-
计算机视觉与深度学习-经典网络解析-AlexNet&ZFNet&VGG&GoogLeNet&ResNet[北邮鲁鹏]
参考文章
计算机视觉与深度学习-05-纹理表示&卷积神经网络-北邮鲁鹏老师课程笔记
LeNet5

AlexNet
AlexNet 是一种卷积神经网络(Convolutional Neural Network,CNN)的架构。它是由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton提出的,并在2012年的ImageNet大规模视觉识别挑战赛(ILSVRC)中获胜。
AlexNet是推动深度学习在计算机视觉任务中应用的先驱之一AlexNet跟LeNet-5类似也是一个用于图像识别的卷积神经网络。AlexNet网络结构更加复杂,参数更多。
验证了深度卷积神经网络的高效性
参考文章
手撕 CNN 经典网络之 AlexNet(理论篇)
论文《ImageNet Classification with Deep Convolutional Neural Networks》
【动手学计算机视觉】第十六讲:卷积神经网络之AlexNetAlexNet模型结构

AlexNet中使用的是ReLU激活函数,它5层卷积层除了第一层卷积核为 11 ∗ 11 11*11 11∗11、第二次为 5 ∗ 5 5*5 5∗5之外,其余三层均为 3 ∗ 3 3*3 3∗31. 第一层:卷积层
输入
输入为 224 ∗ 224 ∗ 3 224 * 224 * 3 224∗224∗3的图像,输入之前进行了去均值处理(AlexNet对数据集中所有图像向量求均值,均值为 224 ∗ 224 ∗ 3 224 * 224 * 3 224∗224∗3,去均值操作为原图减去均值,绝对数值对分类没有意义,去均值之后的相对数值可以正确分类且计算量小)
卷积
卷积核的数量为96,论文中两块GPU分别计算48个核;卷积核大小 11 ∗ 11 ∗ 3 , s t r i d e = 4 11 * 11 * 3,stride=4 11∗11∗3,stride=4,stride表示的是步长,padding = 0,表示不填充边缘。
卷积后的图形大小:
w i d e = ( 224 − k e r n e l _ s i z e + 2 ∗ p a d d i n g ) / s t r i d e + 1 = 54 wide = (224 - kernel\_size+2 * padding) / stride + 1 = 54 wide=(224−kernel_size+2∗padding)/stride+1=54
h e i g h t = ( 224 − k e r n e l _ s i z e + 2 ∗ p a d d i n g ) / s t r i d e + 1 = 54 height = (224 - kernel\_size+2 * padding) / stride + 1 = 54 height=(224−kernel_size+2∗padding)/stride+1=54
d i m e n t i o n = 96 dimention = 96 dimention=96参考个数: ( 11 × 11 × 3 + 1 ) × 96 = 35 k (11 \times 11 \times 3 + 1) \times 96 = 35k (11×11×3+1)×96=35k

池化输入通道数根据输入图像而定,输出通道数为96,步长为4。

注:窗口大小3*3,步长2,池化过程出现重叠,现在一般不使用重叠池化。池化结果:27x27x96 特征图组
局部响应归一化层(Local Response Normalized)

