-
保研CS/软件工程/通信专业问题汇总(搜集和自己遇到的)
机器学习
1.TP、TN、FP、FN、F1

2.机器学习和深度学习的区别和联系
- 模型复杂性:深度学习是机器学习的一个子领域,其主要区别在于使用深层的神经网络模型。深度学习模型通常包含多个隐层,可以学习更加复杂的特征表示,因此在某些任务上表现更好。
- 特征学习:在传统机器学习中,特征提取是一个重要且需要专业知识的步骤。而在深度学习中,模型可以从数据中学习到更抽象、高级的特征表示,无需太多人工干预。
- 数据需求:深度学习通常需要更大量的数据来训练,因为复杂的神经网络模型需要大量参数来捕捉数据的细微变化。相比之下,一些传统的机器学习算法可能在小数据集上也能表现良好。
- 计算资源:深度学习的训练通常需要更大的计算资源,尤其是在大型神经网络和复杂任务上。这是因为深度学习模型的训练需要大量的计算和存储资源。
- 泛化能力:深度学习模型在大规模数据集上训练时具有出色的泛化能力,可以在未见过的数据上表现良好。然而,当训练数据有限时,传统机器学习方法也可能更具优势。
3.1x1的卷积有什么用途
添加非线性特性
对通道数实现升维/降维
实现跨通道的信息交互与整合
1x1卷积(Conv 1*1)的作用_1*1卷积的作用_犬冢紬希的博客-CSDN博客
- 通过控制卷积核个数实现升维或者降维,从而减少模型参数
- 对不同特征进行归一化操作
- 用于不同channel上特征的融合
4.说一下梯度爆炸和梯度消失的解决办法
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。
两种情况下梯度消失经常出现,一是在深层网络中,二是采用了不合适的损失函数,比如sigmoid。梯度爆炸一般出现在深层网络和权值初始化值太大的情况下
解决方法:
- - 预训练加微调
- - 梯度剪切、权重正则(针对梯度爆炸)
- - 使用不同的激活函数
- - 使用batchnorm
- - 使用残差结构
- - 使用LSTM网络
5.介绍下梯度下降法和牛顿迭代法寻找极值的过程


