-
云原生Kubernetes:pod亲和性与反亲和性
目录
3.比较 podAffinity 和 podAntiAffinity
一、理论
1.调度策略
(1)对比

2.Pod 拓扑分布约束
(1)概念
使用 拓扑分布约束(Topology Spread Constraints) 来控制 Pod在集群内故障域之间的分布, 例如区域(Region)、可用区(Zone)、节点和其他用户自定义拓扑域。 这样做有助于实现高可用并提升资源利用率。
(2)拓扑分布约束 (涉及K8S v1.25及以上版本)
Pod 拓扑分布约束使你能够以声明的方式进行配置。
topologySpreadConstraints字段,Pod API 包括一个spec.topologySpreadConstraints字段。这个字段的用法如下所示:- ---
- apiVersion: v1
- kind: Pod
- metadata:
- name: example-pod
- spec:
- # 配置一个拓扑分布约束
- topologySpreadConstraints:
- - maxSkew: <integer>
- minDomains: <integer> # 可选;自从 v1.25 开始成为 Beta
- topologyKey:
- whenUnsatisfiable:
- labelSelector:
- matchLabelKeys:
- # 可选;自从 v1.27 开始成为 Beta
- nodeAffinityPolicy: [Honor|Ignore] # 可选;自从 v1.26 开始成为 Beta
- nodeTaintsPolicy: [Honor|Ignore] # 可选;自从 v1.26 开始成为 Beta
- ### 其他 Pod 字段置于此处
(3) 示例
① 节点标签
拓扑分布约束依赖于节点标签来标识每个节点所在的拓扑域。 例如,某节点可能具有标签:

- 说明:
- 为了简便,此示例未使用众所周知的标签键 topology.kubernetes.io/zone 和 topology.kubernetes.io/region。 但是,建议使用那些已注册的标签键,而不是此处使用的私有(不合格)标签键 region 和 zone。
- 无法对不同上下文之间的私有标签键的含义做出可靠的假设。
②有一个 4 节点的集群且带有以下标签

③从逻辑上看集群如下

④一致性
- 应该为一个组中的所有 Pod 设置相同的 Pod 拓扑分布约束。
- 通常,如果正使用一个工作负载控制器,例如 Deployment,则 Pod 模板会帮你解决这个问题。 如果混合不同的分布约束,则 Kubernetes 会遵循该字段的 API 定义; 但是,该行为可能更令人困惑,并且故障排除也没那么简单。
- 运维人员需要一种机制来确保拓扑域(例如云提供商区域)中的所有节点具有一致的标签。 为了避免运维人员需要手动为节点打标签,大多数集群会自动填充知名的标签, 例如 kubernetes.io/hostname。检查运维人员的集群是否支持此功能。
⑤一个拓扑分布约束
假设拥有一个 4 节点集群,其中标记为
foo: bar的 3 个 Pod 分别位于 node1、node2 和 node3 中:
希望新来的 Pod 均匀分布在现有的可用区域,则可以按如下设置其清单:
- kind: Pod
- apiVersion: v1
- metadata:
- name: mypod
- labels:
- foo: bar
- spec:
- topologySpreadConstraints:
- - maxSkew: 1
- topologyKey: zone
- whenUnsatisfiable: DoNotSchedule
- labelSelector:
- matchLabels:
- foo: bar
- containers:
- - name: pause
- image: registry.k8s.io/pause:3.1
从此清单看,
topologyKey: zone意味着均匀分布将只应用于存在标签键值对为zone:的节点 (没有zone标签的节点将被跳过)。如果调度器找不到一种方式来满足此约束, 则whenUnsatisfiable: DoNotSchedule字段告诉该调度器将新来的 Pod 保持在 pending 状态。如果该调度器将这个新来的 Pod 放到可用区
A,则 Pod 的分布将成为[3, 1]。 这意味着实际偏差是 2(计算公式为3 - 1),这违反了maxSkew: 1的约定。 为了满足这个示例的约束和上下文,新来的 Pod 只能放到可用区B中的一个节点上:
或者:

可以调整 Pod 规约以满足各种要求:
- 将 maxSkew 更改为更大的值,例如 2,这样新来的 Pod 也可以放在可用区 A 中。
- 将 topologyKey 更改为 node,以便将 Pod 均匀分布在节点上而不是可用区中。 在上面的例子中,如果 maxSkew 保持为 1,则新来的 Pod 只能放到 node4 节点上。
- 将 whenUnsatisfiable: DoNotSchedule 更改为 whenUnsatisfiable: ScheduleAnyway, 以确保新来的 Pod 始终可以被调度(假设满足其他的调度 API)。但是,最好将其放置在匹配 Pod 数量较少的拓扑域中。 请注意,这一优先判定会与其他内部调度优先级(如资源使用率等)排序准则一起进行标准化。
3.调度场景详解
kube-scheduler 给一个 pod 做调度选择包含两个步骤: 1.过滤(节点预选),2.打分(节点优选,节点选定)
(1)Deployment/RC:全自动调度
Deployment/RC主要是自动部署应用的多个副本,并持续监控,以维持副本的数量。默认是使用系统Master的Scheduler经过一系列算法计算来调度,用户无法干预调度过程与结果。

(2)NodeSelector:定向调度
通过Node的标签和Pod的nodeSelector属性相匹配,可以达到将pod调度到指定的一些Node上。(3)Node亲和性调度
目前有两种亲和性表达,NodeAffinity语法支持的操作符包括In/NotIn/Exists/DoesNotExist/Gt/Lt。
该pod可以被调度到key为“env”,值为“node01”或“node02”的节点。另外,在满足该条件的节点中,优先使用具有“disk”标签,且值为“ssd”的节点。
(4)POD亲和性调度
POD亲和性表示POD部署到满足某些label的pod所在的NODE上。pod需要被调度到某个NODE节点上,该节点属于kubernetes.io/hostname 这个域,并且上面运行了这样的 pod:这个pod 有一个app=nginx的 label。

