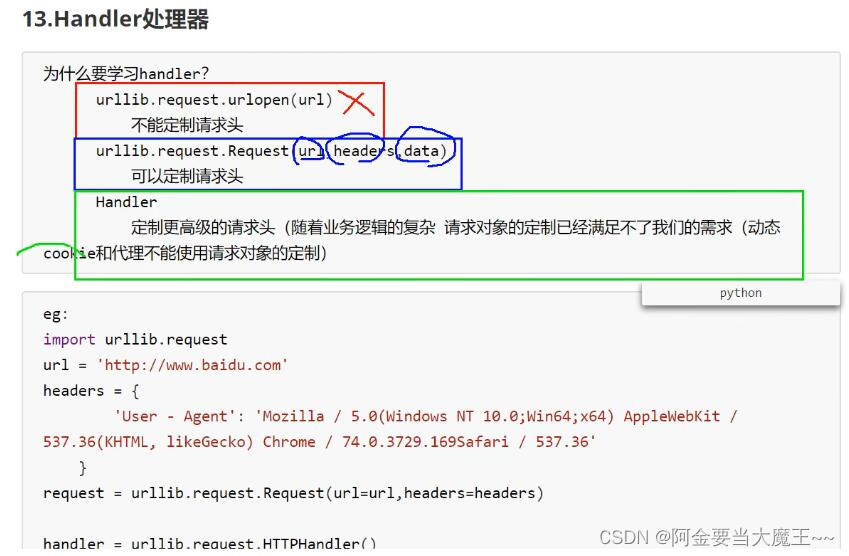
1 使用urlencode 多个参数请求使用
# https://www.baidu.com/s?wd=周杰伦&sex=男 网页
base_url = 'https://www.baidu.com/s?'
new_data = urllib.parse.urlencode(data)
url = base_url + new_data
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36 Edg/116.0.0.0"}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode("utf8")
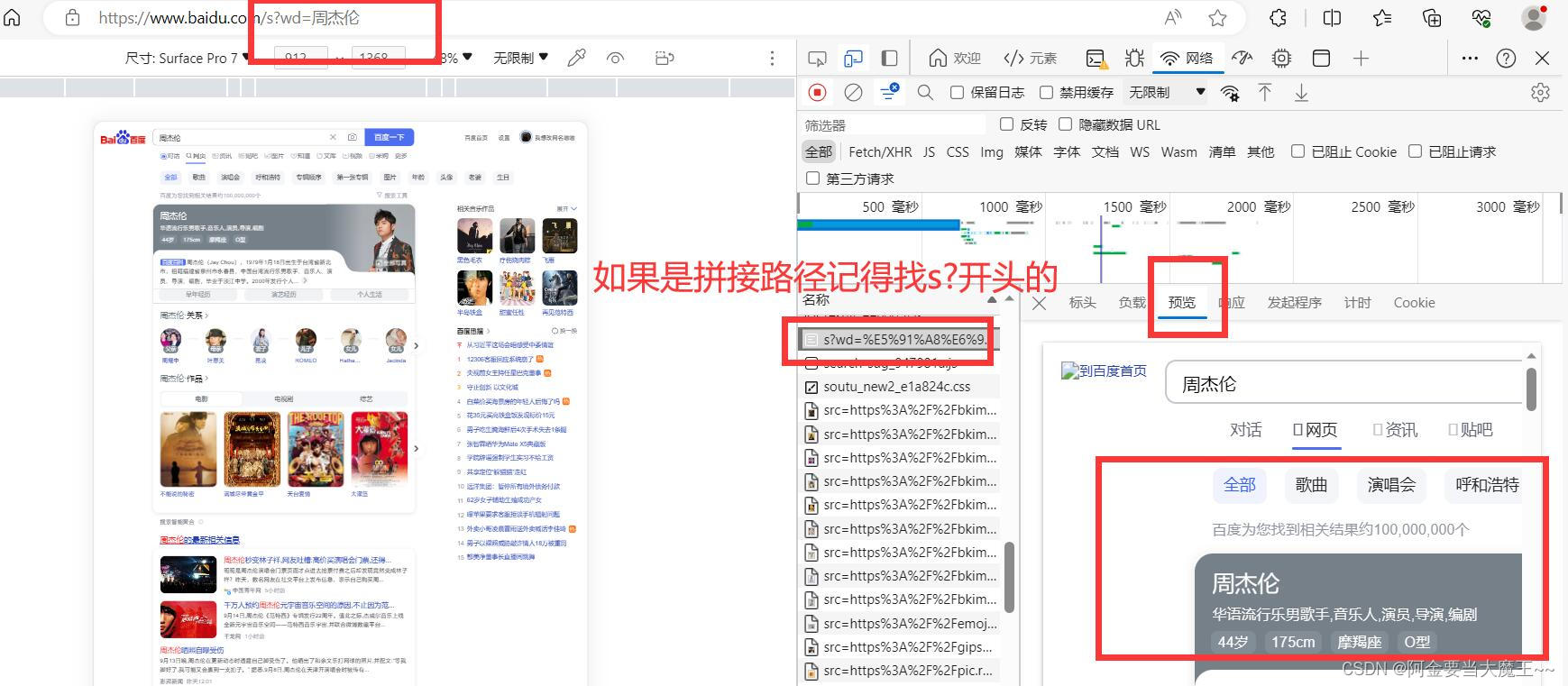
2 百度翻译post请求 post无法添加路径
request = urllib.request.Request(url=url, headers=headers, data=data)
# 路径 在浏览器 F12找到 对应自己需要的路径
url = 'https://fanyi.baidu.com/sug'
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36 Edg/116.0.0.0"}
data = urllib.parse.urlencode(data).encode('utf-8')
# 防止反爬 post无法拼接路径 所有只能在 requst中定义 定义数据
request = urllib.request.Request(url=url, headers=headers, data=data)
response = urllib.request.urlopen(request)
content = response.read().decode("utf-8")
obj = json.loads(content)
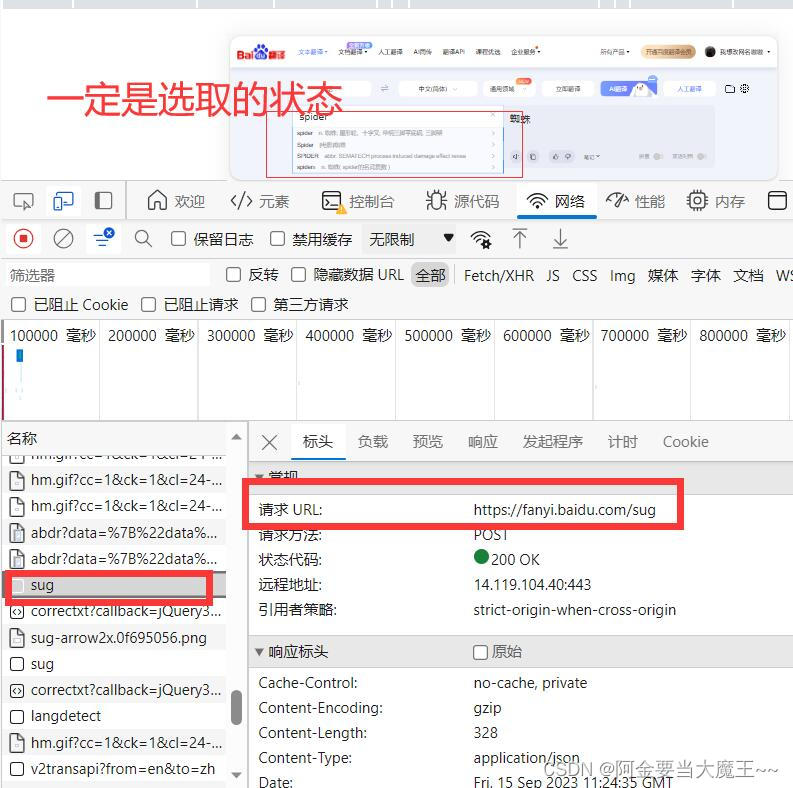
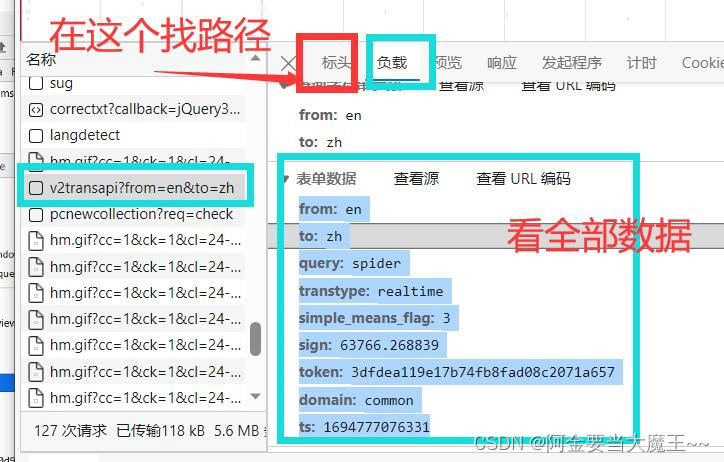
3 百度翻译全部数据获取
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
headers = {"Cookie":"BIDUPSID=359429789B4E589B318E621011F98A01; PSTM=1642150308; __yjs_duid=1_509dd28c4aec6cb726c25a04881a2a151640083333034; BDUSS=lxa25GVFZQZ0RmYUJHRnp2eERudWJ6eVBiOTE0VmJVVllJdXlKY0QzYkowaDVpRVFBQUFBJCQAAAAAAAAAAAEAAADMN6iOb8rFyKW1xLCuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAMlF92HJRfdhVX; BDUSS_BFESS=lxa25GVFZQZ0RmYUJHRnp2eERudWJ6eVBiOTE0VmJVVllJdXlKY0QzYkowaDVpRVFBQUFBJCQAAAAAAAAAAAEAAADMN6iOb8rFyKW1xLCuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAMlF92HJRfdhVX; REALTIME_TRANS_SWITCH=1; HISTORY_SWITCH=1; FANYI_WORD_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; H_WISE_SIDS=219946_234020_131862_216850_213356_214798_219942_213030_110085_243885_244478_244720_240590_245600_248174_247146_256083_254833_256348_256739_254317_257586_255230_257995_258723_258838_258984_258958_230288_256222_259708_258773_234295_234208_257262_259643_255910_254300_260278_256230_260356_260364_253022_255212_258081_260330_260352_251786_260805_260836_259408_259300_259422_259584_260717_261043_261028_261116_258578_261664_261471_261712_261629_261863_262052_262067_259033_262184_262165_262226_262229_261410_262263_260441_259403_236312_262487_262296_262452_261869_262621_262608_262606_262597_249410_259518_259944_262775_262743_262747_262906_263074_256999_263203_262987_262282_253901_263301_263278_243615_261683_261620_259447_263416_245653_263549_257289_8000083_8000126_8000142_8000150_8000156_8000164_8000171_8000177_8000195_8000203; H_WISE_SIDS_BFESS=219946_234020_131862_216850_213356_214798_219942_213030_110085_243885_244478_244720_240590_245600_248174_247146_256083_254833_256348_256739_254317_257586_255230_257995_258723_258838_258984_258958_230288_256222_259708_258773_234295_234208_257262_259643_255910_254300_260278_256230_260356_260364_253022_255212_258081_260330_260352_251786_260805_260836_259408_259300_259422_259584_260717_261043_261028_261116_258578_261664_261471_261712_261629_261863_262052_262067_259033_262184_262165_262226_262229_261410_262263_260441_259403_236312_262487_262296_262452_261869_262621_262608_