-
【操作系统笔记十三】Shell脚本编程
什么是 shell
shell 就是命令解释器,用于解释用户对操作系统的操作,比如当我们在终端上执行 ls ,然后回车,这个时候会由 shell 来解释这个命令,并且执行解释后的命令,进而对操作系统进行操作。
在 Centos 操作系统中支持多种 shell,我们可以通过下面的命令来查看一个操作系统支持的 shell :
cat /etc/shells- 1
但是 Centos 7 默认的 shell 是 bash,也是在 Centos 系统中常用的 shell。
当我们在终端上执行命令,这个命令就是通过 bash shell 来解释执行的,实际上,当我们打开一个终端实际上也就是打开一个 bash 进程,可以通过 ps 来验证,如下:
ps -f ## 输出如下: UID PID PPID C STIME TTY TIME CMD root 2531 2527 0 14:58 pts/1 00:00:00 -bash root 2566 2531 0 15:14 pts/1 00:00:00 ps -f- 1
- 2
- 3
- 4
- 5
- 6
以上 PID 为 2531 就是进程 bash 的 pid。所以我们在这个终端上执行的任何命令都会被 bash shell 进行解释执行。
什么是 shell 编程
在 Linux 操作系统中,有一个非常重要的原则,那就是:一个命令只做一件事情。比如:
## 进入到指定的目录 cd /var ## 查看当前目录下的所有文件 ls ## 查看当前目录所在的文件路径 pwd ## 我们还可以再统计出当前目录的大小 du -sh- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
以上说明了一个命令只做一件事情
那么,现在假设我们需要经常依次执行上面的命令,我们如果每次都去输入上面的 4 个命令的话,那就显的太麻烦了,那么我们可以按照如下的 2 步来解决这个问题:
- 将上面的 4 个命令写到一行中:
cd /var; ls; pwd; du -sh- 1
- 将上面的一行命令保存在一个文件中,一般放 linux 命令的文件的后缀使用
.sh,执行:
vi 1.sh ## 将下面的内容保存到 1.sh 文件名中 cd /var; ls; pwd; du -sh- 1
- 2
- 3
- 4
这样的话,如果你想重复执行上面的 4 个命令的时候,你只需要执行
1.sh文件就可以了,你也可以将这个文件给别人执行。现在要执行上面的文件,我们需要先给脚本赋予执行权限,因为默认的时候文件是没有执行权限的,如下:
chmod u+x 1.sh- 1
我们可以使用
bash命令来执行上面的1.sh文件,如下:bash 1.sh- 1
那么执行上面的命令的结果和上面执行 4 条命令的结果是一样的。
那么上面的
1.sh就是一个 shell 脚本,编写 shell 脚本其实就是 shell 编程。在上面的
1.sh中可以将分号去掉,然后一个命令一行,如下:cd /var ls pwd du -sh- 1
- 2
- 3
- 4
这样效果是一样的。
总结:
- shell 就是命令解释器,对用户输入的命令解释并执行
- shell 脚本就是用户为了完成某一件事,而将多个命令放在一个文件中,然后直接执行脚本文件就可以达到目的。
shell 的执行方式
执行一个 shell 脚本的方式有 4 种:
bash script.sh./script.shsource script.sh. script.sh
我们先写一个名为
2.sh的脚本来对比上面执行脚本的方式的异同点,脚本内容如下:cd /tmp pwd- 1
- 2
bash 命令执行脚本
当我们使用 bash 来执行
2.sh:bash 2.sh- 1
输出如下:

可以看出:
- bash 命令可以执行没有执行权限的脚本
- 当 bash 执行脚本后,当前的目录还是在
/root主目录下,并没有切换到/tmp目录中。 - 这个是因为,当执行 bash 命令的时候,会启动一个新的进程来执行脚本中的命令,所以脚本执行的结果对当前进程是没有影响的
我们在终端上执行
bash命令,然后使用ps -f查看也能验证这点:
以上的进程是执行 bash 命令后出现的进程。而且还能看出这个 bash 进程的父亲进程的 ID 是第一个 bash 进程的 PID。./ 执行脚本
当我们使用
./来执行2.sh:./2.sh- 1
结果输出:
-bash: ./2.sh: Permission denied- 1
发现权限不够,使用这种方式来执行脚本的时候,要求这个脚本要有可执行权限,如下更改脚本的权限:
chmod u+x 2.sh- 1
再次执行脚本,输出如下:

这个输出和使用 bash 命令执行脚本的输出是一样的:- 同样会创建一个新的进程来执行脚本中的内容
- 而且使用这种方式来执行的话,脚本要求有可执行权限
source 和 . 来执行脚本
如下使用
source来执行脚本:source 2.sh- 1
输出如下:

如下使用
.来执行脚本:. 2.sh- 1
输出如下:
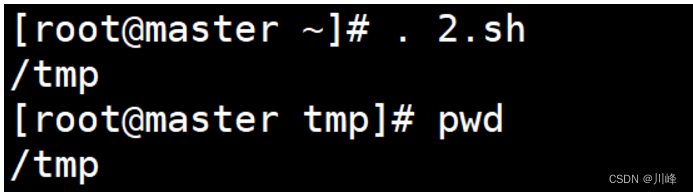
可以看出,以上两种方式执行结果是一样的,而且对当前终端是有影响的,两种执行结果都进入了
/tmp目录,这个可以说明:- 使用
source和.执行脚本的时候不会启动先的进程,只是在当前的 bash 进程中执行脚本内容 - 所以这两种执行脚本的方式在执行脚本的时候会影响当前终端。
变量
变量的定义
在 shell 编程中,有很多时候我们想将数据先临时保存起来,供后续使用,我们可以先将数据保存到某个变量中,如下是将字符串 jeffy 赋值给变量 name :
name=jeffy- 1
注意:等号两边不能有空格
以上就是定义了一个名字为 name 的变量,我们可以通过如下的方式来访问这个变量:
## 在控制台中输出变量 name 的值 echo ${name} ## 以上访问 name 变量也可以简写为: echo $name- 1
- 2
- 3
- 4
- 5
在定义变量的时候,变量名的定义需要遵循下面的规则:
- 由字母、数字、下划线组成
- 不以数字开头
- 变量名一般要求有一定的意义
比如下面的变量名是不推荐使用的:
## 存在非法组成字符 *name=twq ## 以数字开头了 12name=twq ## a 这个变量名没啥意义 a=twq- 1
- 2
- 3
- 4
- 5
- 6
现在如果我们想将 10+20 的结果赋值给一个名为 result 的变量,如下:
result=10+20 echo $result ## 以上输出为 10+20- 1
- 2
- 3
- 4
- 5
- 6
上面的程序并没有达到我们的预期,我们可以在定义变量之前加上一个关键字
let,如下:let result=10+20 echo $result ## 以上输出为 30- 1
- 2
- 3
- 4
- 5
- 6
在有些场景下,变量值中可能会出现空格等其他的特殊字符,我们可以通过双引号或者单引号来解决特殊字符的问题,如下:
## 定义一个名为 content 的变量,将 tom's cat 赋值给 content 变量 ## 以下定义是错误的,因为变量值中有空格 content=tom's cat ## 我们在变量值中加上双引号,如下 content="tom's cat" echo $content ## 如果变量值中有一个双引号的话,则需要使用单引号,比如 content='tom"s cat' echo $content- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
变量和命令
除了数据,我们也可以将一个命令赋值给一个变量,如下:
## 将 ls 命令赋值给变量 l l=ls ## 这样使用: $l- 1
- 2
- 3
- 4
- 5
以上的做法意义不大,在实际生产上,我们一般不会将一个命令赋值给一个变量
为了提高性能,我们一般会将一个命令执行的结果赋值给一个变量,如下:
## 将 ls -l /etc 执行的结果赋值给变量 lsetc : lsetc=$(ls -l /etc) ## 以后想使用 ls -l /etc 的结果的话,我们只需要访问 lsetc 这个变量就可以了 echo $lsetc ## 我们也可以使用 `` 来代替上面的 $() lsetc=`ls -l /etc` echo lsetc- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
变量的拼接
比如,我们先定义一个名为
tmp的临时变量,我们将字符串test赋值给tmp:tmp=test- 1
如果我们想将
tmp中的变量值和字符串twq进行拼接:echo $tmptwq ## 输出为空- 1
- 2
- 3
使用上面的方式是不能进行变量拼接的,以上 tmptwq 被看成了一个变量,然而这个变量并没有赋值,所以输出为空,我们可以通过如下的方式进行变量的拼接:
echo ${tmp}twq ## 输出为: testtwq ## 我们也可以将拼接之后的数据再次赋值给变量 tmp : tmp=${tmp}twq echo $tmp- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
实际上我们可以在使用变量的时候,在变量后面加上一个非数字、非字母、非下划线的字符就可以实现变量的拼接,如下:
echo $tmp:jeffy ## 输出: testtwq:jeffy- 1
- 2
- 3
- 4
我们再定义一个变量:
age=20- 1