(5)POD反亲和性调度
POD反亲和性表示POD不能部署到满足某些label的pod所在的NODE上。

该pod不能被调度到某个NODE节点上,该节点属于kubernetes.io/hostname 这个域,并且上面运行了这样的 pod:这个pod 有一个app=nginx的 label。
(6) Taints与Tolerations(污点与容忍)
Taints与前面的Affinity相反,它让Node拒绝Pod的运行。为node添加一个Taint,效果是NoSchedule(除了NoSchedule还可以取值PreferNoSchedule/NoExecute)。意味着除非Pod明确声明可以容忍这个Taint,否则不会被调度到该Node上。使用PodToleratesNodeTaints预选策略和TaintTolerationPriority优选函数完成该机制。
该pod容忍env=node02 且 effect 为 NoExecute的节点。可以进行调度
(7)DaemonSet调度
在每个Node上调度一个Pod,管理集群中每个Node上仅运行一份Pod的副本实例。
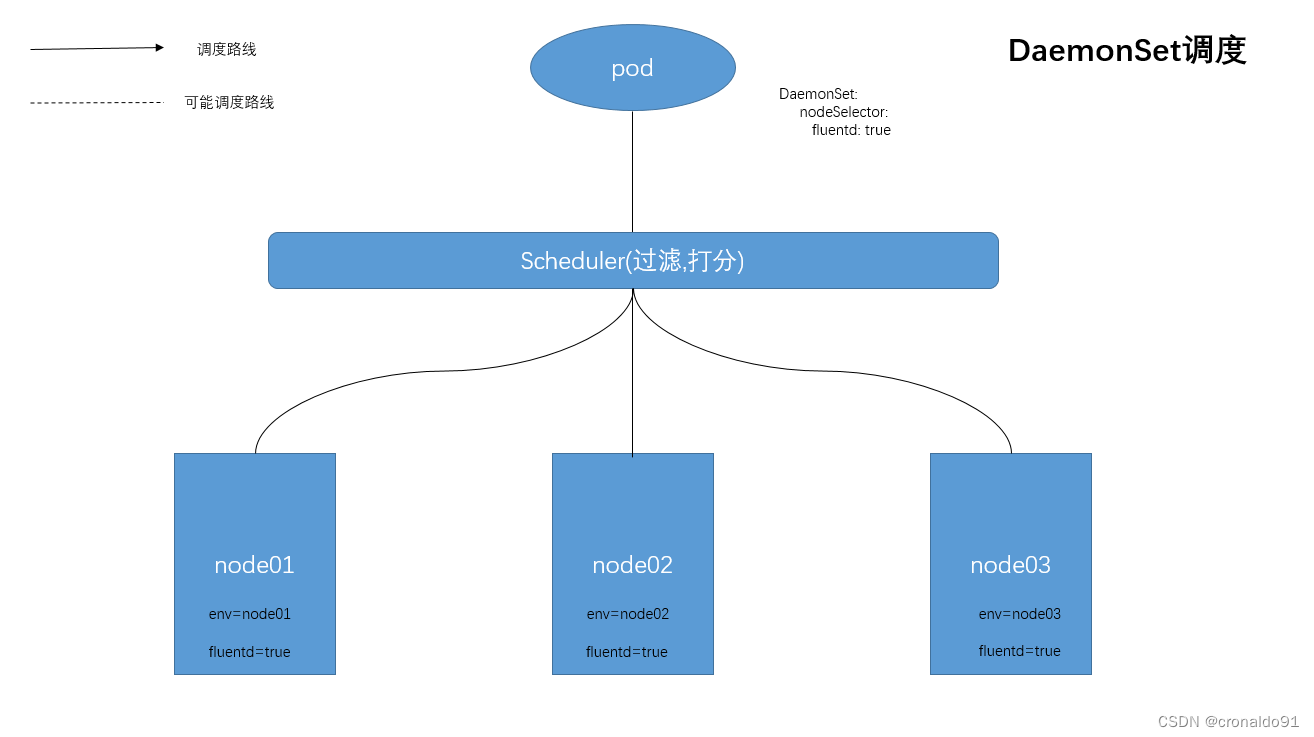
该pod会在每一个符合调度的node 节点上启动一个实例。该节点必须存在fluentd=true 的标签。
4.亲和性与反亲和性案例
(1)环境准备
node01、 node02 都有标签 test=a,有个pod1 运行在node01上, 标签为app=myapp01
- #设置node01和node02节点,拥有标签 test=a
- [root@master demo]# kubectl label nodes node{01,02} test=a --overwrite
- node/node01 labeled
- node/node02 labeled
- #查看拥有标签test=a的节点
- [root@master demo]# kubectl get nodes -l test=a
- NAME STATUS ROLES AGE VERSION
- node01 Ready
7d6h v1.15.1 - node02 Ready
7d6h v1.15.1
- [root@master demo]# vim test.yaml
- apiVersion: v1
- kind: Pod
- metadata:
- name: myapp01
- labels:
- app: myapp01
- spec:
- containers:
- - name: with-node-affinity
- image: soscscs/myapp:v1
- #声明式创建pod
- [root@master demo]# kubectl apply -f test.yaml
- pod/myapp01 created
- #查看pod myapp01的详细信息的标签
- [root@master demo]# kubectl get pods myapp01 -o wide --show-labels
- NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
- myapp01 1/1 Running 0 26s 10.244.1.112 node01
app=myapp01
(2) 亲和性+ In 测试
- [root@master demo]# vim a.yaml
- apiVersion: v1
- kind: Pod
- metadata:
- name: myapp10
- labels:
- app: myapp03
- spec:
- containers:
- - name: myapp03
- image: soscscs/myapp:v1
- affinity:
- podAffinity:
- requiredDuringSchedulingIgnoredDuringExecution:
- - labelSelector:
- matchExpressions:
- - key: app
- operator: In
- values:
- - myapp01
- topologyKey: test
pod拥有app=myapp01 标签(设这个pod为x),则把新pod调度到和 pod x 拥有同一个拓扑域test=a 的 节点上。
- [root@master demo]# for i in myapp{11..15}; do kubectl apply -f a.yaml; sed -ri "4s#myapp1[0-9]#$i#" a.yaml; done
- pod/myapp10 created
- pod/myapp11 created
- pod/myapp12 created
- pod/myapp13 created
- pod/myapp14 created