为什么要引入LRN层?
首先要引入一个神经生物学的概念:侧抑制(lateral inhibitio),即指被激活的神经元抑制相邻的神经元。
归一化(normaliazation)的目的就是“抑制”,LRN就是借鉴这种侧抑制来实现局部抑制,尤其是我们使用RELU的时候,这种“侧抑制”很有效 ,因而在AlexNet里使用有较好的效果。归一化有什么好处?
1 归一化有助于快速收敛;
2 对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
【补充:神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
深度网络的训练是复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。】2. 第二层:卷积层
输入为上一层卷积的 feature map, 27 × 27 × 96 27 \times 27 \times 96 27×27×96大小的特诊图组。卷积核的个数为256个,论文中的两个GPU分别有128个卷积核。
卷积核大小 5 ∗ 5 5*5 5∗5,输入通道数为96,输出通道数为256,步长为2,padding = 2。
卷积结果: ( 27 − 5 + 2 × 2 ) / 1 + 1 , 27 × 27 × 256 (27 - 5 + 2 \times 2) / 1 + 1,27 \times 27 \times 256 (27−5+2×2)/1+1,27×27×256的特征图组。然后做LRN。
最后最大化池化
池化层窗口大小为3*3,步长为2。
池化结果: 13 × 13 × 256 13 \times 13 \times 256 13×13×256的特征图组。
3. 第三层:卷积层
输入为第二层的输出,没有LRN和Pool。卷积核大小 3 ∗ 3 3*3 3∗3,输入通道数为256,输出通道数为384,stride为1,padding = 1。
图像尺寸为: ( 13 − 3 + 2 × 1 ) / 1 + 1 = 13 (13 - 3 + 2 \times 1) / 1 + 1 = 13 (13−3+2×1)/1+1=13
输出: 13 × 13 × 384 13 \times 13 \times 384 13×13×3844. 第四层:卷积层
输入为第三层的输出,没有LRN和Pool。
卷积核个数为384,大小 3 ∗ 3 3*3 3∗3,输入通道数为384,输出通道数为384,stride为1,padding = 1。
图像尺寸为: ( 13 − 3 + 2 × 1 ) / 1 + 1 = 13 (13 - 3 + 2 \times 1) / 1 + 1 = 13 (13−3+2×1)/1+1=13
输出: 13 × 13 × 384 13 \times 13 \times 384 13×13×3845. 第五层:卷积层
输入为第四层的输出。
卷积核大小 3 ∗ 3 3*3 3∗3,输入通道数为384,输出通道数为256,stride为1,padding = 1。
图像尺寸为: ( 13 − 3 + 2 × 1 ) / 1 + 1 = 13 (13 - 3 + 2 \times 1) / 1 + 1 = 13 (13−3+2×1)/1+1=13
卷积结果为: 13 × 13 × 256 13 \times 13 \times 256 13×13×256池化层窗口大小为 3 ∗ 3 3*3 3∗3,步长为2。
图像尺寸为: ( 13 − 3 ) / 2 + 1 = 6 (13 - 3) / 2 + 1 = 6 (13−3)/2+1=6
池化结果为: 6 × 6 × 256 6 \times 6 \times 256 6×6×2566. 第六层:全连接层
输入大小为上一层的输出,输出大小为4096。
Dropout概率为0.5。
7. 第七层:全连接层
输入大小为上一层的输出,输出大小为4096。
Dropout概率为0.5。
8. 第八层:全连接层
输入大小为4096,输出大小为分类数。
Dropout概率为0.5。

需要将第五层池化结果6×6×256转换为向量9216×1。因为全连接层不能输入矩阵,要输入向量。注意: 需要注意一点,5个卷积层中前2个卷积层后面都会紧跟一个池化层,而第3、4层卷积层后面没有池化层,而是连续3、4、5层三个卷积层后才加入一个池化层。
AlexNet共8层:
- 5个卷积层(CONV1——CONV5)
- 3个全连接层(FC6-FC8)