然后将
tmp和age变量使用:拼接起来,如下:echo $tmp:$age ## 输出为 testtwq:20- 1
- 2
- 3
- 4
变量的范围
我们现在先定义一个名为
demo_var的变量,这个变量的值是hello shell,如下:demo_var="hello shell" ## 在当前的 bash 进程中是可以访问的,如下: echo $demo_var ## 如果我们再打开一个 bash 进程 bash ## 然后就访问不了了变量了,如下输出为空: echo $demo_var ## 我们再在 bash 子进程中定义一个变量,如下: demo_var="hello subshell" ## 然后退出当前的子 bash 进程 exit ## 在父进程中也访问不了子进程中定义的变量 echo $demo_var ## 以上输出为: hello shell ## 如果我们重新打开一个终端,那也是访问不了上面的进程中的变量- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
从上面的演示,可以得出结论:
- 变量默认的访问范围是当前的 bash 进程
那么我们如果在某个脚本中能不能访问上面的变量呢?我们先创建一个名为
3.sh的脚本,内容就是访问并打印变量demo_var的值,如下:vi 3.sh echo $demo_var ## 保存以上的 2.sh 的脚本文件 ## 给 2.sh 脚本赋予执行权限 chmod u+x 2.sh- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后我们分别使用
bash 2.sh、./2.sh、source 2.sh以及. 2.sh四种方式来执行上面的脚本,发现:- 使用
bash 2.sh、./2.sh这两种方式访问不到变量的值,这个是因为这两种方式都会启动一个子 bash 进程来执行脚本 - 而使用
source 2.sh、. 2.sh这两种方式是可以访问到变量的值,这个是因为这两种方式都是在当前的 bash 进程中执行脚本的
那么我们怎么样使得一个变量可以在子 bash 进程中访问呢?我们可以使用
export关键词将变量导出,然后其他的进程就可以访问这个变量了,如下:## 在定义 demo_var 的 bash 进程中 export 这个变量: export demo_var ## 然后使用四种方式执行 2.sh 脚本时都是可以访问变量的 ## 也就是说变量通过 export 导出后,就可以在子进程中进行访问了。 ## 如果你想取消导出的变量,可以使用关键字 unset 来实现,如下 unset demo_var- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
环境变量及其配置文件
环境变量
所谓的环境变量就是每一个 shell 打开都可以获得到的变量,只要一打开一个终端,就可以访问环境变量。
我们可以通过下面的命令获取到当前用户下当前默认的所有的环境变量:
env- 1
输出为:
XDG_SESSION_ID=8 HOSTNAME=master SELINUX_ROLE_REQUESTED= TERM=xterm SHELL=/bin/bash HISTSIZE=1000 SSH_CLIENT=192.168.126.1 59094 22 SELINUX_USE_CURRENT_RANGE= SSH_TTY=/dev/pts/0 USER=root LS_COLORS=rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=01;05;37;41:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.axv=01;35:*.anx=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=01;36:*.au=01;36:*.flac=01;36:*.mid=01;36:*.midi=01;36:*.mka=01;36:*.mp3=01;36:*.mpc=01;36:*.ogg=01;36:*.ra=01;36:*.wav=01;36:*.axa=01;36:*.oga=01;36:*.spx=01;36:*.xspf=01;36: MAIL=/var/spool/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin PWD=/root LANG=en_US.UTF-8 SELINUX_LEVEL_REQUESTED= HISTCONTROL=ignoredups SHLVL=1 HOME=/root LOGNAME=root SSH_CONNECTION=192.168.126.1 59094 192.168.126.133 22 LESSOPEN=||/usr/bin/lesspipe.sh %s XDG_RUNTIME_DIR=/run/user/0 _=/usr/bin/env- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
上面显示的都是
root用户下的环境变量,变量名都是使用大写来表示的。在以上的环境变量中有几个需要我们关心的环境变量:- USER
## 输出当前用户 echo $USER- 1
- 2
- UID
## 输出当前用户 id echo $UID- 1
- 2
- PATH
## 输出当前用户下的命令搜索路径 PATH 的变量值 echo $PATH- 1
- 2
输出为:
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin- 1
以上路径称为命令搜索路径,当我们执行一个命令,比如
ls、cd等,系统会从上面的路径下分别搜索这个命令对应的脚本文件:- 先搜索
/usr/local/sbin - 再搜索
/usr/local/bin - 再搜索
/usr/sbin - 再搜索
/usr/bin - 最后搜索
/root/bin
如果第一次搜索到了就执行那个目录下的脚本命令,比如当执行
ls命令的时候,系统会依次看/usr/local/sbin下面是否有 ls 脚本文件/usr/local/bin下面是否有 ls 脚本文件/usr/sbin下面是否有 ls 脚本文件/usr/bin下面是否有 ls 脚本文件/root/bin下面是否有 ls 脚本文件
发现
ls在/usr/bin下面,所以最终执行的就是/usr/bin/ls脚本文件:- 实际上执行
ls和/usr/bin/ls的效果是一样的 - 就是因为
/usr/bin在PATH变量中,所以执行ls命令的时候可以省去完整的路径, - 而且你可以在任何的位置上都可以执行
ls命令
比如,我们在
/tmp目录下创建一个名为4.sh的脚本,内容如下:echo "hello bash" du -sh- 1
- 2
然后赋予
4.sh这个文件的执行权限:chmod u+x /tmp/4.sh- 1
我们在
/root目录下可以直接执行./4.sh,可以执行成功,但是如果我们直接使用4.sh来运行的话,是执行不成功的,这个是因为在命令搜索路径中搜索不到/tmp目录下的4.sh,如果我们想直接4.sh执行成功的话,需要将4.sh所在的目录拼接到环境变量PATH中,如下:PATH=$PATH:/tmp echo $PATH- 1
- 2
- 3
输出为:
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/tmp- 1
现在,就可以在任意的目录中都可以直接执行
4.sh了。以上更改之后的 PATH 对子进程是有效的,但是对于新打开的终端是无效的。
bash shell 的格式
在我们执行 bash 命令的时候,实际上也需要从命令搜索路径中搜索这个 bash 命令所在的路径,然后执行这个命令,我们可以通过
which命令来查看 bash 命令是哪一个路径下的:which bash ## 输出如下: /usr/bin/bash- 1
- 2
- 3
- 4
说明 bash 命令默认使用的是
/usr/bin/bash那么如果使用 bash 命令执行脚本的时候,默认就是使用
/usr/bin/bash这个命令来执行的,那么当我们使用其他方式来执行脚本的时候,到底是使用什么命令来执行脚本的呢?当然,默认的话还是使用
/usr/bin/bash来执行的,但是如果你想指定使用/bin/bash来执行脚本的话,可以在脚本的前面加上一个声明:#!/bin/bash- 1
加了上面的声明后
- 如果使用 bash 命令来执行的话,那么上面的声明就成了注释,使用的还是系统默认的 bash
- 如果使用其他方式来执行脚本的话,那么上面的声明就是告诉使用
/bin/bash来执行这个脚本中的内容
环境变量配置文件
在 Centos 7 中和环境变量相关的配置文件有如下几个:
/etc/profile~/.bash_profile~/.bashrc/etc/bashrc
一般的话我们的环境变量都保存在以上的 4 个配置文件中,那么保存在 /etc 下面的配置文件中的环境变量是所有的用户都可以访问到的,而保存在用户主目录下配置文件中的环境变量只有当前的用户可以访问的
那么对于一些通用的环境变量的话,一般保存在 /etc 文件目录下的配置文件,而对于某个用户特用的则保存在这个用户下的家目录下的配置文件中。
除了以上的区别之外,我们还可以看出以上 4 个文件主要分为两类,一类是