从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
6. 什么是卷积,什么是卷积神经网络
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的卷积操作,也是卷积神经网络的名字来源。
卷积神经网络(CNN),是一种专门用来处理具有类似网格结构的数据的神经网络。卷积网络是指那些至少在网络的一层中使用卷积运算来替代一般的矩阵乘法运算的神经网络。
7.什么是神经网络?
神经网络是机器学习中的一种算法,其灵感来源于生物神经系统,如大脑中的神经元网络。神经网络由多个节点(或称为“神经元”)组成,这些节点通过连接(通常称为“权重”)相互连接。
神经网络的基本组成单位是人工神经元,也称为节点或神经元。每个神经元都有多个输入和一个输出,输入通过带有权重的连接传递给神经元,神经元对输入进行加权求和,并经过一个激活函数处理后输出结果。
8.过拟合问题
- 增加数据、添加噪声
- early stooping
- 数据均衡(过采样、将采样)
- 数据增强
如图像中的平移、旋转、缩放。原理:通常使用CNN实现图像分类,而CNN只关注提取到的特征是什么,而不会在意空间位置,特征之间的相互关系,所以平移、旋转、缩放后的图像对于CNN来说是一种新的物体,就相当于间接扩充了数据量。
- 正则化
正则化:常见的正则化参数有L1和L2范数L1范数惩罚项的目的是将参数的绝对值最小化。
在固定的网络中,使用L1范数会趋向于使用更少的参数,而其他的参数都是0,从而增加网络的稀疏性,防止过拟合,也叫做Lasso回归。服从拉普拉斯分布。
L2范数惩罚项的目的是将参数的平方和最小化。利用L2范数会使用更多的参数,但这些参数都会接近于0,防止模型过拟合,也叫做Ridge回归。服从高斯分布。
- Dropout
- Batch normolization
9.随机森林(Random Forest,简称RF)算法
集成算法分类
- 模型之间彼此存在依赖关系,按一定的次序搭建多个分类模型,一般后一个模型的加入都需要对现有的集成模型有一定贡献,进而不断提高更新过后的集成模型性能,并借助多个弱分类器搭建出强分类器。(Boosting)
- 模型之间彼此不存在依赖关系,彼此独立。利用相同的训练数据同时搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数的原则做出最终的分类决策。(Bagging)
常见调参:
n_estimators:森林中决策树的个数,默认是10
criterion:度量分裂质量,信息熵或者基尼指数
max_features:特征数达到多大时进行分割
max_depth:树的最大深度
min_samples_split:分割内部节点所需的最少样本数量
bootstrap:是否采用有放回式的抽样方式
min_impurity_split:树增长停止的阀值随机森林是一种集成算法。它首先随机选取不同的特征(feature)和训练样本(training sample),生成大量的决策树,然后综合这些决策树的结果来进行最终的分类。
10.决策树算法和常见决策树算法?
决策树是一个自顶向下的树形分类模型,包括节点和有向边。其中,节点包括内部节点和叶子节点,内部节点描述特征,叶子节点表示类别。基本思想:样本聚集在根节点处,根据根节点特征划分到不同的子节点中,再根据子节点进行划分,直到所有样本划分到对应的叶子节点中。
决策树主要包括特征选择和剪枝。
常见决策树算法:
ID3:最大信息增益。缺点:对可取值数目较多的特征有所偏好。
C4.5:增益率。缺点:对可取值数目较少的特征有所偏好。一般从信息增益高于平均水平的特征中,再找信息增益比高的特征。
CART(分类和回归树):基尼指数,反映了从数据集中随机选取两个样本,其类别标记不一致的概率。
11.降维
PCA(无监督)
PCA(主成分分析):线性、非监督、全局降维算法。
基本思想:数据在主轴上的投影的方差最大化。

算法流程
算法:①对所有样本进行中心化处理②计算样本的协方差矩阵③对协方差矩阵作特征值分解④取最大d个特征值的特征向量。
缺点:PCA没有考虑数据的标签,降维后的不同类别的数据会混合在一起,因此降维后的分类效果可能较差。
LDA(有监督)
基本思想:最大化类间距离,最小化类内距离。

12.常见的优化算法
1.梯度下降法
---BGD(批量梯度下降)--->每一步迭代都需要遍历所有的样本数据,消耗时间长,但是一定能得到最优解.
---SGD(随机梯度下降)--->迭代速度快,得到局部最优解(凸函数时得到全局最优解)
---MBGD(小批量梯度下降)--->小批量梯度下降法
2.牛顿法和拟牛顿法
3.共轭梯度法(Conjugate Gradient)
4.启发式的方法
5.解决约束的方法---拉格朗日乘子法
13.优化问题
凸函数优化问题:凸函数的极值点唯一,极值点就是全局最优点。

非凸函数优化问题:非凸函数的极值点不一定,存在局部最优点。

14.SVD奇异值分解
奇异值分解(Singular Value Decomposition)是线性代数中一种重要的矩阵分解,是特征分解(矩阵必须为方阵)在任意矩阵上的推广。奇异值分解是一个适用于任意矩阵的一种分解的方法。
奇异值分解在统计中的主要应用为主成分分析(PCA),一种数据分析方法,用来找出大量数据中所隐含的“模式”,它可以用在模式识别,数据压缩等方面。PCA算法的作用是把数据集映射到低维空间中去。数据集的特征值(在SVD中用奇异值表征)按照重要性排列,降维的过程就是舍弃不重要的特征向量的过程,而剩下的特征向量组成的空间即为降维后的空间。




计算机网络
1. TCP和UDP区别
UDP
无连接的非可靠传输层协议
向上提供一条不可靠的逻辑信道
面向报文流
TCP
面向连接的传输控制协议
向上提供一条全双工的可靠逻辑信道
面向字节流
拥塞避免( 慢开始、拥塞避免、快重传、快恢复 )