AlexNet运作流程
- conv1:输入→卷积→ReLU→局部响应归一化→重叠最大池化层
- conv2:卷积→ReLU→局部响应归一化→重叠最大池化层
- conv3:卷积→ReLU
- conv4:卷积→ReLU
- conv5:卷积→ReLU→重叠最大池化层(经过这层之后还要进行flatten展平操作)
- FC1:全连接→ReLU→Dropout
- FC2:全连接→ReLU→Dropout
- FC3(可看作softmax层):全连接→ReLU→Softmax
简单代码实现
使用pytorch
import torch import torch.nn as nn class AlexNet(nn.Module): def __init__(self, num_classes=1000): super(AlexNet, self).__init__() # 第一个卷积层,输入通道3(RGB图像),输出通道64,卷积核大小11x11,步长4,填充2 self.conv1 = nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2) self.relu1 = nn.ReLU(inplace=True) # 最大池化层,窗口大小3x3,步长2 self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2) # 第二个卷积层,输入通道64,输出通道192,卷积核大小5x5,填充2 self.conv2 = nn.Conv2d(64, 192, kernel_size=5, padding=2) self.relu2 = nn.ReLU(inplace=True) # 第二个最大池化层,窗口大小3x3,步长2 self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2) # 第三个卷积层,输入通道192,输出通道384,卷积核大小3x3,填充1 self.conv3 = nn.Conv2d(192, 384, kernel_size=3, padding=1) self.relu3 = nn.ReLU(inplace=True) # 第四个卷积层,输入通道384,输出通道256,卷积核大小3x3,填充1 self.conv4 = nn.Conv2d(384, 256, kernel_size=3, padding=1) self.relu4 = nn.ReLU(inplace=True) # 第五个卷积层,输入通道256,输出通道256,卷积核大小3x3,填充1 self.conv5 = nn.Conv2d(256, 256, kernel_size=3, padding=1) self.relu5 = nn.ReLU(inplace=True) # 第三个最大池化层,窗口大小3x3,步长2 self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2) # 自适应平均池化层,输出特征图大小为6x6 self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) # 全连接层,输入大小为256x6x6,输出大小为4096 self.fc1 = nn.Linear(256 * 6 * 6, 4096) self.relu6 = nn.ReLU(inplace=True) # 全连接层,输入大小为4096,输出大小为4096 self.fc2 = nn.Linear(4096, 4096) self.relu7 = nn.ReLU(inplace=True) # 全连接层,输入大小为4096,输出大小为num_classes self.fc3 = nn.Linear(4096, num_classes) def forward(self, x): x = self.conv1(x) x = self.relu1(x) x = self.maxpool1(x) x = self.conv2(x) x = self.relu2(x) x = self.maxpool2(x) x = self.conv3(x) x = self.relu3(x) x = self.conv4(x) x = self.relu4(x) x = self.conv5(x) x = self.relu5(x) x = self.maxpool3(x) x = self.avgpool(x) x = x.view(x.size(0), -1) x = self.fc1(x) x = self.relu6(x) x = self.fc2(x) x = self.relu7(x) x = self.fc3(x) return x # 创建AlexNet模型的实例 model = AlexNet(num_classes=1000) # 打印模型结构 print(model)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
重要说明
- 用于提取图像特征的卷积层以及用于分类的全连接层是同时学习的。
- 卷积层与全连接层在学习过程中会相互影响、相互促进
重要技巧
- Dropout策略防止过拟合;
- 使用动量的随机梯度下降算法,加速收敛;
- 验证集损失不下降时,手动降低10倍的学习率;
- 采用样本增强策略增加训练样本数量,防止过拟合;
- 集成多个模型,进一步提高精度。

现在显存基本都够用,不需要再考虑分两个GPU计算。AlexNet卷积层在做什么?

主要贡献
- 提出了一种卷积层加全连接层的卷积神经网络结构
- 首次使用ReLU函数做为神经网络的激活函数
- 首次提出Dropout正则化来控制过拟合
- 使用加入动量的小批量梯度下降算法加速了训练过程的收敛
- 使用数据增强策略极大地抑制了训练过程的过拟合
- 利用了GPU的并行计算能力,加速了网络的训练与推断
ZFNet
ZFNet是一种基于AlexNet的模型,由Matthew D. Zeiler和Rob Fergus在2013年提出。相对于AlexNet,ZFNet结构与AlexNet网络结构基本一致,进行了一些改进,包括卷积核。
主要改进
减小第一层卷积核
如果第一层的卷积核很大,那么第一层提取的就是粗粒度的信息,之后的层也将会丢掉细粒度的信息。相比AlexNet第一层卷积核大小为 11×11,ZFNet将第一个卷积层的卷积核大小改为7 × 7,卷积核减小,这样做的目的是为了增加感受野(receptive field),即更大范围内的像素对输出的影响。
ZFNet可以更好地捕捉图像中的局部特征,可以观察更细粒度的东西。并且具有更好的细节分辨能力。
将第二、第三个卷积层的卷积步长都设置为2
相比AlexNet第一层的卷积步长4,ZFNet将第一层的卷积步长设置为2,为了不让原始图像的分辨率不会降低过快,不会使得图像分辨率降低过快导致信息损失的太快。
增加了第三、第四个卷积层的卷积核个数
在AlexNet中,第三个卷积层有384个卷积核,而第四个卷积层有256个卷积核。
在ZFNet中,第三个卷积层的卷积核个数增加到了512个,而第四个卷积层的卷积核个数增加到了1024个。ZFNet在第三个和第四个卷积层中增加了卷积核的个数。这样做的目的是增加网络的表达能力,以便更好地捕捉图像中的细节和特征。通过增加卷积核的个数,ZFNet可以更好地学习图像的细节和抽象特征,从而提高模型的性能和准确度。这些改进使得ZFNet在图像分类和计算机视觉任务中取得了较好的结果。
VGG
VGG是Oxford的Visual Geometry Group的组提出的(大家应该能看出VGG名字的由来了)。该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。

参考

VGG网络贡献
使用尺寸更小的 3 × 3 3 \times 3 3×3卷积串联来获得更大的感受野
对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以额增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
放弃使用 11 × 11 11 \times 11 11×11和 5 × 5 5 \times 5 5×5这样的大尺寸卷积核
使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
2个 3 × 3 3 \times 3 3×3卷积核串联,感受野为 5 × 5 5 \times 5 5×5

