-
OneFormer: One Transformer to Rule Universal Image Segmentation论文笔记
1. Motivation

- 通用图像分割并不是本文所提出的一个概念。远有UperNet,近有Mask2Former、K-Net,这些网络也都是作为一种通用分割架构被提出。
- 但是,本文认为,这些网络对于语义分割、实例分割、全景分割三种虽然可以做到模型结构的统一,但是还是需要特定任务单独训练得到各自专用的模型,作者将这一类模型称之为
semi-universal。 - 本文提出的OneFormer不仅模型结构统一,同时,语义分割、实例分割、全景分割只需要在全景分割数据集训练一遍,据可以得到一个三种任务通用的模型用于推理,达到真正意义上的
universal。
2. 方法

2.1 与Mask2Former的相同之处
先不看(b)模块中与文本相关的内容,OneFormer的其余部分模型结构与Mask2Former基本一致:
- Backbone:使用ImageNet预训练的网络编码多尺度特征;
- Pixel Decoder:使用Multi-Scale Deformable Transformer (MSDeformAttn) 建模多尺度上下文特征;
- Transformer Decoder:使用
{1/8、1/16、1/32}三个分辨率的特征图对object query进行更新,李勇的主要结构是cross attention、self attention、FFN; - 利用更新后的object query预测
(K+1)个类别; - 利用更新后的object query和
1/4特征图点积给每个query生成对应的binary mask;
2.2 OneFormer创新之处
相比于Mask2Former,OneFormer的创新点或者说不同之处有以下几点:
- Task Conditioned Joint Training:为了将语义分割、实例分割、全景分割三个任务在一个统一的架构中进行统一训练,需要引入特定任务的任务提示词。
- Query Representations:除了Mask2Former这一类方法中的用到的object query,为方便理解称之为visual query,本文提出了text query,语义分割、实例分割、全景分割都有各自对应的不同的text query。
- Task Guided Contrastive Queries:计算visual query和text query之间的对比损失,因为不同任务的text query是不同的,这样做就可以使得不同任务训练得到的visual query能够具有区分度;
2.3 Task Conditioned Joint Training
- 首先,对于每种任务,使用
the task is { }来构造任务提示词 I t a s k I_{task} Itask ,该提示词随后会经过Tokenize和Embedding以及MLP,得到task-token Q t a s k Q_{task} Qtask 。 - 此外,如下图所示,对于每种任务,统计其中出现的各类thing或者stuff的数目,采用
a photo with a {CLS}这样的短语构造 T l i s t T_{list} Tlist 序列,。为了使得batch内部的文本长度对齐,需要使用a/an {task} photo这样的短语进行padding,代表no-object,padding后的结果是 T p a d T_{pad} Tpad。

2.4 Query Representations
Query Representations部分主要介绍text query Q t e x t Q_{text} Qtext 和object query Q Q Q是如何构造和初始化的:
-
Q t e x t Q_{text} Qtext:将 T p a d T_{pad} Tpad 进行 Tokenize 以及Embedding,随后采用6层transformer encoder得到 N t e x t N_{text} Ntext个Embedding。然后,将 N c t x N_{ctx} Nctx个可学习的Embedding和 N t e x t N_{text} Ntext个embedding连接起来,最终得到 N N N 个text query Q t e x t Q_{text} Qtext。

-
Q Q Q:首先,将 Q t a s k Q_{task} Qtask 复制 N − 1 N-1 N−1 次,的到初始化后的object query Q ′ Q' Q′,然后,使用
1/4特征图对 Q ′ Q' Q′ 进行更新(使用2层transformer),最后,将 Q t a s k Q_{task} Qtask 和 Q ′ Q' Q′ 连接得到 N N N 个object query Q Q Q。
2.4 Task Guided Contrastive Queries
将语义分割、实例分割、全景分割统一在同一个模型中的关键挑战在于,怎么为每个任务生成任务特定的object query,那么,该如何让每种任务的object query之间彼此区分呢?
本文的解决方案是,计算text query Q t e x t Q_{text} Qtext 和object query Q Q Q 之间的对比损失,因为 Q t e x t Q_{text} Qtext是从特定任务的GT中通过统计thing和stuff的数量得到的,所以不同任务的 Q t e x t Q_{text} Qtext之间是彼此区分的,那么只需要将 Q Q Q 和 Q t e x t Q_{text} Qtext 对齐。
所采用的对比损失如下:

B B B 是一个batch内部的object-text pairs.3. 实验
3.1 BenchMarks


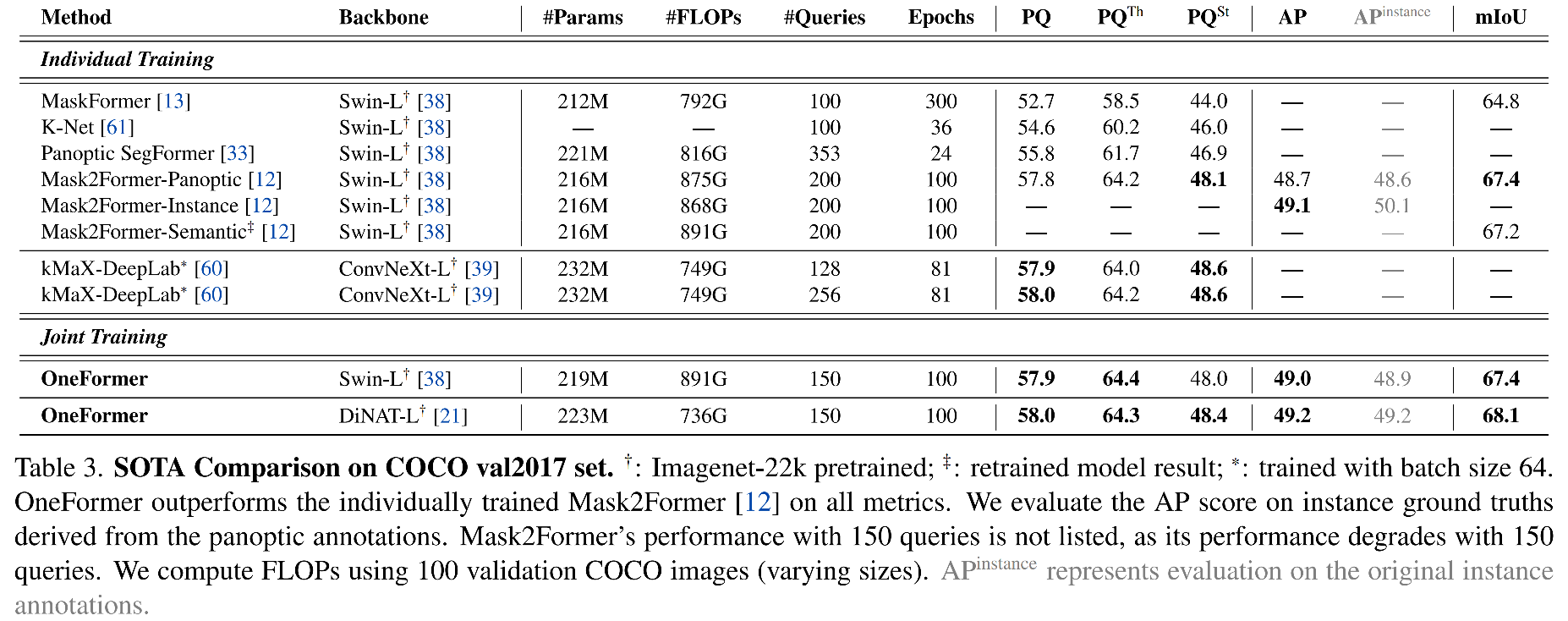
3.2 Ablation Studies

3.3 超参数实验

-
相关阅读:
node.js+uniapp(vue),阿里云短信验证码
Python程序员常犯的编码错误(三)
项目一:《小米官网》jQuery重构
DBCO-amine-Oxalate DBCO-氨基-乙二酸盐
java计算机毕业设计基于springboot大学生招聘简历投递系统
promise.catch和promise.then后的then是否会执行
centos软件设置开机启动的方式
跨端必须要掌握的uniapp(3),前端基础
Shell脚本:三剑客(AWK)
注意力机制 - Bahdanau注意力
- 原文地址:https://blog.csdn.net/xijuezhu8128/article/details/132831476