- [root@master demo]# kubectl get pods -o wide --show-labels
- NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
- myapp01 1/1 Running 0 88m 10.244.1.112 node01
app=myapp01 - myapp10 1/1 Running 0 6s 10.244.2.104 node02
app=myapp03 - myapp11 1/1 Running 0 6s 10.244.1.138 node01
app=myapp03 - myapp12 1/1 Running 0 5s 10.244.2.105 node02
app=myapp03 - myapp13 1/1 Running 0 5s 10.244.1.139 node01
app=myapp03 - myapp14 1/1 Running 0 5s 10.244.2.106 node02
app=myapp03
因为拓扑域test=a内,已经有了pod存在于node01节点上,所以把新pod调度到和 pod x 拥有同一个拓扑域test=a 的 节点上。
(3)亲和性+NotIn 测试
- [root@master demo]# vim a.yaml
- apiVersion: v1
- kind: Pod
- metadata:
- name: myapp10
- labels:
- app: myapp03
- spec:
- containers:
- - name: myapp03
- image: soscscs/myapp:v1
- affinity:
- podAffinity:
- requiredDuringSchedulingIgnoredDuringExecution:
- - labelSelector:
- matchExpressions:
- - key: app
- operator: NotIn
- values:
- - myapp01
- topologyKey: test
- [root@master demo]# kubectl delete pod myapp{10..14};for i in myapp{11..15}; do kubectl apply -f a.yaml; sed -ri "4s#myapp1[0-9]#$i#" a.yaml; done
- pod "myapp10" deleted
- pod "myapp11" deleted
- pod "myapp12" deleted
- pod "myapp13" deleted
- pod "myapp14" deleted
- pod/myapp10 created
- pod/myapp11 created
- pod/myapp12 created
- pod/myapp13 created
- pod/myapp14 created
- [root@master demo]# kubectl get pods -o wide --show-labels
- NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
- myapp01 1/1 Running 0 91m 10.244.1.112 node01
app=myapp01 - myapp10 1/1 Running 0 5s 10.244.1.140 node01
app=myapp03 - myapp11 1/1 Running 0 5s 10.244.2.107 node02
app=myapp03 - myapp12 1/1 Running 0 4s 10.244.1.141 node01
app=myapp03 - myapp13 1/1 Running 0 4s 10.244.2.108 node02
app=myapp03 - myapp14 1/1 Running 0 4s 10.244.1.142 node01
app=myapp03
(4)非亲和性+In 测试
- [root@master demo]# vim a.yaml
- apiVersion: v1
- kind: Pod
- metadata:
- name: myapp10
- labels:
- app: myapp03
- spec:
- containers:
- - name: myapp03
- image: soscscs/myapp:v1
- affinity:
- podAntiAffinity:
- requiredDuringSchedulingIgnoredDuringExecution:
- - labelSelector:
- matchExpressions:
- - key: app
- operator: In
- values:
- - myapp01
- topologyKey: test
- [root@master demo]# kubectl delete pod myapp{10..14};for i in myapp{11..15}; do kubectl apply -f a.yaml; sed -ri "4s#myapp1[0-9]#$i#" a.yaml; done
- pod "myapp10" deleted
- pod "myapp11" deleted
- pod "myapp12" deleted
- pod "myapp13" deleted
- pod "myapp14" deleted
- pod/myapp10 created
- pod/myapp11 created
- pod/myapp12 created
- pod/myapp13 created
- pod/myapp14 created
- [root@master demo]# kubectl get pods -o wide --show-labels
- NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
- myapp01 1/1 Running 0 96m 10.244.1.112 node01
app=myapp01 - myapp10 0/1 Pending 0 4s
app=myapp03 - myapp11 0/1 Pending 0 3s
app=myapp03 - myapp12 0/1 Pending 0 3s
app=myapp03 - myapp13 0/1 Pending 0 3s
app=myapp03 - myapp14 0/1 Pending 0 3s
app=myapp03 - [root@master demo]# kubectl describe pod myapp10
(5)非亲和性 + NotIn 测试
- [root@master demo]# vim a.yaml
- apiVersion: v1
- kind: Pod
- metadata:
- name: myapp10
- labels:
- app: myapp03
- spec:
- containers:
- - name: myapp03
- image: soscscs/myapp:v1
- affinity:
- podAntiAffinity:
- requiredDuringSchedulingIgnoredDuringExecution:
- - labelSelector:
- matchExpressions:
- - key: app
- operator: NotIn
- values:
- - myapp01
- topologyKey: test
- [root@master demo]# kubectl delete pod myapp{10..14};for i in myapp{11..15}; do kubectl apply -f a.yaml; sed -ri "4s#myapp1[0-9]#$i#" a.yaml; done
- pod "myapp10" deleted
- pod "myapp11" deleted
- pod "myapp12" deleted
- pod "myapp13" deleted
- pod "myapp14" deleted
- pod/myapp10 created
- pod/myapp11 created
- pod/myapp12 created
- pod/myapp13 created
- pod/myapp14 created
- [root@master demo]# kubectl get pods -o wide --show-labels
- NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
- myapp01 1/1 Running 0 102m 10.244.1.112 node01
app=myapp01 - myapp10 1/1 Running 0 8s 10.244.2.109 node02
app=myapp03 - myapp11 0/1 Pending 0 8s
app=myapp03 - myapp12 0/1 Pending 0 7s
app=myapp03 - myapp13 0/1 Pending 0 7s
app=myapp03 - myapp14 0/1 Pending 0 7s
app=myapp03 - [root@master demo]# kubectl describe pod myapp11
二、实验
1.亲和性与反亲和性
(1)环境准备
node01、 node02 都有标签 test=a,有个pod1 运行在node01上, 标签为app=myapp01

