-
优化器的使用
代码示例:
import torch import torchvision from torch import nn from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter # 加载数据集转化为Tensor数据类型 dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor() , download=True) # 使用dataloader加载数据集 dataloader = DataLoader(dataset, batch_size=1) class Kun(nn.Module): def __init__(self): super(Kun, self).__init__() self.model1 = Sequential( Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), MaxPool2d(kernel_size=2), Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2), MaxPool2d(kernel_size=2), Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2), MaxPool2d(kernel_size=2), Flatten(), # 将数据进行展平 64*4*4 =1024 Linear(in_features=1024, out_features=64), Linear(64, 10) ) def forward(self, x): x = self.model1(x) return x loss = nn.CrossEntropyLoss() kun = Kun() # 设置优化器 optim = torch.optim.SGD(kun.parameters(), lr=0.01) # 相当于一轮学习 for data in dataloader: imgs, target = data outputs = kun(imgs) result = loss(outputs, target) optim.zero_grad() # 将所有参数梯度调整为0 result.backward() # 调用损失函数的反向传播求出每个梯度 optim.step() # 循环调优- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
增加训练次数:
import torch import torchvision from torch import nn from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter # 加载数据集转化为Tensor数据类型 dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor() , download=True) # 使用dataloader加载数据集 dataloader = DataLoader(dataset, batch_size=1) class Kun(nn.Module): def __init__(self): super(Kun, self).__init__() self.model1 = Sequential( Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), MaxPool2d(kernel_size=2), Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2), MaxPool2d(kernel_size=2), Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2), MaxPool2d(kernel_size=2), Flatten(), # 将数据进行展平 64*4*4 =1024 Linear(in_features=1024, out_features=64), Linear(64, 10) ) def forward(self, x): x = self.model1(x) return x loss = nn.CrossEntropyLoss() kun = Kun() # 设置优化器 optim = torch.optim.SGD(kun.parameters(), lr=0.01) for epoch in range(20): running_loss = 0.0 # 记录每轮学习损失的总和 # 相当于一轮学习 for data in dataloader: imgs, target = data outputs = kun(imgs) result = loss(outputs, target) optim.zero_grad() # 将所有参数梯度调整为0 result.backward() # 调用损失函数的反向传播求出每个梯度 optim.step() # 循环调优 running_loss += result print(running_loss)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
结果示例:每轮的损失参数不断减小
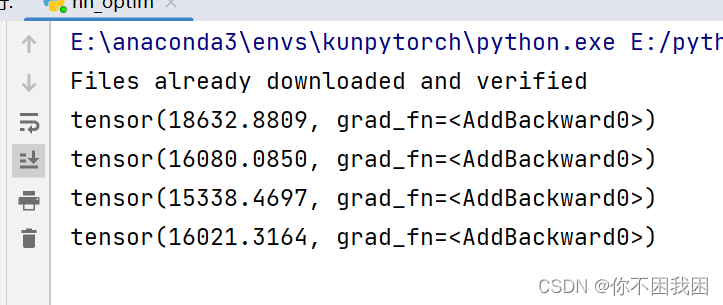
造成损失参数不降反升,是lr设置过大
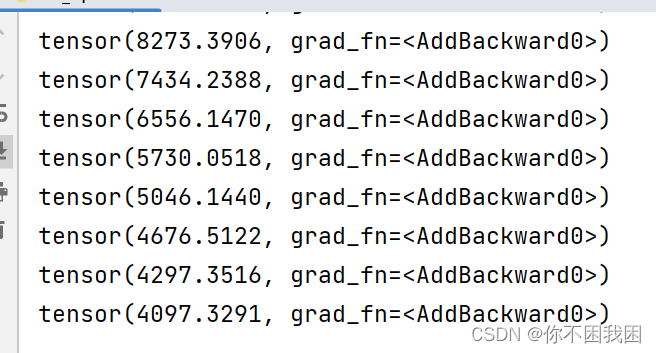
调整lr=0.001
optim = torch.optim.SGD(kun.parameters(), lr=0.001)- 1
结果:
-
相关阅读:
C/C++语言100题练习计划 80——好多好多符(二分查找实现)
分享即时通讯开发之Netty高性能原理
TiDB Lightning 故障处理
作业-11.22
最频繁被问到的SQL面试题
Activiti 工作流引擎 详解
数学建模学习(95):MO-JAYA算法对多目标(多元)函数寻优求解
QT在scrollArea中添加按钮,可滚动
买卖股票的最佳时机(系列)
web前端三大主流框架
- 原文地址:https://blog.csdn.net/Kunjpg/article/details/132921495