2. 三次握手、四次挥手


3. 计算机网络为什么要分层?优点?
为了降低协议设计的复杂性,网络体系采用层次化结构,每一层都建立在其下层之上,每一层的目的是向其上一层提供一定的服务,把服务的具体事项细节对上层屏蔽。
分层可以带来如下好处:
(1)各层之间是独立的
(2)灵活性好
(3)易于实现和维护
(4)结构上可分割开
(5)能促进标准化工作。
4. OSI 7层结构各自的作用?
1)物理层:主要负责将数字信号转换为物理信号,并在网络中进行传输,如电缆、光缆、中继器、集线器等。
2)数据链路层:在物理层之上,以帧为单位传输数据,具体功能有误码检测、帧同步、流量控制、差错控制等。
3)网络层:在数据链路层之上,负责数据的路由和转发,实现主机之间的通信,如IP地址的分配和路由的计算等。
4)传输层:负责端到端的数据传输,为应用层提供可靠的数据传输服务,例如TCP协议和UDP协议等。
5)会话层:负责建立、管理和结束会话,实现应用程序之间的通信以及数据的传输与共享。
6)表示层:负责数据格式的转换,使得不同的系统能够互相理解,并将数据转换成应用程序能够识别的格式。
7)应用层:为用户提供特定的应用服务,包括电子邮件、网页浏览、文件传输等。
5.计算机网络TCP/IP 四层模型

6.在浏览器中输入http://www.baidu.com后执行的全部过程
- DNS解析,查找真正的ip地址
- 与服务器建立TCP连接
- 发送HTTP请求
- 服务器处理请求并返回HTTP报文
- 浏览器解析渲染页面
- 连接结束
7.网络中主机通信过程
1.主机A和主机B在同一个二层网络,直接走二层交换

2.主机A和主机B不在同一个网络中,走三层路由

8.流量控制和拥塞是什么关系?
拥塞控制目的是防止数据过多注入到网络中导致网络资源(路由器、交换机等)过载。
流量控制目的是接收方通过TCP头窗口字段告知发送方本方可接收的最大数据量,用以解决发送速率过快导致接收方不能接收的问题。所以流量控制是点对点控制。

9.域名系统DNS?
域名系统(Domain Name System缩写 DNS)是因特网的一项核心服务,它作为可以将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。一个公司的 Web 网站可看作是它在网上的门户,而域名就相当于其门牌地址,通常域名都使用该公司的名称或简称。例如:IBM 公司的域名是 http://www.ibm.com、Oracle 公司的域名是 http://www.oracle.com。
10.IP地址分类?
IP地址分A,B,C,D,E五类:
A类地址以0开头,第一个字节作为网络号,地址范围为:0.0.0.0~127.255.255.255;
B类地址以10开头,前两个字节作为网络号,地址范围是:128.0.0.0~191.255.255.255;
C类地址以110开头,前三个字节作为网络号,地址范围是:192.0.0.0~223.255.255.255。
D类地址以1110开头,地址范围是224.0.0.0~239.255.255.255,D类地址作为组播地址(一对多的通信);
E类地址以1111开头,地址范围是240.0.0.0~255.255.255.255,E类地址为保留地址,供以后使用。
注:只有A,B,C有网络号和主机号之分,D类地址和E类地址没有划分网络号和主机号。
11.ipv4和ipv6的区别?

