-
TCP详解之重传机制
TCP详解之重传机制
TCP 实现可靠传输的方式之一,是通过序列号与确认应答。
在 TCP 中,当发送端的数据到达接收主机时,接收端主机会返回一个确认应答消息,表示已收到消息。

但在错综复杂的网络,并不一定能如上图那么顺利能正常的数据传输,万一数据在传输过程中丢失了呢?所以TCP针对数据包丢失的情况,会用重传机制解决。接下来说说常见的重传机制:
1. 超时重传
重传机制的其中一个方式,就是在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的ACK确认应答报文,就会重发该数据,也就是我们常说的超时重传。
TCP会在一下两种情况发生超时重传:
- 数据包丢失
- 确认应答丢失
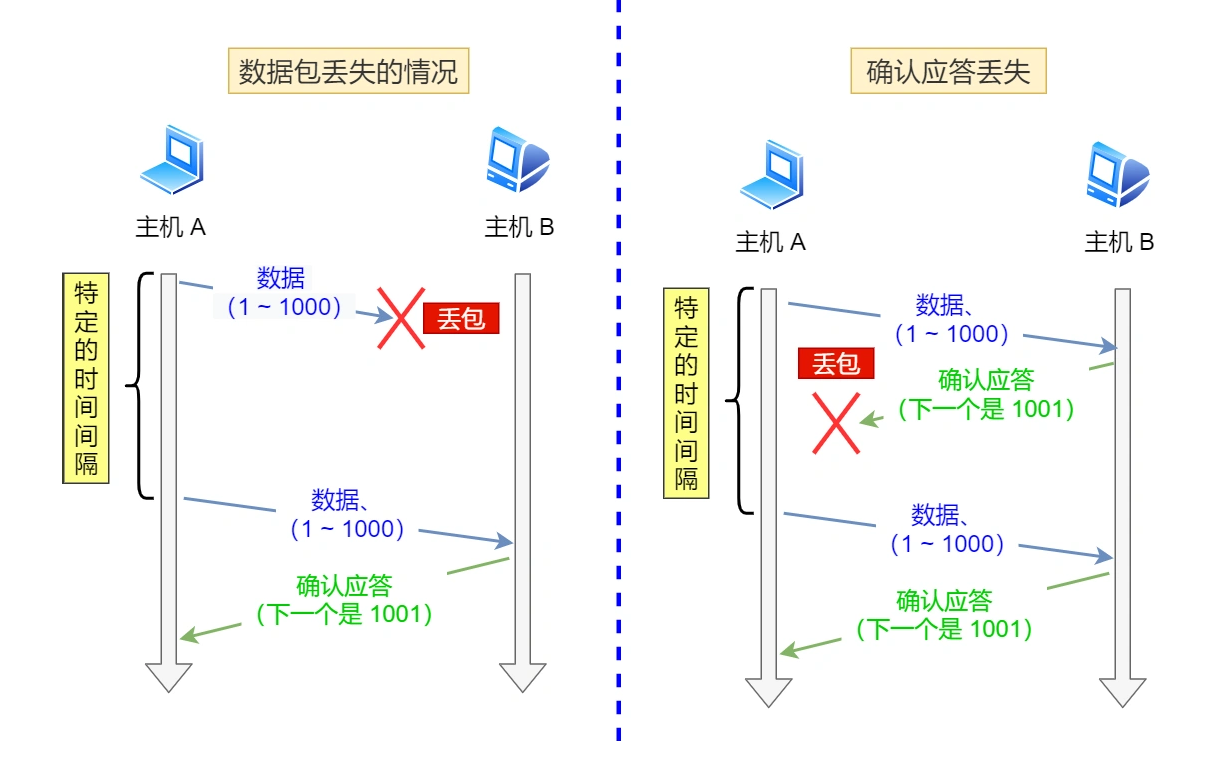
超时时间应该设置为多少呢?
我们先来了解一下什么是
RTT(Round-Trip Time往返时延),从下图我们可以知道:
RTT指的是数据发送时刻到接收到确认应答的时刻的差值,也就是包的往返时间。超时重传时间是以RTO(Retransmission Timeout超时重传时间)表示。假设在重传的情况下,超时时间RTO「较长或较短」时,会发生什么事情呢?
上图中有两种超时时间不同的情况:
- 当超时时间RTO较大时,重发就慢,丢了老半天才重发,就没有效率,性能差;
- 当超时时间RTO较小时,会导致可能并没有丢就重发,于是重发的就快,会增加网络拥堵,导致更多的超时,更多的超时导致更多的重发。
根据上述的两种情况,我们可以得知,超时重传时间RTO的值应该略大于报文往返RTT的值。

如果超时重传的数据,再次超时的时候,又需要重传的时候,TCP的策略是超时时间加倍。
也就是每次当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍。两次超时,就说明网络环境差,不宜频繁反复发送。
超时触发重传存在的问题是,超时周期可能相对较长。那是不是可以有更快的方式呢?
于是就可以用「快速重传」机制来解决超时重传的时间等待。
2. 快速重传
TCP还有另外一种快速重传(Fast Retransmit)机制,它不以时间为驱动,而是以数据驱动重传。快速重传机制,是如何工作的呢,起始很简单,看下图:

在上图,发送方发出了 1,2,3,4,5 份数据:
- 第一份 Seq1 先送到了,于是就 ACK 回 2;
- Seq2 因为某些原因没收到,Seq3 到达了,于是还是 ACK回 2;
- 后面的 Seq4 和 Seq5 都到了,但还是 ACK回 2,因为 Seq2 还是没有收到;
- 发送端收到了三个 ACK= 2 的确认,知道了 Seq2 还没有收到,就会在定时器过期之前,重传丢失的 Seq2。
- 最后,收到了 Seq2,此时因为 Seq3,Seq4,Seq5 都收到了,于是 ACK回 6 。
所以,快速重传的工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。
快速重传机制只解决了一个问题,就是超时时间的问题,但是它依然面临着另外一个问题。就是重传的时候,是重传一个,还是重传所有的问题。
举个例子,假设发送方发了 6 个数据,编号的顺序是 Seq1 ~ Seq6 ,但是 Seq2、Seq3 都丢失了,那么接收方在收到 Seq4、Seq5、Seq6 时,都是回复 ACK2 给发送方,但是发送方并不清楚这连续的 ACK2 是接收方收到哪个报文而回复的, 那是选择重传 Seq2 一个报文,还是重传 Seq2 之后已发送的所有报文呢(Seq2、Seq3、 Seq4、Seq5、 Seq6) 呢?
- 如果只选择重传 Seq2 一个报文,那么重传的效率很低。因为对于丢失的 Seq3 报文,还得在后续收到三个重复的 ACK3 才能触发重传。
- 如果选择重传 Seq2 之后已发送的所有报文,虽然能同时重传已丢失的 Seq2 和 Seq3 报文,但是 Seq4、Seq5、Seq6 的报文是已经被接收过了,对于重传 Seq4 ~Seq6 折部分数据相当于做了一次无用功,浪费资源。
可以看到,不管是重传一个报文,还是重传已发送的报文,都存在问题。
为了解决不知道该重传哪些 TCP 报文,于是就有
SACK方法3. SACK
还有一种实现重传机制的方式叫:
SACK( Selective Acknowledgment), 选择性确认。这种方式需要在 TCP 头部「选项」字段里加一个
SACK的东西,它可以将已收到的数据的信息发送给「发送方」,这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。如下图,发送方收到了三次同样的 ACK 确认报文,于是就会触发快速重传机制,通过
SACK信息发现只有200~299这段数据丢失,则重发时,就只选择了这个 TCP 段进行重复。
如果要支持
SACK,必须双方都要支持。在 Linux 下,可以通过net.ipv4.tcp_sack参数打开这个功能(Linux 2.4 后默认打开)。4. Duplicate SACK
Duplicate SACK 又称
D-SACK,其主要使用了 SACK 来告诉「发送方」有哪些数据被重复接收了。下面举例两个栗子,来说明
D-SACK的作用。栗子一号:ACK 丢包

- 「接收方」发给「发送方」的两个 ACK 确认应答都丢失了,所以发送方超时后,重传第一个数据包(3000 ~ 3499)
- 于是「接收方」发现数据是重复收到的,于是回了一个 SACK = 3000~3500,告诉「发送方」 3000~3500 的数据早已被接收了,因为 ACK 都到了 4000 了,已经意味着 4000 之前的所有数据都已收到,所以这个 SACK 就代表着
D-SACK。 - 这样「发送方」就知道了,数据没有丢,是「接收方」的 ACK 确认报文丢了。
栗子二号:网络延时

- 数据包(1000~1499) 被网络延迟了,导致「发送方」没有收到 ACK 1500 的确认报文。
- 而后面报文到达的三个相同的 ACK 确认报文,就触发了快速重传机制,但是在重传后,被延迟的数据包(1000~1499)又到了「接收方」;
- 所以「接收方」回了一个 SACK=1000~1500,因为 ACK 已经到了 3000,所以这个 SACK 是 D-SACK,表示收到了重复的包。
- 这样发送方就知道快速重传触发的原因不是发出去的包丢了,也不是因为回应的 ACK 包丢了,而是因为网络延迟了。
可见,
D-SACK有这么几个好处:- 可以让「发送方」知道,是发出去的包丢了,还是接收方回应的 ACK 包丢了;
- 可以知道是不是「发送方」的数据包被网络延迟了;
- 可以知道网络中是不是把「发送方」的数据包给复制了;
在 Linux 下可以通过
net.ipv4.tcp_dsack参数开启/关闭这个功能(Linux 2.4 后默认打开)。 -
相关阅读:
软件自动化测试代码覆盖率
HAproxy反向代理与负载均衡
Java使用apache.poi生成excel插入word中
通过YOLO5训练自己的数据集(以交通标志牌数据集TT100k为例)
连花清瘟卖断货?近一个月解热药价格暴涨33%,销额超206万元
2023届网易秋招|每人都有三次机会哦
altera系列fifo和ram
[管理与领导-102]:经营与管理的关系:攻守关系;武将文官关系;开疆拓土与守护城池的关系;战斗与练兵的关系;水涨船高,水落船低的关系。
【GNN Panel】图神经网络及其在结构建模中的应用
JavaScript-bind实现原理
- 原文地址:https://blog.csdn.net/weixin_52724550/article/details/132955115