-
六、决策树算法(DT,DecisionTreeClassifier)(有监督学习)
决策树(DT)是一种用于分类和回归的非参数监督学习方法。其目标是创建一个模型,通过学习从数据特征中推断出的简单决策规则来预测目标变量的值。一棵树可以看作是一个片断常数近似值。
一、算法思路
具体可参考博文:七、决策树算法和集成算法
基尼系数Gini:衡量选择标准的不确定程度;说白了,就是越不确定Gini系数越高
需要选择最小的Gini系数来决定决策树下一级别分类的标准

以基尼系数为核心的决策树称为CART决策树(Classification and Regression Tree)
一般看到的决策树都是二叉树,这只是一种选择,并不代表所有决策树都是二叉树
决策树的生成容易造成过拟合现象的产生,需要剪枝操作来放弃一些约束条件达到防止过拟合的效果官网决策树算法介绍:1.10. Decision Trees
二、官网API
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0)- 1
导包:
from sklearn.tree import DecisionTreeClassifier
这里的参数还是比较多的,具体的参数使用,可以根据官网给的demo进行学习,多动手尝试;这里就以一些常用的参数进行说明。①特征标准选择criterion
criterion衡量分割质量的函数
‘gini’:用于衡量gini不纯度,默认值
‘log_loss’和’entropy’:均用于衡量Shannon信息增益具体官网详情如下:

使用方法
DecisionTreeClassifier(criterion='entropy')②splitter
splitter用于选择每个节点分割的策略
‘best’:最佳分割,默认值
‘random’:最佳随机分割具体官网详情如下:

使用方法
DecisionTreeClassifier(splitter='random')③max_features
max_features,寻找最佳分割时需要考虑的特征数量
‘auto’:每次分割时,特征数量根据具体情况进行自动选择
‘sqrt’:每次分割时,特征数量采用max_features=sqrt(n_features)
‘log2’:每次分割时,特征数量采用max_features=log2(n_features)
‘int’:在每次分割时考虑max_features特征
‘float’:特征值是一个分数;每次分割时,特征数量采用max(1,int(max_features * n_features_in_))
‘None’:每次分割时,特征数量采用max_features=n_features,默认值具体官网详情如下:

使用方法
DecisionTreeClassifier(max_features='auto')④随机种子random_state
控制估计器的随机性,随即状态实例,如果要是为了对比,需要控制变量的话,这里的随机种子最好设置为同一个整型数
在每次分割时,即使splitter=‘best’,特征也总是随机排列的
当 max_features < n_features 时,算法会在每次分割时随机选择 max_features,然后再从中找出最佳分割
但是,即使 max_features=n_features 在不同的运行中找到的最佳分割也可能不同
如果多个分割点的改进标准相同,且必须随机选择一个分割点,就会出现这种情况;为了在拟合过程中获得确定的行为,必须将 random_state 设为整数具体官网详情如下:

