-
【23-24 秋学期】NNDL 作业2
第二章课后题
习题 2-1分析为什么平方损失函数不适用于分类问题,交叉损失函数不适用于回归问题
损失函数的作用是衡量预测值和真实值之间的差异。
(1)平方损失函数不适用分类问题的原因:
如下图所示,平方损失函数会对预测值与真实值之间的差值进行平方。
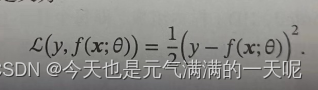
但是分类问题的标签通常是离散的,如0或1。可以发现,分类问题的预测值和真实值之间的差异只跟类别有关,那么使用平方损失函数对分类问题没有意义。
举个例子,比如3分类问题,标签设为0,1,2。如果使用平方损失函数后,类别0被预测为1的差异小于类别0预测为2的差异;但是类别0被预测为1或者2没有区别都是预测错误。
(2)交叉熵损失函数不适用于回归问题的原因:
如下图所示,交叉熵损失函数的公式为:

在下图中可以看到,
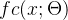 表示输出类别标签的条件概率分布,而
表示输出类别标签的条件概率分布,而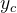 是样本的真实条件概率分布。对两个概率分布可以用交叉熵表示之间的差异。
是样本的真实条件概率分布。对两个概率分布可以用交叉熵表示之间的差异。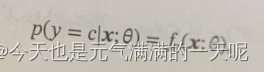
可以发现,当两个分布相同时,值为0;两个概率分布不同时,值大于0。可以看出,交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度。
我们使用交叉熵的目的是为了让交叉熵最小,预测值与真实值相符合。此时我们更关注的是分类正确的预测结果,但是回归问题中不仅需要得到更多的正确分类,也需要平均错误分类。
同时,交叉熵损失函数要求真实标签是离散的,而在回归问题中的真实值通常是连续的,不是离散的,所以并不适合。
习题2-12
对于一个三分类问题 ,数据集的真实标签和模型的预测标签如下。分别计算模型的精确率、召回率、F1值以及它们的宏平均和微平均(格式要求:使用公式编辑器。)
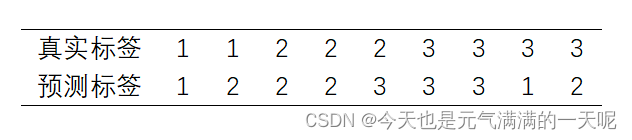
(1)已知条件
混淆矩阵如下:
混淆矩阵 预测类别 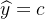
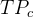
真实类别 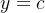
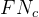
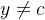
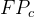
查准率公式:
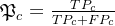
查全率公式:
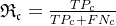
F1值公式(其中
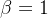 ):
):宏平均:
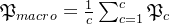
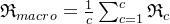
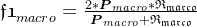
微平均是将各个混淆矩阵对应元素平均,得到TP、FP、TN、FN,然后计算相应的平均值。其计算公式如下:
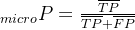
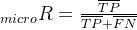
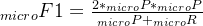
(2)求解
首先算出混淆矩阵中的值可得:
当c=1时:
预测类别 真实类别 1 1 1 6 当c=2时:
预测类别 真实类别 2 1 2 4 当c=3时:
预测类别 真实类别 2 2 1 4 求解查准率
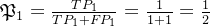
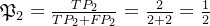
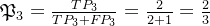
求解查全率:
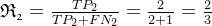
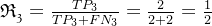
求解F1值:
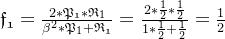
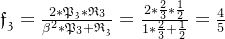
宏平均:
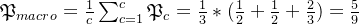
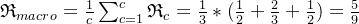
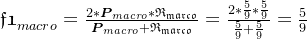
微平均:
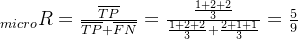
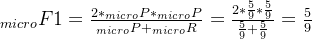
-
相关阅读:
Rust常用特型之Deref和DerefMut特型
OpenCV(二十四):可分离滤波
4.7 wait notify - 4.11 多把锁
计算机毕业设计django基于python图书馆借阅系统
c语言基础知识点(一)C语言中的指针运算和数组名的特性
java计算机毕业设计高原特色农产品网站设计源码+mysql数据库+系统+lw文档+部署
第七章《Java的异常处理》第4节:throw与throws关键字
面试经典-MySQL篇
C++面向对象程序设计(第2版)第五章(继承与派生)知识点总结
Anniversary party(树形dp 基础题)
- 原文地址:https://blog.csdn.net/weixin_61838030/article/details/133145332