262606_262597_249410_259518_259944_262775_262743_262747_262906_263074_256999_263203_262987_262282_253901_263301_263278_243615_261683_261620_259447_263416_245653_263549_257289_8000083_8000126_8000142_8000150_8000156_8000164_8000171_8000177_8000195_8000203; MCITY=-53%3A; BAIDUID=4FA510A05410004B33EF51007DA08923:FG=1; BA_HECTOR=01852k8h2704a48h24058g8i1ig851k1p; ZFY=OyVrCDKol7NbNTbKUbw885OfM9tG9YDHAVQiqBjirHg:C; BAIDUID_BFESS=4FA510A05410004B33EF51007DA08923:FG=1; delPer=0; PSINO=1; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[C0sZzZJZb70]=mk3SLVN4HKm; H_PS_PSSID=; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; BCLID=6775486379151272863; BCLID_BFESS=6775486379151272863; BDSFRCVID=S-FOJexroG0ZmSbq3aoeqaaMUuweG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKLeOTHGCF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; BDSFRCVID_BFESS=S-FOJexroG0ZmSbq3aoeqaaMUuweG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKLeOTHGCF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tRAOoC_-tDvDqTrP-trf5DCShUFsttLjB2Q-XPoO3KJADfOPKjbHhn_L-fQuLRQf5mkf3fbgy4op8P3y0bb2DUA1y4vp0toW3eTxoUJ2-KDVeh5Gqq-KXU4ebPRiWPQ9Qgbx5hQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0hD89DjKKD6PVKgTa54cbb4o2WbCQL56P8pcN2b5oQT8lhJbab6JKaKTD3RjzQ45beq06-lOUWJDkXpJvQnJjt2JxaqRC3JjOsl5jDh3MKToDb-oteltHB2Oy0hvcBn5cShnjLUjrDRLbXU6BK5vPbNcZ0l8K3l02V-bIe-t2XjQh-p52f6_JtRIf3f; H_BDCLCKID_SF_BFESS=tRAOoC_-tDvDqTrP-trf5DCShUFsttLjB2Q-XPoO3KJADfOPKjbHhn_L-fQuLRQf5mkf3fbgy4op8P3y0bb2DUA1y4vp0toW3eTxoUJ2-KDVeh5Gqq-KXU4ebPRiWPQ9Qgbx5hQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0hD89DjKKD6PVKgTa54cbb4o2WbCQL56P8pcN2b5oQT8lhJbab6JKaKTD3RjzQ45beq06-lOUWJDkXpJvQnJjt2JxaqRC3JjOsl5jDh3MKToDb-oteltHB2Oy0hvcBn5cShnjLUjrDRLbXU6BK5vPbNcZ0l8K3l02V-bIe-t2XjQh-p52f6_JtRIf3f; APPGUIDE_10_6_2=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1694776408; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1694777058; ab_sr=1.0.1_ZWNmZjBlMjY0OWYyNjA1ZTYxNDRhZTI2NjIyNmJjOTcwZGE5ZjU3OTQ1Yjg3ZDFlMTgyNDM1MDczOTgwMmE4YWIwMGE1NmM5NjliNzAzY2YwYmE1MDkwY2M5YjYzODdiOWY2N2Y1OGRjNmRkODdkOTc5MTVhY2YxNjQxMTA1ZjZlMDNiYjVlMDQxNWNhNzk2OGY0NjM0OGM3YjBiYzc5ODQzZmY1N2IwYTA3MzQ0Njg2ZTYyYWFjY2RkYTNlYTUy"}
# data 在foom data找到全部数据添加
"simple_means_flag": "3",
"token": "3dfdea119e17b74fb8fad08c2071a657",
data = urllib.parse.urlencode(data).encode('utf-8')
# 防止反爬 post无法拼接路径 所有只能在 requst中定义
request = urllib.request.Request(url=url, headers=headers, data=data)
response = urllib.request.urlopen(request)
content = response.read().decode("utf-8")
obj = json.loads(content)
4 豆瓣get请求 第一页
url = 'https://movie.douban.com/chart'
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36 Edg/116.0.0.0"}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode("utf-8")
fp = open('douban.json', 'w', encoding='utf-8')


5. get豆瓣请求多页数据下载
# https://movie.douban.com/top250?start=0&filter=
# https://movie.douban.com/top250?start=25&filter=
# https://movie.douban.com/review/best/?start=0
# https://movie.douban.com/review/best?start=20
def create_request(page):
base_url = "https://movie.douban.com/top250?"