profile,一类是bashrc。那么这个profile主要是用于login shell的,而bashrc主要是用于nologin shell的,接下来我们分别在以上 4 个配置文件中使用echo打印输出一句话,然后看看 4 个配置文件的执行顺序。在文件
/etc/profile中加入:echo "/etc/profile starting"- 1
在文件
/etc/bashrc中加入:echo "/etc/bashrc starting"- 1
在
root家目录下~/.bashrc下加入:echo "~/.bashrc starting"- 1
在
root家目录下~/.bash_profile中加入:echo "~/.bash_profile starting"- 1
在
user1家目录下~/.bashrc下加入:echo "user1 ~/.bashrc starting"- 1
在
user1家目录下~/.bash_profile中加入:echo "user1 ~/.bash_profile starting"- 1
现在我们做以下的实验:
- 重启客户端,重新连接终端,发现执行顺序是:
/etc/profile starting ~/.bash_profile starting ~/.bashrc starting /etc/bashrc starting- 1
- 2
- 3
- 4
su - user1
/etc/profile starting user1 ~/.bash_profile starting user1 ~/.bashrc starting /etc/bashrc starting- 1
- 2
- 3
- 4
su - root
/etc/profile starting ~/.bash_profile starting ~/.bashrc starting /etc/bashrc starting- 1
- 2
- 3
- 4
su user1
user1 ~/.bashrc starting /etc/bashrc starting- 1
- 2
su root
~/.bashrc starting /etc/bashrc starting- 1
- 2
接下来对上面进行总结:
login shell的执行顺序:/etc/profile -> ~/.bash_profile -> ~/.bashrc -> /etc/bashrcnologin shell的执行顺序:~/.bashrc -> /etc/bashrc
现在为了使得在任何的终端上都可以执行
4.sh,我们重新打开一个终端,然后将环境变量写入到配置文件~/.bash_profile中,如下:PATH=$PATH:$HOME/bin:/tmp- 1
修改配置后,还不能直接执行
4.sh,因为更改后的配置在当前的 bash 进程不生效,如果我们想使得配置在当前的 bash 进程中生效的话,可以执行命令:source .bash_profile- 1
这样就可以在
root的任意目录下执行4.sh了,如果你想在其他的用户的任意目录中执行4.sh的话,可以在/etc/profile的配置中增加配置:PATH=$PATH:/tmp- 1
预定义变量和位置变量
预定义变量
常见的预定义变量包括:
$?、$$、$0$?表示判断上一条执行的命令是否正常执行,如果$?返回的值是0的话,则表示上一条命令是正常执行成功,否则表示上一条命令执行失败
ifconfig echo $? ## 返回 0 ## 查询一个不存在的网卡 ifconfig em echo $? ## 返回 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
$$表示返回当前进程的PID
echo $$- 1
$0表示返回当前进程的名称
echo $0- 1
创建一个
5.sh的脚本,脚本内容如下:#!/bin/bash # 显示 PID 和 PName echo $$ echo $0- 1
- 2
- 3
- 4
- 5
给脚本赋值权限:
chmod u+x 5.sh ## 分别使用两种方式来执行脚本 ## 1. 使用 bash bash 5.sh ## 2. 使用 . 来执行 . 5.sh ## 第二种方式输出的进程号和进程名是当前的 bash 进程的- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
位置变量
位置变量用于给脚本传递参数的变量。我们可以给一个脚本传递任意多的参数:
$1表示第一个参数$2表示第二个参数$3表示第三个参数- …
${10}表示第十个参数${11}表示第十一个参数- …
我们现在写一个脚本
6.sh,如下:#!/bin/bash # Program: # Program shows the script name, parameters... first=${1} second=${2} echo "The script name is ==> ${0}" echo "The 1st parameter ==> $first" echo "The 2nd parameter ==> $second"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
然后给
5.sh执行权限:chmod u+x 6.sh使用下面的命令执行上面的脚本:
bash 6.sh -a -l- 1
输出如下:
The script name is ==> 6.sh The 1st parameter ==> -a The 2nd parameter ==> -l- 1
- 2
- 3
如果我们我们只传递了一个参数:
bash 6.sh -a- 1
输出为:
The script name is ==> 6.sh The 1st parameter ==> -a The 2nd parameter ==>- 1
- 2
- 3
可以发现第二个参数的值为空了,如果没有传递参数的话,我们可以使用默认值来代替,脚本内容修改后如下:
#!/bin/bash # Program: # Program shows the script name, parameters... first=${1} second=${2-_} echo "The script name is ==> ${0}" echo "The 1st parameter ==> $first" echo "The 2nd parameter ==> $second"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
再此执行脚本:
bash 6.sh -a- 1
输出为:
The script name is ==> 6.sh The 1st parameter ==> -a The 2nd parameter ==> _- 1
- 2
- 3
传递 2 个参数来执行脚本:
bash 6.sh -a -l- 1
输出如下:
The script name is ==> 6.sh The 1st parameter ==> -a The 2nd parameter ==> -l- 1
- 2
- 3
在给脚本传递参数的时候,还有两个预定义变量:
$#表示参数的个数$@表示拿到所有的参数
修改
6.sh脚本如下:#!/bin/bash # Program: # Program shows the script name, parameters... # History: # 2018/03/20 twq first=${1} second=${2-_} echo "The script name is ==> ${0}" echo "Total parameter number is ==> $#" echo "Your whole parameter is ==> '$@'" echo "The 1st parameter ==> $first" echo "The 2nd parameter ==> $second"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
传递 2 个参数来执行脚本:
bash 6.sh -a -l- 1
输出如下:
The script name is ==> 6.sh Total parameter number is ==> 2 Your whole parameter is ==> '-a -l' The 1st parameter ==> -a The 2nd parameter ==> -l- 1
- 2
- 3
- 4
- 5
数组
变量可以存储任意的字符串数据,如果需要存储任意多个具有相同意思的字符串数据的话,我们可以使用数组来存储。
比如,我们定义一个数组用于存储 3 个
ip:ips=(10.0.0.1 10.0.0.2 10.0.0.3)- 1
如果我们想访问数组中所有的元素的话,可以:
echo ${ips[@]}- 1
如果想显示数组的个数的话,可以:
echo ${#ips[@]}- 1
如果想访问指定下标的元素的话可以:
## 访问第一个元素的值 echo ${ips[0]} ## 访问第二个元素的值 echo ${ips[1]}- 1
- 2
- 3
- 4
- 5
数字运算
在 Linux 脚本中支持:
- 赋值运算符
- 算术运算符
赋值运算符很简单,就是使用
=来进行赋值操作。算术运算符支持
+ - * / %这 5 种运算符,我们接下来详细讲解下在 Linux 中怎么来完成算术运算。如果我们想在 shell 脚本中完成将 4 + 5 的结果赋值给一个名为 result 的变量,我们该怎么做呢?