编写资源清单


声明式创建pod

查看pod myapp01的详细信息的标签
pod myapp01 拥有标签app=myapp01,且被调度到了node01上
(2) 亲和性+ In 测试


pod拥有app=myapp01 标签(设这个pod为x),则把新pod调度到和 pod x 拥有同一个拓扑域test=a 的 节点上。
创建pod myapp10-myapp14
因为拓扑域test=a内,已经有了pod存在于node01节点上,所以把新pod调度到和 pod x 拥有同一个拓扑域test=a 的 节点上。
pod从node01节点开始在两个节点上依次循环创建pod

查看资源清单文件,最后一次更改为15后,执行了14,然后修改为15结束for循环,实际是创建pod myapp10-myapp14就结束了

(3)亲和性+NotIn 测试
先修改资源清单文件


批量删除之前的pod myapp10-myapp14,并创建pod myapp10-myapp14
pod从node01节点开始,在两个节点上依次循环创建pod

(4)非亲和性+In 测试
先修改资源清单文件

批量删除之前的pod myapp10-myapp14,并创建pod myapp10-myapp14
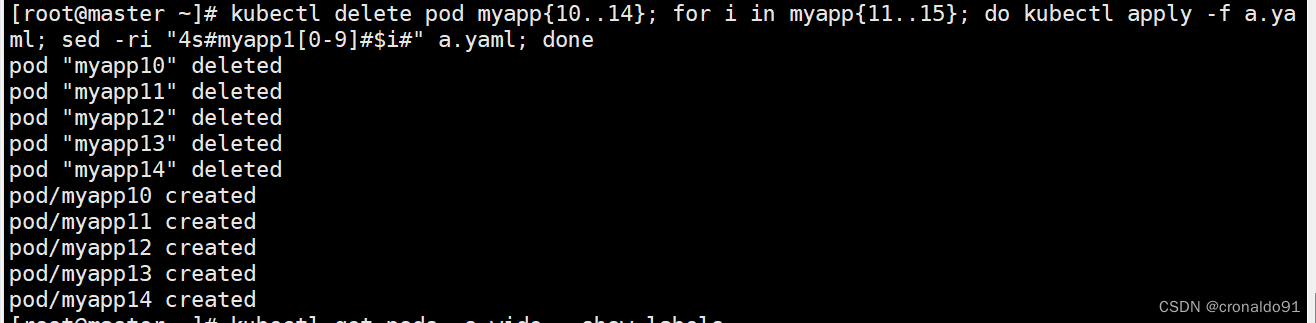
查看信息,新创建的pod都处于Pending状态

查看详细信息

两个节点都不匹配pod非亲和规则,又因为使用的是硬限制,因此当找不到合适的node节点调度pod时,就会处于Pending状态

(5)非亲和性 + NotIn 测试
先修改资源清单文件

 批量删除之前的pod myapp10-myapp14,并创建pod myapp10-myapp14
批量删除之前的pod myapp10-myapp14,并创建pod myapp10-myapp14查看信息,只有第一个myapp10成功在node02上创建,剩余的4个pod都处于Pending状态

查看详细信息
两个节点都不满足现有的pod反亲和性特征

三、问题
1.节点批次打标签错误
(1)报错

(2)原因分析
语法错误
(3)解决方法
将括号()修改为花括号 { }
修改前:

修改后:
成功:

2.for循环批量创建pod报错
(1)报错

(2)原因分析
“s”命令缺少终止符合#
(3)解决方法
添加终止符#
修改前:

修改后:

成功:
3.比较 podAffinity 和 podAntiAffinity
(1)比较
在 Kubernetes 中, Pod亲和性和反亲和性控制 Pod 彼此的调度方式(更密集或更分散)。
- podAffinity
- 吸引 Pod;你可以尝试将任意数量的 Pod 集中到符合条件的拓扑域中。
- podAntiAffinity
- 驱逐 Pod。如果将此设为 requiredDuringSchedulingIgnoredDuringExecution 模式, 则只有单个 Pod 可以调度到单个拓扑域;如果你选择 preferredDuringSchedulingIgnoredDuringExecution, 则你将丢失强制执行此约束的能力。
要实现更细粒度的控制,你可以设置拓扑分布约束来将 Pod 分布到不同的拓扑域下,从而实现高可用性或节省成本。 这也有助于工作负载的滚动更新和平稳地扩展副本规模。
四、总结
批量删除之前的pod myapp10-myapp14,并创建pod myapp10-myapp14
- [root@master]# kubectl delete pod myapp{10..14};for i in myapp{11..15}; do kubectl apply -f a.yaml; sed -ri "4s#myapp1[0-9]#$i#" a.yaml; done
-
相关阅读:
进程和线程
表单验证及更改页面背景图片
SM59/SE01/TR 请求号检查工具,不用传到正式区,开发环境即可
TCO-PEG-N3|TCO-PEG-azide|反式环辛烯-聚乙二醇-叠氮-齐岳生物
『现学现忘』Docker基础 — 35、实战:自定义CentOS镜像
docker compose和consul(服务注册与发现)
Day30 接口测试requests
CorelDRAW2023全新版功能及下载安装教程
MySQL篇—执行计划介绍(第二篇,总共三篇)
入手云服务器后,你需要做这些事【基于CentOS】
- 原文地址:https://blog.csdn.net/cronaldo91/article/details/133022082