'start' :( page - 1 )*10, #定义页数
data = urllib.parse.urlencode(data)
# 拼接打印路径 base_url +data 成一个完整路径
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36 Edg/116.0.0.0"}
request = urllib.request.Request(url=url,headers=headers)
# # 定义第二个方法 定义get_conten 请求数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf_8')
# # 定义第二个方法 定义down_load 下载
def down_load(page,content): # 获取 page页码
with open('doban'+ str(page) +'.json','w',encoding='utf-8')as fp:
if __name__ == '__main__':
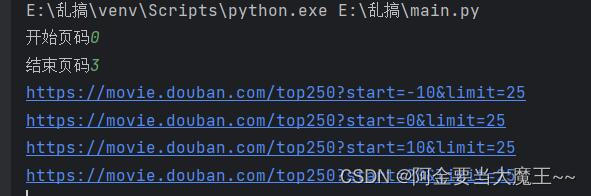
start_page = int(input('开始页码'))
end_page = int(input('结束页码'))
for page in range(start_page,end_page+1):
request = create_request(page)
content = get_conten(request)

6.必胜客多页下载 和post差不多轻微改动
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
def create_request(page):
base_url = "http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname"
data = urllib.parse.urlencode(data).encode('utf-8')
# # 拼接打印路径 base_url +data 成一个完整路径
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36 Edg/116.0.0.0"}
request = urllib.request.Request(url=base_url,headers=headers,data=data)
# # 定义第二个方法 定义get_conten 请求数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf_8')
# # 定义第二个方法 定义down_load 下载
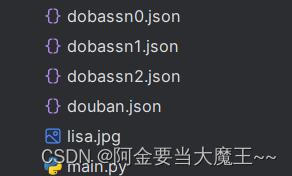
def down_load(page,content): # 获取 page页码
with open('dobassn'+ str(page) +'.json','w',encoding='utf-8')as fp:
if __name__ == '__main__':
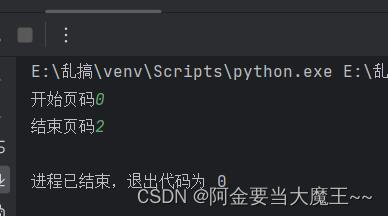
start_page = int(input('开始页码'))
end_page = int(input('结束页码'))
for page in range(start_page,end_page+1):
request = create_request(page)
content = get_conten(request)
7.urllib异常报错反馈
url = "https://www.goudan.com"
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36 Edg/116.0.0.0"
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf_8')
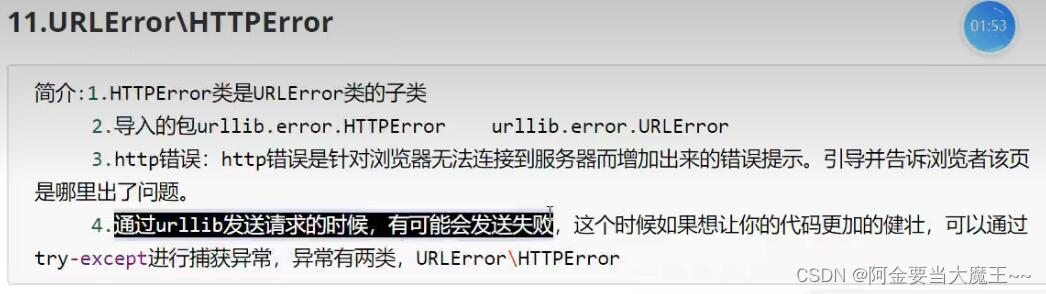
except urllib.error.HTTPError:
except urllib.error.URLError:

8. # handler 代理请求 爬取次数太多会被封锁 所以要进行代理
url = 'https://baike.baidu.com/'
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36 Edg/116.0.0.0"
request = urllib.request.Request(url=url,headers=headers)
# response = urllib.request.urlopen(request)
handler = urllib.request.HTTPHandler()
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode("utf8")