## 直接这样做是不行的 result=4+5 echo result ## 需要使用 expr 这个命令来实现运算 ## 这里需要注意的是 4 + 5 之间必须要有空格 expr 4 + 5 ## 将 expr 命令计算出来的结果赋值给 result 的变量 result=`expr 4 + 5` echo $result- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
expr命令不支持小数的运算除了使用
expr命令,还可以使用双圆括号来进行运算:(( result=4+5 )) echo $result (( result++ )) echo $result- 1
- 2
- 3
- 4
- 5
test 比较
exit
exit命令用于退出脚本的,如果是正常退出的话,exit会返回0,如果是异常退出的话,则exit会返回非0现在我们编写一个
7.sh的脚本,脚本的内容如下:#!/bin/bash pwd exit- 1
- 2
- 3
- 4
执行上面的脚本,发现加不加
exit都是一样的,我们执行 :## 查看脚本返回的值为 0 echo $?- 1
- 2
但是当脚本发生错误的时候,比如执行一个不存在的命令:
#!/bin/bash ppwd exit- 1
- 2
- 3
- 4
这个时候执行脚本报错了:
## 查看脚本返回的值为 127 echo $?- 1
- 2
我们在执行
exit命令的时候,也可以指定脚本退出返回的值,如下:#!/bin/bash pwd exit 127- 1
- 2
- 3
- 4
这个时候不管脚本有没有报错,都返回
127:## 查看脚本返回的值为 127 echo $?- 1
- 2
test 命令
我们使用
man来获取test命令的帮助文档:man test- 1
发现,我们使用
test主要可以做如下的事情:- 测试两个字符串是否相等
- 测试两个整数之间的大小关系
- 测试一个文件是否存在
测试两个字符串是否相等
[root@master ~]# test "abc" = "abc" [root@master ~]# echo $? 0 [root@master ~]# test "abc" = "abcd" [root@master ~]# echo $? 1 [root@master ~]# test "abc" != "abcd" [root@master ~]# echo $? 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注意:
0表示true,非0表示false以上的写法我们还可以这样写:
[root@master ~]# [ "abc" = "abc" ] [root@master ~]# echo $? 0 [root@master ~]# [ "abc" = "abcd" ] [root@master ~]# echo $? 1 [root@master ~]# [ "abc" != "abcd" ] [root@master ~]# echo $? 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
整数大小判断
在判断两个整数的大小的时候,我们使用:
- -eq 表示判断是否等于 (equal)
- -ge 表示判断是否大于等于 (great than or equal)
- -gt 表示判断是否大于 (great than)
- -le 表示判断是否小于等于 (less than or equal)
- -lt 表示判断是否小于 (less than)
- -ne 表示判断是否不等于 (not equal)
[root@master ~]# test 5 -gt 4 [root@master ~]# echo $? 0 [root@master ~]# test 5 -eq 4 [root@master ~]# echo $? 1 [root@master ~]# test 5 -lt 4 [root@master ~]# echo $? 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
以上的判断还可以这样写:
[root@master ~]# [ 5 -gt 4 ] [root@master ~]# echo $? 0 [root@master ~]# [ 5 -eq 4 ] [root@master ~]# echo $? 1 [root@master ~]# [ 5 -lt 4 ] [root@master ~]# echo $? 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果你想用
>、< 、=等这种比较符号的话,需要使用双中括号来实现:[root@master ~]# [[ 5 > 4 ]] [root@master ~]# echo $? 0 [root@master ~]# [[ 5 = 4 ]] [root@master ~]# echo $? 1 [root@master ~]# [[ 5 < 4 ]] [root@master ~]# echo $? 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
测试一个文件是否存在
- 测试一个文件是否存在
[root@master ~]# test -e /etc/passwd [root@master ~]# echo $? 0 [root@master ~]# test -e /etc/passwd2 [root@master ~]# echo $? 1- 1
- 2
- 3
- 4
- 5
- 6
也可以写成:
[root@master ~]# [ -e /etc/passwd ] [root@master ~]# echo $? 0 [root@master ~]# [ -e /etc/passwd2 ] [root@master ~]# echo $? 1- 1
- 2
- 3
- 4
- 5
- 6
- 测试一个文件是否存在,并且这个文件是目录
[root@master ~]# test -d /etc [root@master ~]# echo $? 0 [root@master ~]# test -d /etc/passwd [root@master ~]# echo $? 1- 1
- 2
- 3
- 4
- 5
- 6
也可以写成:
[root@master ~]# [ -d /etc ] [root@master ~]# echo $? 0 [root@master ~]# [ -d /etc/passwd ] [root@master ~]# echo $? 1- 1
- 2
- 3
- 4
- 5
- 6
- 测试一个文件是否存在,并且这个文件是普通文件
[root@master ~]# test -f /etc/passwd [root@master ~]# echo $? 0 [root@master ~]# test -f /etc [root@master ~]# echo $? 1- 1
- 2
- 3
- 4
- 5
- 6
也可以写成:
[root@master ~]# [ -f /etc/passwd ] [root@master ~]# echo $? 0 [root@master ~]# [ -f /etc ] [root@master ~]# echo $? 1- 1
- 2
- 3
- 4
- 5
- 6
多个测试进行逻辑与和逻辑或
[root@master ~]# [[ -f /etc && 5 -gt 4 ]] [root@master ~]# echo $? 1 [root@master ~]# [[ -f /etc || 5 -gt 4 ]] [root@master ~]# echo $? 0- 1
- 2
- 3
- 4
- 5
- 6
也可以写成:
[root@master ~]# [ -f /etc ] && [ 5 -gt 4 ] [root@master ~]# echo $? 1 [root@master ~]# [ -f /etc ] || [ 5 -gt 4 ] [root@master ~]# echo $? 0- 1
- 2
- 3
- 4
- 5
- 6
条件语句 if case while for
if…then
if [ 条件判断式 ]; then 当条件判断式返回 0 的时候,可以进行的命令工作内容 fi- 1
- 2
- 3
写一个脚本来判断当前的用户是否是 root 用户,脚本名为
8.sh,内容如下:#!/bin/bash if [ $USER = 'root' ]; then echo "the current user is root" fi- 1
- 2
- 3
- 4
- 5
if…then…else
if [ 条件判断式 ]; then 当条件判断式返回 0 的时候,可以进行的命令工作内容 else 当条件判断式返回非 0 的时候,可以进行的命令工作内容 fi- 1
- 2
- 3
- 4
- 5
修改脚本
8.sh,内容如下:#!/bin/bash if [ $USER = 'root' ]; then echo "the current user is root" else echo "the current user is not root" fi- 1
- 2
- 3
- 4
- 5
- 6
- 7
if…then…elif…
if [ 条件判断式一 ]; then 当条件判断式一返回 0 的时候,可以进行的命令工作内容 elif [ 条件判断式二 ]; then 当条件判断式二返回 0 的时候,可以进行的命令工作内容 else 当所有条件判断式都返回非 0 的时候,可以进行的命令工作内容 fi- 1
- 2
- 3
- 4
- 5
- 6
- 7
新增
9.sh脚本,脚本内容如下:#!/bin/bash read -p "Please input (Y/N):" yn if [[ "$yn" = "Y" || "$yn" = "y" ]]; then echo "Ok, continue" elif [[ "$yn" = "N" || "$yn" = "n" ]]; then echo "Oh, interrupt!" else echo "not support!!" fi- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
编写一个名为
10.sh的 shell 脚本,shell 脚本中的内容设计为:- 判断传递给脚本的第一个参数的值,如果这个值等于 hello 的话,就显示 “Hello, how are you ?”