计算机视觉
1.反卷积的定义和作用?
定义:
反卷积也称为转置卷积,如果用矩阵乘法实现卷积操作,将卷积核平铺为矩阵,则转置卷积在正向计算时左乘这个矩阵的转置WT,在反向传播时左乘W,与卷积操作刚好相反,需要注意的是,反卷积不是卷积的逆运算。
作用:
2.空洞卷积的作用?
空洞卷积

作用
1、扩大感受野。但需要明确一点,池化也可以扩大感受野,但空间分辨率降低了,相比之下,空洞卷积可以在扩大感受野的同时不丢失分辨率,且保持像素的相对空间位置不变。(池化就是取出一个区域的代表像素,然后做卷积)简单而言,空洞卷积可以同时控制感受野和分辨率。
2、获取多尺度上下文信息。当多个带有不同卷积扩张率dilation rate的空洞卷积核叠加时,不同的感受野会带来多尺度信息,这对于分割任务是非常重要的。
3、可以降低计算量,不需要引入额外的参数,如上图空洞卷积示意图所示,实际卷积时只有带有红点的元素真正进行计算。数据结构
1.排序算法时间复杂度

2. 分治法与动态规划异同
相同点:都要求原问题有最优子结构(即问题的最优解包含子问题的最优解),都是将问题分而治之地分解成若干规模较小的子问题,对子问题求解。
不同点:分治法是自顶向下求解子问题,合并子问题的解,从而得到原问题的解;动态递归是自底向上,先求解最小的子问题,把结果存在表格中,在求解大的子问题时,直接从表格中查询小的子问题的解,避免重复计算。
3.简述数据结构的定义和组成
数据结构包括三个方面:逻辑结构,存储结构和数据的运算
存储结构:顺序存储,链式存储,索引存储,散列存储
4.算法的五个重要的特征
(1)有穷性:一个算法必须在有限的步骤和有限的时间内完成
(2)确定性:相同的输入只能得出相同的输出
(3)可行性:算法是可行的
(4)输入:一个算法有0个或者多个的输入
(5)输出:一个算法有0个或者多个的输出
5.数组和链表的区别(比较经典的问题)
(1)物理存储结构不同:数组是顺序存储结构,链表是链式存储结构
(2)内存分配方式不同:数组的存储空间一般采用静态分配;链表的存储空间一般采用动态分配
(3)元素的存取方式不同:数组元素为直接存取,链表元素的存取需要遍历链表
(4)元素的插入和删除方式不同:数组在进行元素插入和删除时,需要移动数组的元素,而链表在进行元素插入和删除时无需移动链表内的元素
6.什么是算法的稳定性?
稳定的排序算法就是序列中两个相同的数字在排序前后位置顺序未改变。
7.O(n) 的大O是什么意思?什么是时间复杂度?
 含义:大 表示同阶,同等数量级
含义:大 表示同阶,同等数量级时间复杂度: 时间复杂度是算法执行时间的度量。算法的时间复杂度又称为算法的渐进时间复杂度,它表示随着问题规模
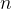 的增大,算法执行时间的增长率和
的增大,算法执行时间的增长率和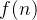 的增长率相同。其中, 表示基本语句重复执行的次数是问题规模的某个函数。
的增长率相同。其中, 表示基本语句重复执行的次数是问题规模的某个函数。8.常用算法速记
抽象数据结构复杂度