3个 3 × 3 3 \times 3 3×3卷积核串联,感受野为 7 × 7 7 \times 7 7×7

深度更深、非线性更强,网络的参数也更少;
比如,3个步长为1的3x3卷积核的一层层叠加作用可看成一个大小为7的感受野(其实就表示3个3x3连续卷积相当于一个7x7卷积),其参数总量为 ( 3 × 3 × C ) × C × 3 = 27 C 2 (3 \times 3 \times C) \times C \times 3 = 27C^2 (3×3×C)×C×3=27C2
如果直接使用7x7卷积核,其参数总量为 ( 7 × 7 × C ) × C = 49 C 2 (7 \times 7 \times C) \times C = 49C^2 (7×7×C)×C=49C2 ,这里 C 指的是输入和输出的通道数。很明显, 27 C 2 27C^2 27C2小于 49 C 2 49C^2 49C2,即减少了参数;而且3x3卷积核有利于更好地保持图像性质。
去掉了AlexNet中的局部响应归一化层(LRN)层。
网络结构

1、输入224x224x3的图片,经64个3x3的卷积核作两次卷积+ReLU,卷积后的尺寸变为224x224x64
2、作max pooling(最大化池化),池化单元尺寸为2x2(效果为图像尺寸减半),池化后的尺寸变为112x112x64
3、经128个3x3的卷积核作两次卷积+ReLU,尺寸变为112x112x128
4、作2x2的max pooling池化,尺寸变为56x56x128
5、经256个3x3的卷积核作三次卷积+ReLU,尺寸变为56x56x256
6、作2x2的max pooling池化,尺寸变为28x28x256
7、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为28x28x512
8、作2x2的max pooling池化,尺寸变为14x14x512
9、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为14x14x512
10、作2x2的max pooling池化,尺寸变为7x7x512
11、与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)
12、通过softmax输出1000个预测结果
主要改进
输入去均值
AlexNet和ZFNet的输入去均值:求所有图像向量的均值,最后得出一个与原始图像大小相同维度的均值向量。
VGG输入去均值:求所有图像向量的RGB均值,最后得到的是一个3×1的向量 [R,G,B]
小卷积核串联代替大卷积核
增加了非线性能力。
多个小尺寸卷积核串联可以得到与大尺寸卷积核相同的感受野。
与高斯核不同,高斯核中两个小卷积核组合卷积核大卷积核卷积结果相同。但是卷积神经网络中的卷积核,多个小卷积核组合和大卷积核结果不同,但是感受野相同。
无重叠池化
窗口大小为2×2,步长为2。
卷积核个数逐层增加
前层卷积核少,是因为前层学习到的是图像的基元(点、线、边),基元很少,所以不需要很多的神经元学习,又前层的图像都比较大,若神经元很多,计算量会很大(K×m×m×D×K×n×n)。到后面的层时,包含很多的语义结构,需要更多的卷积核学习。
为什么在VGG网络前四段里,每经过一次池化操作,卷积核个数就增加一倍?
1、池化操作可以减少特征图尺寸,降低显存占用
2、增加卷积核个数有助于学习更多的结构特诊,但会增加网络参数数量以及内存消耗
3、一减一增的设计平衡了识别精度与存储、计算开销最终提升了网络性能
为什么卷积核个数增加到512后就不再增加了?
1、第一个全连接层含102M参数,占总参数个数的74%
2、这一层的参数个数是特征图的尺寸与个数的乘积
3、参数过多容易过拟合,且不易被训练如果将最后一层卷积核个数增加至1024,这一层参数个数为: 7 × 7 × 1024 × 4096 = 205520896 ≈ 200 M 7 \times 7 \times 1024 \times 4096 = 205520896 \approx 200M 7×7×1024×4096=205520896≈200M
GoogLeNet
参考
GoogLeNet模型结构