使用方法
DecisionTreeClassifier(random_state=42)⑤最终构建模型
DecisionTreeClassifier(criterion=‘entropy’,splitter=‘random’,max_features=‘auto’,random_state=42)
三、代码实现
①导包
这里需要评估、训练、保存和加载模型,以下是一些必要的包,若导入过程报错,pip安装即可
import numpy as np import pandas as pd import matplotlib.pyplot as plt import joblib %matplotlib inline import seaborn as sns from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import confusion_matrix, classification_report, accuracy_score- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
②加载数据集
数据集可以自己简单整个,csv格式即可,我这里使用的是6个自变量X和1个因变量Y
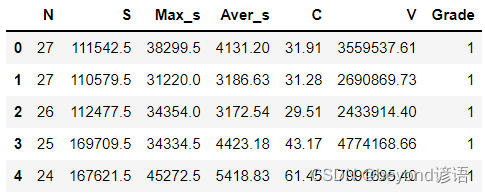
fiber = pd.read_csv("./fiber.csv") fiber.head(5) #展示下头5条数据信息- 1
- 2
③划分数据集
前六列是自变量X,最后一列是因变量Y
常用的划分数据集函数官网API:train_test_split
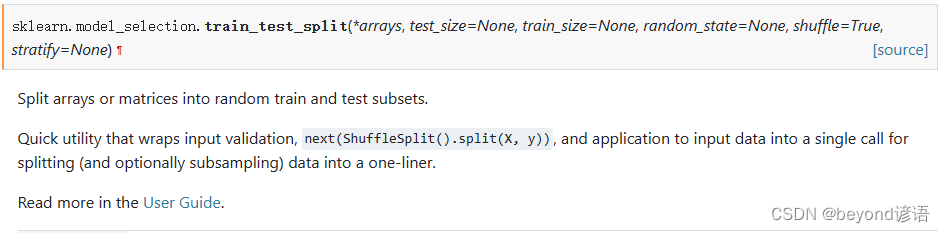
test_size:测试集数据所占比例
train_size:训练集数据所占比例
random_state:随机种子
shuffle:是否将数据进行打乱
因为我这里的数据集共48个,训练集0.75,测试集0.25,即训练集36个,测试集12个X = fiber.drop(['Grade'], axis=1) Y = fiber['Grade'] X_train, X_test, y_train, y_test = train_test_split(X,Y,train_size=0.75,test_size=0.25,random_state=42,shuffle=True) print(X_train.shape) #(36,6) print(y_train.shape) #(36,) print(X_test.shape) #(12,6) print(y_test.shape) #(12,)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
④构建DT模型
参数可以自己去尝试设置调整
dtc = DecisionTreeClassifier(criterion='entropy',splitter='random',max_features='auto',random_state=42)- 1
⑤模型训练
就这么简单,一个fit函数就可以实现模型训练
dtc.fit(X_train,y_train)- 1
⑥模型评估
把测试集扔进去,得到预测的测试结果
y_pred = dtc.predict(X_test)- 1
看看预测结果和实际测试集结果是否一致,一致为1否则为0,取个平均值就是准确率
accuracy = np.mean(y_pred==y_test) print(accuracy)- 1
- 2
也可以通过score得分进行评估,计算的结果和思路都是一样的,都是看所有的数据集中模型猜对的概率,只不过这个score函数已经封装好了,当然传入的参数也不一样,需要导入accuracy_score才行,from sklearn.metrics import accuracy_score
score = dtc.score(X_test,y_test)#得分 print(score)- 1
- 2
⑦模型测试
拿到一条数据,使用训练好的模型进行评估
这里是六个自变量,我这里随机整个test = np.array([[16,18312.5,6614.5,2842.31,25.23,1147430.19]])
扔到模型里面得到预测结果,prediction = dtc.predict(test)
看下预测结果是多少,是否和正确结果相同,print(prediction)test = np.array([[16,18312.5,6614.5,2842.31,25.23,1147430.19]]) prediction = dtc.predict(test) print(prediction) #[2]- 1
- 2
- 3
⑧保存模型
dtc是模型名称,需要对应一致
后面的参数是保存模型的路径joblib.dump(dtc, './dtc.model')#保存模型- 1
⑨加载和使用模型
dtc_yy = joblib.load('./dtc.model') test = np.array([[11,99498,5369,9045.27,28.47,3827588.56]])#随便找的一条数据 prediction = dtc_yy.predict(test)#带入数据,预测一下 print(prediction) #[4]- 1
- 2
- 3
- 4
- 5
完整代码
模型训练和评估,不包含⑧⑨。
from sklearn.tree import DecisionTreeClassifier import pandas as pd import numpy as np from sklearn.model_selection import train_test_split fiber = pd.read_csv("./fiber.csv") # 划分自变量和因变量 X = fiber.drop(['Grade'], axis=1) Y = fiber['Grade'] #划分数据集 X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0) dtc = DecisionTreeClassifier(criterion='entropy',splitter='random',max_features='auto',random_state=42) dtc.fit(X_train,y_train)#模型拟合 y_pred = dtc.predict(X_test)#模型预测结果 accuracy = np.mean(y_pred==y_test)#准确度 score = dtc.score(X_test,y_test)#得分 print(accuracy) print(score) test = np.array([[11,99498,5369,9045.27,28.47,3827588.56]])#随便找的一条数据 prediction = dtc.predict(test)#带入数据,预测一下 print(prediction)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
-
相关阅读:
Unity 头顶图文字性能优化
无人机飞行表演编队的数据链方案介绍
二十、MySQL多表关系
最 Cool 的 Kubernetes 网络方案 Cilium 入门教程
HTTP协议【网络基础/应用层】
前端工程师面试题库
Mysql之常用函数、聚合函数&合并(union&union all)【第四篇】
Spring Framework 简介与起源
深度解读昇腾CANN多流并行技术,提高硬件资源利用率
MONAI Label -- 使用 AI 加速你的分割标注
- 原文地址:https://blog.csdn.net/qq_41264055/article/details/133158633