排序算法

图操作

操作系统
1.什么是死锁?死锁产生的条件?处理方法?
在两个或者多个并发进程中,如果每个进程持有某种资源而又等待其它进程释放它或它们现在保持着的资源,在未改变这种状态之前都不能向前推进,称这一组进程产生了死锁。通俗的讲就是两个或多个进程无限期的阻塞、相互等待的一种状态。
条件:
互斥条件:一个资源一次只能被一个进程使用
请求与保持条件:一个进程因请求资源而阻塞时,对已获得资源保持不放
不剥夺条件:进程获得的资源,在未完全使用完之前,不能强行剥夺
循环等待条件:若干进程之间形成一种头尾相接的环形等待资源关系
处理方法:
预防死锁——破坏四个必要条件(不剥夺、请求和保持、循环等待)中的一个或多个来预防死锁。
避免死锁——在资源动态分配的过程中,用某种方式防止系统进入不安全的状态。
检测死锁——运行时产生死锁,及时发现死锁,将程序解脱出来。解除死锁——发生死锁后,撤销进程,回收资源,分配给正在阻塞状态的进程。
2.进程的通信方式有哪些?
进程间通信又叫IPC (InterProcess Communication)是指在不同进程之间传播或交换信息。IPC的方式通常有管道(包括无名管道和命名管道)、消息队列、信号量、共享存储、Socket。
(1)管道(pipe)及有名管道(named pipe):管道可用于具有亲缘关系的父子进程间的通信,有名管道除了具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。
(2)信号(signal):信号是在软件层次上对中断机制的一种模拟,它是比较复杂的通信方式,用于通知进程有某事件发生,一个进程收到一个信号与处理器收到一个中断请求效果上可以说是一致的。
(3)消息队列(message queue):消息队列是消息的链接表,它克服了上两种通信方式中信号量有限的缺点,具有写权限得进程可以按照一定得规则向消息队列中添加新信息;对消息队列有读权限的进程则可以从消息队列中读取信息。
(4)共享内存(shared memory):可以说这是最有用的进程间通信方式。它使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。
(5)信号量(semaphore):主要作为进程之间及同一种进程的不同线程之间的同步和互斥手段。
(6)套接字(socket):这是一种更为一般的进程间通信机制,它可用于网络中不同机器之间的进程间通信,应用非常广泛。
3.进程和线程的区别?
线程
线程是CPU调度的最小单元
线程需要的资源更少,可以看做是一种轻量级的进程
线程会共享进程中的内存,线程也有独立的空间(栈、程序计数器)
线程相互通信更加方便
进程
进程是资源分配的最小单元
进程是一系列线程的集合
进程之间是相互独立的,有自己的内存空间
4.换页算法
- OPT(最佳页面置换算法)
- FIFO(先进先出置换算法)
- LRU(最近最久未使用页面置换算法)
- LFU(最少使用页面置换算法)
- CLOCK 时钟置换算法
5.进程有哪些调度算法
- 先来先服务(FCFS)
- 短作业优先(SJF)
- 时间片轮转(RR)
- 优先级调度
6.并发和并行有什么区别?
并发就是在一段时间内,多个任务都会被处理;但在某一时刻,只有一个任务在执行。单核处理器可以做到并发。因为切换速度足够快,所以宏观上表现为在一段时间内能同时运行多个程序。
并行就是在同一时刻,有多个任务在执行。这个需要多核处理器才能完成,在微观上就能同时执行多条指令,不同的程序被放到不同的处理器上运行,这个是物理上的多个进程同时进行。
7.中断的处理过程
- 保护现场:将当前执行程序的相关数据保存在寄存器中,然后入栈。
- 开中断:以便执行中断时能响应较高级别的中断请求。
- 中断处理
- 关中断:保证恢复现场时不被新中断打扰
- 恢复现场:从堆栈中按序取出程序数据,恢复中断前的执行状态。
数学
1.积分的意义?
定积分的几何意义是曲边梯形的有向面积,物理意义是变速直线运动的路程或变力所做的功。
二重积分的几何意义是曲顶柱体的有向体积,物理意义是加在平面面积上压力(压强可变)。
三重积分的几何意义和物理意义都认为是不均匀的空间物体的质量。
2. 如何理解矩阵的秩?
是图像经过矩阵变换之后的空间维度。
是列空间的维度
3. 简述向量组线性无关的含义?
零空间只有零向量,不存在向量可以有其他向量线性表示。
4. 解释正定矩阵以及半正定矩阵?

