,我们的物理内存和进程之间就可以分开管理,完成解耦合。
我们在编程时所说的申请空间(new,malloc)都是在地址空间中申请,所以我们采用延迟分配的策略,来提高效率,只有我们的程序真正对物理内存进行访问时,才会给你申请物理内存。也就是说,使用地址空间可以提高整机效率。原因三:
物理内存在理论上可以在任意位置加载,那么在物理内存中的所有数据和代码也都是混乱的。
有了页表的存在,可以将虚拟地址和物理地址之间进行映射,那么在进程视角,内存分布就时有序化的。因为由地址空间和页表的存在,每个进程都认为自己拥有全部的空间,并且各个区域是有序的,通过页表映射到物理内存不同的区域,实现进程的独立性。补充知识:
- 什么是挂起?
加载的本质就是创建进程,但创建好的进程,不是必须把代码和数据马上加载到内存中,并创建内核数据结构(task_struct)。在极端情况下:可能只有内核结构被创建出来了。因此理论上可以对程序进行分批加载。既然可以分批加载,那么就可以分批换出—当一个进程短时间不再执行----例如阻塞,那么其数据和代码就会被换出,这就叫做挂起。 - 页表在映射时不仅仅能映射内存,磁盘也可以进行映射。
- 读时共享:即不涉及写操作时,子进程并不会复制父进程的地址空间,而是和父进程共享一块地址空间。
- 写时拷贝:父进程执行部分和子进程执行部分都会对某一变量进行操作,但是父进程和子进程对这个变量的操作是独立的、互不相干的,此时便需要子进程复制父进程的地址空间,然后父、子进程在各自空间中对这个变量进行操作。这样做可以提高内存的使用效率。
- 父进程和子进程在执行的过程中是交替执行的,执行的先后顺序是不确定的,当一方的时间片执行结束后,便会执行另一方。
-
相关阅读:
注意力机制及代码实现
c# sqlsugar,hisql,freesql orm框架全方位性能测试对比 sqlserver 性能测试
SwiftUI 4.0:两种方式实现子视图导航功能
Socket网络编程练习题四:客户端上传文件(多线程版)
2023年系统规划与设计管理师-第三章信息技术服务知识
【Flink状态管理五】Checkpoint的设计与实现
【错误记录】安装 Hadoop 运行环境报错 ( Error: JAVA_HOME is incorrectly set. Please update xxx\hadoop-env.cmd )
contos7 设置mongodb需账号密码访问
知到测试---大学生心理健康教育
JSD-2204-(业务逻辑开发)-开发分类功能-分页查询-Day08
- 原文地址:https://blog.csdn.net/m0_63135219/article/details/133240057