- 如果没有任何参数的话,就提示用户必须要使用的参数
- 如果传递的参数不是 hello ,就提醒用户仅能使用 hello 作为参数
#!/bin/bash if [ "$1" = "hello" ]; then echo "Hello, how are you ?" elif [ "$1" = "" ]; then echo "You must input parameters, for exapme > {$0 someword}" else echo "The only parameter is 'hello', for example > {$0 hello}" fi- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
case…esac
case…esac 用来进行选择执行,语法如下:
case $变量名称 in "第一个值") 变量内容等于第一个值的时候执行的程序段 ;; "第二个值") 变量内容等于第二个值的时候执行的程序段 ;; *) 不等于第一个值且不等于第二个值的其他程序执行内容 exit 1 ;; esac- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们可以将上一节课的
10.sh脚本使用case来实现,新建一个名为11.sh的脚本,内容如下:#!/bin/bash case $1 in "hello") echo "Hello, how are you ?" ;; "") echo "You must input parameters, for exapme > {$0 someword}" ;; *) echo "The only parameter is 'hello', for example > {$0 hello}" ;; esac- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
我们在前面管理系统服务的时候,一般我们都使用
service start|stop|restart等来对服务来管理,我们现在也可以自己来写一个service.sh脚本,来默认对服务的启停等管理,脚本内容如下:#!/bin/bash case $1 in "start") echo "service start" ;; "stop") echo "service stop" ;; "restart") echo "service restart" ;; "status") echo "service status" ;; *) echo "Usage : {$0 start|stop|restart|status}" ;; esac- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
while
while的语法是:while [ condition ] do 程序段落 done- 1
- 2
- 3
- 4
以上的说法是:当
condition成立时,就进行循环,直到condition的条件不成立才停止。我们现在来写一个名为
12.sh的脚本,让用户输入yes或者YES的时候才结束程序,否则就一直进行告知用户输入字符串:#!/bin/bash while [[ "$yn" != "yes" && "$yn" != "YES" ]] do read -p "Please input yes/YES to stop this program:" yn done echo "Ok! program stopping"- 1
- 2
- 3
- 4
- 5
- 6
- 7
还有一个循环和
while刚好是相反的,那就是until:until [ condition ] do 程序段落 done- 1
- 2
- 3
- 4
以上的说法是:当
condition不成立时,就进行循环,直到condition的条件成立才停止。我们现在来写一个名为
13.sh的脚本,让用户输入yes或者YES的时候才结束程序,否则就一直进行告知用户输入字符串:#!/bin/bash until [[ "$yn" == "yes" || "$yn" == "YES" ]] do read -p "Please input yes/YES to stop this program:" yn done echo "Ok! program stopping"- 1
- 2
- 3
- 4
- 5
- 6
- 7
练习: 使用
while来计算1到100之和#!/bin/bash s=0 i=0 while [ "$i" != "100" ] do ((i++)) ((s=$s+$i)) done echo "the result is : $s"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
练习: 使用
while来计算1到你输入的数字之和,比如:- 你输入 10 ,就计算 1 到 10 之和
- 你输入 100 ,就计算 1 到 100 之和
- 你输入 1000 ,就计算 1 到 1000 之和
- …
#!/bin/bash read -p "Please input you number :" num s=0 i=0 while [ "$i" != "$num" ] do ((i++)) ((s=$s+$i)) done echo "the result is : $s"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
for
循环遍历指定的值
for var in con1 con2 con3 ... do 程序段 done- 1
- 2
- 3
- 4
比如程序段:
for i in a b c do echo $i done- 1
- 2
- 3
- 4
循环指定范围
如下代码段:
for i in {1..9} do echo $i done- 1
- 2
- 3
- 4
还比如:
for i in $(seq 1 10) do echo $i done- 1
- 2
- 3
- 4
循环目录中的所有文件
filelist=$ (ls /) echo $filelist for filename in $filelist do echo ${filename}_file done- 1
- 2
- 3
- 4
- 5
- 6
- 7
c 语言风格的 for
语法如下:
for (( 初始值; 限制值; 执行步长 )) do 程序段 done- 1
- 2
- 3
- 4
使用上面的
for语句来计算1到100的累加值,先建名为14.sh的脚本,内容为 :#!/bin/bash s=0 for (( i=1; i<=100; i=i+1 )) do s=$(($s+$i)) done echo "the result is : $s"- 1
- 2
- 3
- 4
- 5
- 6
- 7
函数
现在假设有个需求:
- 输入一个目录,然后打印出这个目录下的所有的普通文件
我们创建一个名为
list_file_for_dir.sh的脚本,内容如下:#!/bin/bash function is_file() { test -f $1 } function list_file() { file_list=`ls $1` for filename in $file_list do if is_file $1/$filename; then echo $1/$filename fi done }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这个时候我们可以写一个名为
15.sh的脚本然后调用上面的函数:#!/bin/bash ## 导入需要调用的函数所在的脚本 source ./list_file_for_dir.sh dir=$1 list_file $dir- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
重定向
当我们在 Centos 7 系统上启动一个进程的话,默认的话会打开标准输入、标准输出、错误输出三个文件描述符。
比如当我们打开一个终端的时候,会启动一个 bash 进程,我们可以通过
ps来查看这个进程的PID:[root@master ~]# ps PID TTY TIME CMD 2063 pts/1 00:00:00 bash 2080 pts/1 00:00:00 ps- 1
- 2
- 3
- 4
然后我们可以查看目录
/proc/2033/fd下的文件:[root@master fd]# ls -l /proc/2033/fd total 0 lrwx------. 1 root root 64 Oct 6 15:19 0 -> /dev/pts/0 lrwx------. 1 root root 64 Oct 6 15:19 1 -> /dev/pts/0 lrwx------. 1 root root 64 Oct 6 15:19 2 -> /dev/pts/0 lrwx------. 1 root root 64 Oct 6 15:20 255 -> /dev/pts/0- 1
- 2
- 3
- 4
- 5
- 6
/proc目录下就是存放了每个进程的状态信息从上可以看出有 4 个链接文件,其中:
- 0 表示标准输入
- 1 表示标准输出
- 2 表示错误输出
从上还可以看出,不管是输入还是输出,默认都是终端。
不管是输入还是输出,我们都可以进行重定向。
输入重定向
## 使用 wc -l 统计从终端输入的数据的行数 [root@master ~]# wc -l 123 2342 2 [root@master ~]#- 1
- 2
- 3
- 4
- 5
- 6
ctrl + d 退出 wc -l 界面
我们可以使用输入重定向符号
<来对输入进行重定向,比如我们使用wc -l统计一个文件中的数据的行数,如下:## 将输入重定向为一个文件 [root@master ~]# wc -l < /etc/passwd 22- 1
- 2
- 3
还比如,我们可以读取终端的数据,饭后赋值给一个变量:
[root@master ~]# read var 123 [root@master ~]# echo $var 123- 1
- 2
- 3
- 4
我们也可以将一个文件作为输入,然后将文件中第一行内容赋值给一个变量:
[root@master ~]# read var2 < /etc/passwd [root@master ~]# echo $var2 root:x:0:0:root:/root:/bin/bash- 1
- 2
- 3
输出重定向
默认情况下输出是终端,比如:
## 将数据字符串 123 输出到终端 [root@master ~]# echo 123 123- 1
- 2
- 3
如果我们想将输出重定向到一个文件中,我们可以使用
>或者>>符号,如下:[root@master ~]# echo 123 > a.txt [root@master ~]# cat a.txt 123 [root@master ~]# echo 456 > a.txt [root@master ~]# cat a.txt 456 [root@master ~]# echo 456 >> a.txt [root@master ~]# cat a.txt 456 456 [root@master ~]# echo 456 >> a.txt [root@master ~]# cat a.txt 456 456 456- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
>会清除文件中之前的内容>>不会清除文件,会将内容追加到文件的最后
以上是将正确的数据输入到指定的文件,我们也可以将一个执行脚本或者命令时候的报错信息输出到指定的文件中,比如:
[root@master ~]# nocmd -bash: nocmd: command not found [root@master ~]# nocmd 2> error.tx [root@master ~]# cat error.tx -bash: nocmd: command not found- 1
- 2
- 3
- 4
- 5
可以看出我们使用
2>来重定向错误输出。如果不管是正确结果还是错误结果,我们都想重定向到一个指定文件中,我们可以使用
&>符号:[root@master ~]# nocmd &> d.txt [root@master ~]# cat d.txt -bash: nocmd: command not found [root@master ~]# ls &> d.txt [root@master ~]# cat d.txt 10.sh 11.sh 12.sh 13.sh 14.sh 15.sh 2.sh 5.sh- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
nohup 和 输出重定向
我们前面讲过使用
nohup的方式来启动进程,使得进程在后台运行,并且将进程的输出会输出到当前目录下nohup.out的文件中我们可以使用
nohup结合输出重定向&>来自定义进程的输出文件,如下:## 后台运行 15.sh 脚本,并且将结果都输出到 test.out 文件中 nohup /root/15.sh /etc &> test.out & ## 你也可能会遇到这样的写法,效果和上面的是一样 ## 先将脚本标准输出输出到文件 test.out 中 ## 然后 2>&1 表示将错误输出输出到标准输出中 nohup /root/15.sh > test.out 2>&1 &- 1
- 2
- 3
- 4
- 5
- 6
- 7
管道
执行一个命令或者一个脚本都会有一个标准输入和一个标准输出,有很多场景下我们想将一个命令的标准输出作为另一个命令的标准输入,这个就是我们这篇文章讲到的管道技术。
比如我们执行
ls /etc的时候发现输出结果太多了,我们想分页看这个命令输出的结果,那么我们就可以将ls /etc这个命令的输出作为命令less的输入,如下:ls /etc | less- 1
上面的
|就是管道符。它的作用就是将ls /etc的输出作为less命令的输入。再比如,我们使用
history来查看历史命令,但是发现执行的历史命令太多了,我们需要从历史命令中找到包含关键字alias的命令,我们可以:history | grep alias- 1
也就是将
history的输出作为grep alias的输入,grep alias就是查找包含alias的行。有的时候我们通过
ps -ef来查找进程,发现进程数太多了,也可以使用grep来过滤出我们自己想要的进程的信息:ps -ef | grep wc- 1
date 命令
我们可以使用
date命令查看系统当前的时间:[root@master ~]# date Sun Oct 6 14:20:26 CST 2019- 1
- 2
如果你的时间不对的话,可以通过
date命令来设置:date -s '2019-10-10 08:55:55'- 1
我们也可以通过
date命令拿到系统当前的年、月、日、时、分、秒:[root@master ~]# date +%Y 2019 [root@master ~]# date +%m 10 [root@master ~]# date +%d 06 [root@master ~]# date +%H 14 [root@master ~]# date +%M 21 [root@master ~]# date +%S 16 [root@master ~]# date +%Y%m%d 20191006- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
有了这些信息后,我们就可以对当前的时间进行格式化,比如我们想使用格式
YYYY-mm-dd HH:MM:SS来显示当前的时间:[root@master ~]# date "+%Y-%m-%d %H:%M:%S" 2019-10-06 14:24:24 [root@master ~]# date +%Y%m%d%H%M%S 20191006142531- 1
- 2
- 3
- 4
我们还可以使用
date命令获取到前一天的时间:[root@master ~]# date --d="1 days ago" Sat Oct 5 14:28:55 CST 2019 [root@master ~]# date --d="1 days ago" "+%Y-%m-%d %H:%M:%S" 2019-10-05 14:29:08- 1
- 2
- 3
- 4
还可以获取明天或者后天的时间:
[root@master ~]# date --d="1 days" Mon Oct 7 14:29:51 CST 2019 [root@master ~]# date --d="1 days" "+%Y-%m-%d %H:%M:%S" 2019-10-07 14:29:58- 1
- 2
- 3
- 4
一次性计划任务
我们前面都是手动的执行脚本,那么在实际的环境中,有可能在半夜、或者指定的时间来运行脚本,这个我们可以通过
at命令来实现,使用at前需要安装at:yun -y install at- 1
接下来我们使用
at命令来执行15.sh脚本:[root@master ~]# chmod u+x 15.sh [root@master ~]# date Sun Oct 6 14:37:56 CST 2019 [root@master ~]# at 14:40 at> /root/15.sh /etc > /tmp/test.txt at>job 4 at Sun Oct 6 14:40:00 2019 - 1
- 2
- 3
- 4
- 5
- 6
- 7
注意:最后是使用 ctrl + d 退出 at 界面,保存 job
可以通过命令
atq来查询有多少的at job:[root@master ~]# atq 2 Sun Oct 6 14:35:00 2019 a root 4 Sun Oct 6 14:40:00 2019 a root- 1
- 2
- 3
等到 14:40 分钟的时候,我们查看结果文件
/tmp/test.txt,输出内容如下:[root@master ~]# ls -al /tmp/test.txt -rw-r--r--. 1 root root 2996 Oct 6 14:47 /tmp/test.txt- 1
- 2
at适合一次性的计划任务,执行完了就不会再执行了。周期性计划任务
如果需要周期性的执行命令或者脚本的话,我们要用到
crontab这个命令。比如我们现在实现每分钟将当前的日期追加到文件
/tmp/date.txt中。执行
crontab -e进行任务编辑界面,这个编辑界面和 vi 是一样的:crontab -e ## 分钟 小时 日 月 星期 命令 * * * * * /usr/bin/date >> /tmp/date.txt- 1
- 2
- 3
- 4
可以通过
which date查看date命令的全路径以上就是每分钟会将
date追加到/tmp/date.txt文件中。可以通过
tail -fn300 /var/log/cron来查看周期性任务的执行情况。[root@master ~]# cat /tmp/date.txt Sun Oct 6 17:29:02 CST 2019 Sun Oct 6 17:30:01 CST 2019- 1
- 2
- 3
可以使用
crontab -l来查看所有的周期性任务。## 每个星期一的每分钟执行一次 * * * * 1 /usr/bin/date >> /tmp/date.txt ## 每个星期一或者星期五的每分钟执行一次 * * * * 1,5 /usr/bin/date >> /tmp/date.txt ## 每个星期一到星期五的每分钟执行一次 * * * * 1-5 /usr/bin/date >> /tmp/date.txt ## 7 月 7 号,并且属于周一到周五,每分钟执行一次 * * 7 7 1-5 /usr/bin/date >> /tmp/date.txt ## 每天凌晨 3 点 30 分执行一次 30 3 * * * /usr/bin/date >> /tmp/date.txt ## 每个星期一的凌晨 3 点 30 分执行一次 30 3 * * 1 /usr/bin/date >> /tmp/date.txt ## 每 15 分钟执行一次 15 * * * * /usr/bin/date >> /tmp/date.txt- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
文本操作
grep
在文件内容查找的时候,我们会使用
grep命令来实现查找,比如:- 从