5. 特征值的含义以及矩阵分解的物理意义?
如果一个向量投影到一个方阵定义的空间中只发生伸缩变化,而不发生旋转变化,那么该向量就是这个方阵的一个特征向量,伸缩的比例就是特征值。
矩阵特征值是对特征向量进行伸缩和旋转程度的度量,实数是只进行伸缩,虚数是只进行旋转,复数就是有伸缩有旋转。

6.行列式的意义?
维平行多面体的体积,每条边就对应了矩阵的列。若行列式为0,意味着矩阵的秩小于0,相当于这个多面体的体积在维空间中坍缩为0。7.主成分分析?
一种数据降维方法,利用正交变换将高维变量转化为低维变量,使得变量之间的关联尽可能小,新变量的方差尽可能大。
首先对数据集 X 进行去中心化,即每一维特征减去各自的平均值,之后计算协方差矩阵,并求解出协方差矩阵的特征值和特征向量。之后对特征值从大到小排序,选择最大的 k 个,将对应的特征向量张成为特征向量矩阵 P 。最后将原数据利用线性变换矩阵 P 映射到新的空间中,形成降维后的数据特征。
8. 大数定律、中心极限定理?
切比雪夫大数定律:对于相互独立的随机变量序列,其方差存在且有公共上界,则当样本数量不断增大时,样本均值将无限接近于随机变量的数学期望。即:用样本均值来估计数学期望。
伯努利大数定律:独立重复实验的次数足够多的时候,事件发生的概率无限接近于事件发生的频率除以总次数,即:用频率估计概率。
中心极限定理:对于随机采样的随机变量序列而言,若样本数量足够大的时候,样本分布无限接近于正态分布。
9. 协方差和相关系数
协方差:反映两个随机变量之间的联合变动程度,衡量两个变量的线性相关性程度。
相关系数:研究变量之间线性相关程度的量,相当于是无量纲的协方差,将协方差进行了归一化。
10.线性代数的线性相关怎么理解?
线性代数:这些向量中存在一个或多个向量可以由其他向量线性表示,即不是正交关系,简单理解就是线性相关实际上是一种冗余。
从零空间的角度看:
如果 A 各列向量构成的向量组是线性无关的,那么矩阵 A 的零空间中只有零向量。
如果 A 各列向量构成的向量组是线性相关的,那么矩阵 A 零空间中除零向量之外还一定有其他向量。
11.函数的特性?
有界性,周期性,单调性,奇偶性
12.一个矩阵线性无关的等价定义有什么
非奇异矩阵、矩阵可逆、矩阵满秩、特征值没有 0。(奇异矩阵:行列式等于零的矩阵(方阵)。)
13.等价矩阵?

14.三大中值定理?
公式:



总结:

15.
杂题
1.请简单谈谈你对软件工程的理解。如何看待软件工程领域未来的发展趋势?
软件工程是研究和应用如何以系统性的、规范化的、可定量的过程化方法去开发和维护软件,以及如何把经过时间考验而证明正确的管理技术和当前能够得到的最好的技术方法结合起来。
发展趋势:
1.软件的质量和安全性也越来越受到重视。未来软件工程专业的发展趋势之一就是提高软件质量和安全性。
2. 人工智能和机器学习:人工智能和机器学习正在成为软件工程的重要组成部分,软件工程师需要掌握这些技术来开发具有智能化的软件系统。
3.软件工程的可持续性:软件工程师需要关注软件系统的可持续性,包括软件系统的可维护性、可扩展性、可重用性、可移植性等方面,以确保软件系统能够长期稳定地运行。
2. 面向对象和面向过程的区别
面向对象:把整个需求按照特点、功能划分,将这些存在共性的部分封装成对象。容易维护、复用和扩展,但消耗资源,性能低。
面向过程:分析出实现需求所需的步骤,通过函数一步一步实现这些步骤,接着依次调用。易性能好,但不易维护、复用和扩展。
-
相关阅读:
“深入理解Nginx的负载均衡与动静分离“
如何将html转化为pdf
【ICer的脚本练习】tcl语法熟悉和工具tcl的实例
手机储存快满了,怎么备份手机图片和视频到电脑上?
适用于C/C++开发人员的HOOPS
【PyTorch】3-基础实战(ResNet)
QMenu的基本使用:实现右键弹出菜单栏
474. 一和零
C语言参悟-函数
以工单为核心的MES管理系统功能设计
- 原文地址:https://blog.csdn.net/weixin_52261094/article/details/133187419