-
YashanDB混合存储揭秘:行式存储如何为高效TP业务保驾护航(下)
上一篇文章https://mp.weixin.qq.com/s/mQLzi2PSZxqwwACSsq49ng为大家讲述了行式存储中事务并发控制的关键设计和优化。YashanDB采用了In-place Update 的块级 MVCC,能极大提高事务并发处理能力。本篇文章,我们将会详解插入性能优化和宽行存储的设计。
插入性能优化
YashanDB行式存储主要从提供并发度、批量化处理以及减少日志产生三方面对事务处理过程中的插入性能进行了优化:
1
提高并发度
单线程插入的速度是有限的,在资源充足的场景下,我们希望通过增加线程来提高导入数据的速度。由于数据块不能同时写入,如果两个线程要在同一个数据块上插入数据,就会产生等待。因此我们希望多个线程插入数据的时候,尽量离散到不同的数据块上。
YashanDB对空闲空间管理进行了深度优化,通过引入多候选数据块机制,减少了空间搜索次数,有效提升了并发场景下的空闲空间查找效率。通过数据块智能分配机制,将数据块根据不同实例、不同会话进行散列,降低数据块冲突,有效提升了并发度。
2
批量插入
如果插入数据时,选择一条一条插入会产生多次重复工作,每插入一条数据,就要写一次数据块、一条Redo、一条Undo, 因此我们将多行数据合并,一次写入数据块,同时合并Redo、 Undo,减少写操作的次数,Redo、Undo合并也可以减少Redo/Undo的头信息占用的空间。
3
Nologging
YashanDB通过记录Redo日志来保证事务持久性,通过记录Undo日志来实现事务并发控制,但是对于离线数据迁移场景,数据完整性可以通过其他机制保证,但如果继续产生大量的Redo和Undo对迁移的性能影响非常严重。
对于这种场景,YashanDB提供了一种简单高效的Nologging导入方式,极大的减少了Redo和Undo产生量,并通过全量检查点保证数据的持久性。
行存储结构
YashanDB的单行最大长度远大于单个数据块的大小,因此需要将单行存储在不同的数据块上。同时在update操作时,原始的行有可能会变长,导致当前数据块没有足够的存储空间,需要分配分配新的空间。YashanDB针对宽行设计了行链接、行迁移机制:
1
行迁移
当行数据经过Update变大,有可能行所在数据块的空闲空间不足,需要将行数据迁移到另一个数据块,原位置保留一个行头。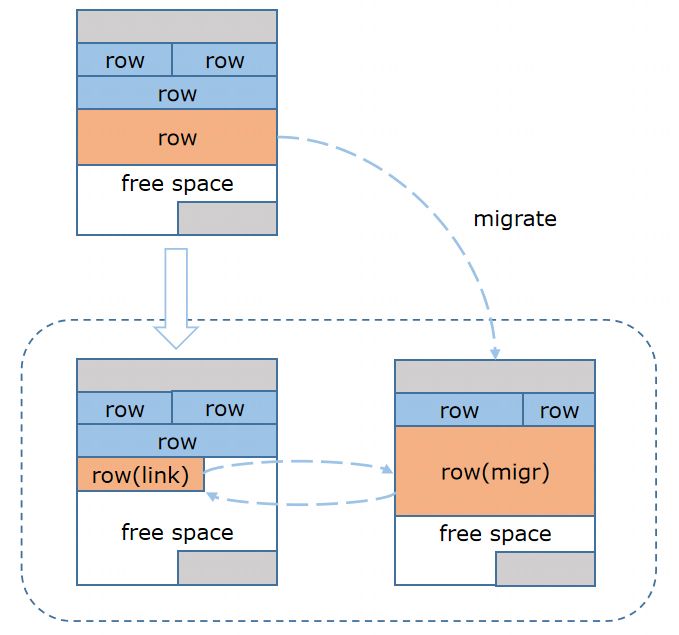
图4 行迁移机制
2
行链接
当行长度超过单个数据块的最大容量时会将行切分成多个分片,存储在不同的数据块上。
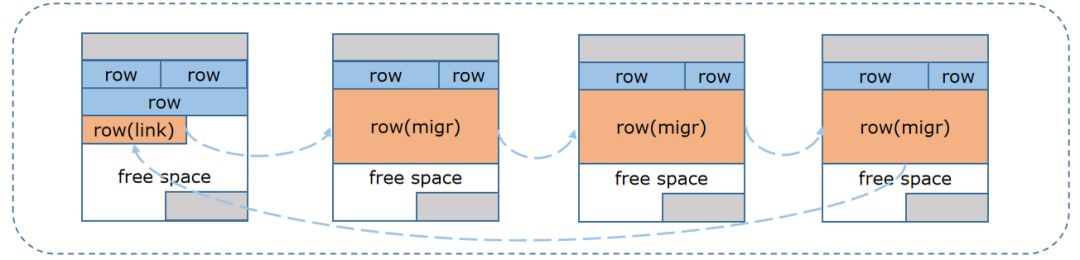
图5 行链接机制
行的每个分片可以单独修改,分片在行数据发生变化后,也可以自动收缩,这样在操作宽行时可以按需访问,有效 保证了宽行数据的访问处理性能。
总结
YashanDB采用了细粒度并发控制、免锁事务优化等先进技术,进行了高效的行式存储设计,能够实现快速查询、数据一致性以及高效的数据访问,这对于数据库系统的性能和可靠性具有极其重要的意义。
未来YashanDB将从数据压缩、数据分层存储、行列混合计算等方面优化行式存储能力,进一步提升数据库事务处理能力以及混合负载能力,降低数据存储成本,提高数据处理性能。 -
相关阅读:
STM32F334timer6-7
【c语言】详解结构体
让开发者成为决定性力量,华为开发者英雄汇圆满落幕
整理了200多个Python实战案例,都有完整且详细的教程
一点整理
重学前端——事件循环
canvas画布绘图
1446_TC275 DataSheet阅读笔记7_部分管脚功能的梳理
企业物流管理数据仓库建设的全面指南
电脑翻译软件哪个好-免费的电脑翻译软件
- 原文地址:https://blog.csdn.net/cod0410/article/details/133162071