创新点
串联结构(如VGG)存在的问题
后面的卷积层只能处理前层输出的特征图;前层因某些原因(比如感受野限制)丢失重要信息,后层无法找回。
解决方案:每一层尽量多的保留输入信号中的信息。
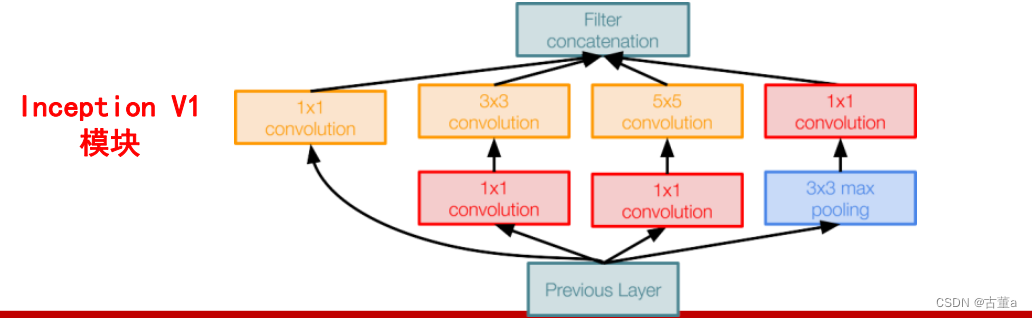
Inception结构,它能保留输入信号中的更多特征信息
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。

1、采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2、 之所以卷积核大小采用1、3和5,主要是为了方便对齐。
设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征。
3、3×3 max pooling 可理解为非最大化抑制。
文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。保留且加强了原图中比较重要的信息。
4、网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
5、1×1 3×3 5×5卷积,及3×3max pooling,通过设定合适的padding都会得到相同维度的特征,然后将这些特征直接拼接在一起。但是,使用5x5的卷积核仍然会带来巨大的计算量。
为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
具体改进后的Inception Module如下图:
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。

假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。

层数更深、参数更少、计算效率更高、非线性表达能力也更强

去掉了AlexNet的前两个全连接层,并采用了平均池化
这一设计使得GoogLeNet只有500万参数,比AlexNet少了12倍

引入了辅助分类器
克服了训练过程中的梯度消失问题

问题1:平均池化向量化与直接展开向量化有什么区别?

特征响应图中位置信息不太重要,平均池化,忽略位置信息,可以很大节省计算量。问题2: 利用1 x1卷积进行压缩会损失信息吗?

不会,假设图像或特征响应图深度通道为64,其中记录信息的只有少数,对应的向量非常稀疏,且其后的每个卷积核(深度通道也为64)都作用在这64个通道上。 经过压缩,并不会影响图像原始信息的记录。
ResNet
Resnet之后的网络应用在ImageNet之外的问题上,效果不一定好。
参考
ResNet论文:Deep Residual Learning for Image Recognition
产生背景
卷积网络深度越深,是否性能越好?
实验:持续向一个“基础”的卷积神经网络上面叠加更深的层数会发生什么?

贡献
残差模块
研究者考虑了这样一个问题:
浅层网络学习到了有效的分类模式后,如何向上堆积新层来建立更深的网络,使其满足即使不能提升浅层网络的性能,深层网络也不应降低性能。提出了一种残差模块,通过堆叠残差模块可以构建任意深度的神经网络,而不会出现“退化”现象。

前向传递:原始信息一直被保存的很好,没有丢失信息,信号不容易衰减,前向信息流就很顺畅。
反向传递:即使F(x)=0,反向信息也可以传递。
类比锐化过程理解,原图x+细节F(x)=锐化H(x)。

残差结构
残差结构能够避免普通的卷积层堆叠存在信息丢失问题,保证前向信息流的顺畅。
残差结构能够应对梯度反传过程中的梯度消失问题,保证反向梯度流的通顺。

X之后的1×1卷积核:降维,减少3×3卷积的运算量。
conv(3×3)之后的1×1卷积核:升维(还原X的维度),为了实现X+F(X)。

批归一化
提出了批归一化方法来对抗梯度消失,该方法降低了网络训练过程对于权重初始化的依赖。
ReLU激活函数的初始化方法
提出了一种针对ReLU激活函数的初始化方法。
网络结构
为什么残差网络性能好?
一种典型的解释:残差网络可以看作是一种集成模型!
-
相关阅读:
营业执照识别易语言代码
MySQL字符集大小写不敏感导致的主键冲突问题记录
同行北京丨科士达聚渠道之力,共驱数据中心低碳高效发展
Android自动化测试工具调研
项目01—基于nignx+keepalived双vip的负载均衡高可用Web集群
移动云获取推拉流地址
自动群发节日祝福,1 行 Python 代码搞定,小白可用
SPA项目开发之登录注册
NAOMI代码详解
Pro_07丨波动率因子3.0与斜率因子
- 原文地址:https://blog.csdn.net/m0_49683806/article/details/132921660