/root/anaconda-ks.cfg文件中,查找到单词password所在的位置
[root@master ~]# grep password anaconda-ks.cfg # Root password [root@master ~]# grep -n password anaconda-ks.cfg 20:# Root password- 1
- 2
- 3
- 4
- 5
-n选项表示显示行号如果我们想找到单词
pass开头,后面有 4 个字符的字符串:[root@master ~]# grep -n pass.... anaconda-ks.cfg 3:auth --enableshadow --passalgo=sha512 20:# Root password [root@master ~]# grep -n pass....$ anaconda-ks.cfg 20:# Root password- 1
- 2
- 3
- 4
- 5
- 6
.表示匹配除换行符外的任意单个字符$表示匹配一行的结尾*表示匹配任意一个或者零个跟在它前面的字符
[root@master ~]# grep -n pas* anaconda-ks.cfg 3:auth --enableshadow --passalgo=sha512 20:# Root password 28:autopart --type=lvm 30:clearpart --none --initlabel 32:%packages [root@master ~]# grep -n pass.* anaconda-ks.cfg 3:auth --enableshadow --passalgo=sha512 20:# Root password- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
[]表示匹配方括号中字符类中的任意一个^表示匹配开头
[root@master ~]# grep [Nn]etwork anaconda-ks.cfg # Network information network --bootproto=dhcp --device=ens33 --onboot=off --ipv6=auto --no-activate network --hostname=localhost.localdomain [root@master ~]# grep -i network anaconda-ks.cfg # Network information network --bootproto=dhcp --device=ens33 --onboot=off --ipv6=auto --no-activate network --hostname=localhost.localdomain [root@master ~]# grep ^# anaconda-ks.cfg #version=DEVEL # System authorization information # Use CDROM installation media # Use graphical install # Run the Setup Agent on first boot # Keyboard layouts # System language # Network information # Root password # System services # System timezone # System bootloader configuration # Partition clearing information- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
现在要求查找
/root/anaconda-ks.cfg文件中所有的 . 所在的行:[root@master ~]# grep "\." anaconda-ks.cfg lang en_US.UTF-8 network --hostname=localhost.localdomain- 1
- 2
- 3
- 因为
.是特殊符号,所以需要使用\来转移,而且转义后不让.再次成为匹配所有,所以需要加上双引号。
cut & sort
cut
cut这个命令可以将一段信息的某一段切出来,处理数据的时候也是以行为单位。比如,当我们输出
$PATH的时候,它的取值是:echo $PATH ## 输出是 /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin ## 现在我们想拿到上面的第 4 个字段 echo $PATH | cut -d ":" -f 4 ## 输出为: /usr/bin ## 现在想拿到第 3 个和第 5 个字段 echo $PATH | cut -d ":" -f 3,5 ## 输出为: /usr/sbin:/root/bin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
选项参数的解释:
-d表示分割字符,一般与-f一起使用-f:依据 -d 指定的分割字符将一段信息切割成数段,用-f取出第几段
使用
cut也可以指定字符区间来切割数据:[root@localhost ~]# export declare -x HISTCONTROL="ignoredups" declare -x HISTSIZE="1000" declare -x HOME="/root" declare -x HOSTNAME="localhost.localdomain" declare -x LANG="en_US.UTF-8" declare -x LESSOPEN="||/usr/bin/lesspipe.sh %s" declare -x LOGNAME="root" ## 从第 12 个字符开始截取 [root@localhost ~]# export | cut -c 12- HISTCONTROL="ignoredups" HISTSIZE="1000" HOME="/root" HOSTNAME="localhost.localdomain" LANG="en_US.UTF-8" LESSOPEN="||/usr/bin/lesspipe.sh %s" LOGNAME="root" ## 也可以指定范围进行切割,比如 cut -c 12-20- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
sort
sort命令可以帮我们排序,而且可以依据不同的数据类型进行排序。[root@localhost ~]# cat /etc/passwd | sort adm:x:3:4:adm:/var/adm:/sbin/nologin bigdata:x:1000:1000::/home/bigdata:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin dbus:x:81:81:System message bus:/:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin ## 按照第三个字段排序 [root@localhost ~]# cat /etc/passwd | sort -t ":" -k 3 root:x:0:0:root:/root:/bin/bash bigdata:x:1000:1000::/home/bigdata:/bin/bash user1:x:1001:1001::/home/user1:/bin/bash user2:x:1002:1001::/home/user2:/bin/bash user3:x:1003:1002::/home/user3:/bin/bash ## 反向排序 [root@localhost ~]# cat /etc/passwd | sort -t ":" -k 3 -r nobody:x:99:99:Nobody:/:/sbin/nologin polkitd:x:999:997:User for polkitd:/:/sbin/nologin postfix:x:89:89::/var/spool/postfix:/sbin/nologin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
find
前面使用
grep是查找文件中的内容,如果我们想在指定的文件目录中查找指定的文件名的话,需要使用find命令,如下:## 查找 /etc 目录下的 passwd 文件 [root@master ~]# find /etc -name passwd /etc/passwd /etc/pam.d/passwd- 1
- 2
- 3
- 4
这样就可以找出
/etc这个目录下的所有的名字为passwd的文件。对于需要查找的文件名,我们也可以使用通配符
## 查找 /etc 目录下的所有的以 pass 开头的文件 [root@master ~]# find /etc -name pass* /etc/openldap/certs/password /etc/passwd /etc/passwd- /etc/pam.d/passwd /etc/pam.d/password-auth-ac /etc/pam.d/password-auth /etc/selinux/targeted/active/modules/100/passenger- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
对于需要查找的文件名,我们也可以使用正则来匹配
## 查找 /etc 目录下的所有以 wd 结尾的文件 [root@master ~]# find /etc -regex .*wd$ /etc/passwd /etc/pam.d/passwd /etc/security/opasswd- 1
- 2
- 3
- 4
- 5
sed
我们前面讲过 vi 和 vim 编辑器,这个编辑器主要是针对一个文件进行编辑的,而
sed命令主要是针对文件中的每一行数据进行编辑的,包括:- 以行为单位的新增/删除功能
- 以行为单位的替换/显示功能
以行为单位的新增/删除功能
- 将
/etc/passwd的前十条数据列出并且打印行号,同时,请将 2~5 行删除:
[root@master ~]# nl /etc/passwd | head -10 | sed '2,5d' 1 root:x:0:0:root:/root:/bin/bash 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 8 halt:x:7:0:halt:/sbin:/sbin/halt 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 10 operator:x:11:0:operator:/root:/sbin/nologin ## 删除第二行 [root@master ~]# nl /etc/passwd | head -10 | sed '2d' 1 root:x:0:0:root:/root:/bin/bash 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 8 halt:x:7:0:halt:/sbin:/sbin/halt 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 10 operator:x:11:0:operator:/root:/sbin/nologin ## 删除第 3 行到最后一行,使用 $ 表示最后一行 [root@master ~]# nl /etc/passwd | head -10 | sed '3,$d' 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 承上例,在第二行的后面加上一句话:how are you
[root@master ~]# nl /etc/passwd | head -5 | sed '2a how are you' 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin how are you 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin ## 新增两行 [root@master ~]# nl /etc/passwd | head -5 | sed '2a how are you \ > this ' 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin how are you this 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin ## 在第二行前面加上一句话 [root@master ~]# nl /etc/passwd | head -5 | sed '2i how are you' 1 root:x:0:0:root:/root:/bin/bash how are you 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
以行为单位的替换/显示功能
- 将第 2~5 行的内容替换为 “No 2-5 number”
[root@master ~]# nl /etc/passwd | head -10 | sed '2,5c No 2-5 number' 1 root:x:0:0:root:/root:/bin/bash No 2-5 number 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 8 halt:x:7:0:halt:/sbin:/sbin/halt 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 10 operator:x:11:0:operator:/root:/sbin/nologin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 仅列出
/etc/passwd文件内的第 5-7 行
[root@master ~]# nl /etc/passwd | head -7 | tail -3 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown [root@master ~]# nl /etc/passwd | sed -n '5,7p' 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们可以使用
sed来替换文本,语法如下:sed 's/要被替换的字符串/新的字符串/g'- 1
- 从
ifconfig中获取ip的数据
## 获取网卡 ens33 的信息 [root@master ~]# ifconfig ens33 ens33: flags=4163- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 利用
sed将/root/anaconda-ks.cfg内每一行开头的#替换为!
sed -i 's/^#/\!/g' anaconda-ks.cfg sed -i 's/^!/\#/g' anaconda-ks.cfg- 1
- 2
- 3
awk
上一篇文章中我们介绍使用 sed 来处理每行数据,如果要处理每一行中的每个字段的话,我们使用 awk 这个命令来完成。
我们现在查看
/etc/passwd前面 5 行数据:[root@master ~]# head -5 /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin- 1
- 2
- 3
- 4
- 5
- 6
可以看出以上每一行中的每一个字段都是使用
:来分割开的,我们现在想显示每一行的第 1 个字段和第 4 个字段,我们可以:[root@master ~]# head -5 /etc/passwd | awk -F ":" '{print $1,$4}' root 0 bin 1 daemon 2 adm 4 lp 7 [root@master ~]# head -5 /etc/passwd | awk -F ":" '{print $0}' root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可以看出:
-F选项用于指定切分的字符$1、$2、$3...分别表示第一个字段、第二个字段、第三个字段等等$0表示一整行
我们也可以通过指定
FS来指定切分的字符,如下:[root@master ~]# head -5 /etc/passwd | awk 'BEGIN{FS=":"}{print $1,$4}' root 0 bin 1 daemon 2 adm 4 lp 7- 1
- 2
- 3
- 4
- 5
- 6
通过指定
OFS来指定打印之后的字段的连接符:[root@master ~]# head -5 /etc/passwd | awk 'BEGIN{FS=":";OFS="-"}{print $1,$4}' root-0 bin-1 daemon-2 adm-4 lp-7- 1
- 2
- 3
- 4
- 5
- 6
通过指定
RS来指定记录的分隔符,如下:## 指定 : 为行分隔符 [root@master ~]# head -5 /etc/passwd | awk 'BEGIN{RS=":"}{print $0}' | head -10 root x 0 0 root /root /bin/bash bin x 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
指定
NR来指定行号:[root@master ~]# head -5 /etc/passwd | awk '{print NR,$0}' 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin- 1
- 2
- 3
- 4
- 5
- 6
NF表示字段的个数:[root@master ~]# head -5 /etc/passwd | awk 'BEGIN{FS=":"}{print NF}' 7 7 7 7 7 [root@master ~]# head -5 /etc/passwd | awk 'BEGIN{FS=":"}{print $NF}' /bin/bash /sbin/nologin /sbin/nologin /sbin/nologin /sbin/nologin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
awk也可以使用逻辑计算[root@localhost ~]# ll | awk 'BEGIN{FN=" "}{print $1,$2,$3,$4}' total 100 -rwxr--r--. 1 root root -rwxr--r--. 1 root root -rw-r--r--. 1 root root -rw-r--r--. 1 root root -rw-r--r--. 1 root root -rw-r--r--. 1 root root -rwxr--r--. 1 root root ## 过滤除文件大小大于等于 1259 字节的文件 [root@localhost ~]# ll | awk 'BEGIN{FN=" "} $5 >= 1259 {print $0}' -rw-------. 1 root root 1259 Mar 19 2018 anaconda-ks.cfg -rw-------. 1 root root 3010 Oct 9 17:20 nohup.out -rw-r--r--. 1 root root 1547 Oct 9 17:24 test.out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
相关阅读:
【C++基础】9. 数组
上海张江×百度飞桨打了个样,AI赋能这事儿可算有“参考答案”了
ROS1Noetic在Win11中安装记录
每天五分钟计算机视觉:搭建手写字体识别的卷积神经网络
Hive的基本SQL操作(DDL篇)
Frida安装到使用一目了然
【无标题】
拓扑排序(C++)
跟李沐学AI之计算性能+图像分类
突破编程_C++_面试(STL 编程 list)
- 原文地址:https://blog.csdn.net/lyabc123456/article/details/133169014
