-
小节8:Python之文件操作
1、文件在哪里?
如果用代码对文件进行操作,需要先找到那个文件
MacOS/Linux:斜杠/ 表示根目录,一切的文件、目录都存放在根目录下面。
Windows系统:就不一样了,它每一个磁盘分区都有自己的根目录,所以用分区名加反斜杠\表示,如 D:\
虽然这MacOS/Linux与Windows这两种目录结构长得不一样,但定位文件的位置都可以用“相对路径”和“绝对路径”来表示
2、绝对路径&相对路径
绝对路径:
是从根目录出发的路径,由于以根目录为基准,对于Linux/MacOS等类Unix系统,绝对路径就是以斜杠/开头,路径中的每个目录之间用斜杠/进行分隔,最后以目标文件或目标目录结尾。对于Windows系统,绝对路径以分区名加反斜杠\开头,路径中的每个路径之间用反斜杠\进行分隔,同样最后以目标文件或目标目录结尾。
相对路径:
是从一个参照位置出发,也就是说,它表示从那个位置来看,其他文件处于什么路径。用相对路径时,我们用点 . 来表示参照文件当前所在的目录,用 .. 来表示更上一层的父目录,如果继续往上走,MacOS/Linux就用 ../..,而Windows就用..\..来表示。另外,./是可以省略的,所以在同一目录下的文件,想互相用相对路径找到彼此的话,可以直接使用文件名.
此外,很多编辑器也可以直接帮你复制文件的路径,比如Pycharm,如下图,可以获得文件的绝对路径(蓝色部分)和以最顶层项目目录为参考的相对路径(仓库根路径)

能够用绝对路径和相对路径来定位文件的位置后,我们就可以对文件进行操作了~~~
3、Python读文件
1)用f.read()读取:一次读取所有内容(适合体积不大的文件)
PS:如果是在同一文件夹下,.\其实也是可以省略的
- f = open(".\poem.txt", "r", encoding="utf-8")
- content = f.read()
- print(content)
- f.close()
其中,open()函数的第一个参数是文件的相对路径,第二个参数是模式,其中读模式可以省略,因为它是默认的模式,第三个参数是编码方式,最好写上,都是utf-8。content用来接收f文件读的内容,最后记得用close()函数释放资源。此外,当我们调用完一次f.read()后,Python的指针就已经指向了文件的末尾,所以当再次调用时,读到的内容将会是空字符串。要想重新读到完整内容,智能把文件关了再重新open
有的时候,我们很容易忘记写close()函数,所以可以用with的方式来写代码,就不需要写close()了,代码如下:
- f = open(".\poem.txt", "r", encoding="utf-8")
- content = f.read()
- print(content)
- f.close()
另外,在文件特别大的情况下,最好不要用read,因为读出来的内容会占很大的内存,甚至把内存给爆了。如果你需要一次性读完整个文件,可以给read传一个数字,表示读多少字节,那么下次调用read时,就会从那个位置继续往下读。代码如下:
- f = open(".\poem.txt", "r", encoding="utf-8")
- print("第1个到第5个字节的内容如下:")
- print(f.read(5))
- print("第6个到第10个字节的内容如下:")
- print(f.read(5))
输出:

2)用f.readline()读取:一次读取一行
此外,我们还可以用f.readline()函数来逐行读取,比如我们调用两次f.readline()方法,Python将会读取前两行的内容。
- with open(".\poem.txt", "r", encoding="utf-8") as f:
- print(f.readline())
- print(f.readline())
输出:
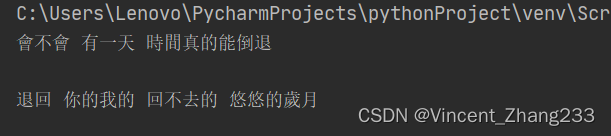
疑问:为什么用f.readlines()后输出的内容中间有一个额外的换行呢?
答案:因为f.readlines会把每行后面的换行符也读到,同时print()本身就会默认结尾换行,所以两个换行符结合起来,就会形成多一个的空行。
3)用f.readlines()读取
f.readlines()会返回一个列表,列表里面的每一个元素就是每一行的内容,并且每一行结尾的换行符也被读进去了,作为了文件的一部分。
- with open(".\poem.txt", "r", encoding="utf-8") as f:
- content = f.readlines()
- print(content)
- print(type(content))
输出:

应用场景:
一般f.readlines会结合for循环使用,我们通常把读到的内容赋值成一个变量,然后遍历它。
4、Python写文件
写文件操作和读文件操作很相似,只要把open()中的“r”改成"w"即可。用w模式打开文件进行写入的话,如果目标文件不存在,Python则会新建该文件;如果原本那个文件就已经存在,Python会把那个文件内容清空,所以用w模式之前要三四。
1)w模式写文件
注意:每次调用完write()后,它不会自动帮你换行,所以你要在内容中手动加入换行符。
- with open(".\data.txt", "w", encoding="utf-8") as f:
- f.write("Hello")
- f.write("world")

3)a模式写文件
问题:如果我不想把原本文件清空,只想在后面追加些内容,应该怎么办?
答案:那就不能用w模式了,应该将参数改为a,表示附加内容,而不是清空重写。代码如下:
- with open(".\data.txt", "a", encoding="utf-8") as f:
- f.write("\n窗前明月光,\n")
- f.write("疑是地上霜。\n")

另外,a模式和w模式一样,如果目标文件不存在,它会帮你新创建一个。
3)r+模式同时支持读写文件
无论是用w模式还是用a模式,你都无法用read()去读取文件原本的内容,如果硬要对文件对象调用read()方法,则程序会报错不支持读操作。那怎么办?
答案:用r+模式可以同时支持读写文件。而且write()调用后,会以追加的形式在文件后面添加新的内容
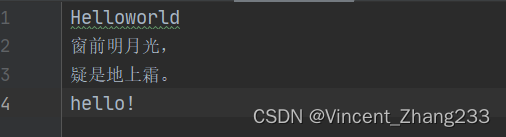
- with open(".\data.txt", "r+", encoding="utf-8") as f:
- print(f.read())
- f.write("hello!")

练习题:
任务1:在一个新的名字为“poem.txt”的文件里,写入以下内容:
我欲乘风归去,
又恐琼楼玉宇,
高处不胜寒。
任务2:在上面“poem.txt”文件的结尾处,添加以下两句:
起舞弄清影,
何似在人间。
- # 任务1:在一个新的名字为“poem.txt”的文件里,写入以下内容:
- # 我欲乘风归去,
- # 又恐琼楼玉宇,
- # 高处不胜寒。
- with open(".\poem.txt", "w", encoding="utf-8") as f:
- f.write("我欲乘风归去,\n又恐琼楼玉宇,\n高处不胜寒。")
- # 任务2:在上面“poem.txt”文件的结尾处,添加以下两句:
- # 起舞弄清影,
- # 何似在人间。
- with open(".\poem.txt", "a", encoding="utf-8") as f:
- f.write("\n起舞弄清影,\n何似在人间。")

-
相关阅读:
L1 频段卫星导航射频前端低噪声放大器芯片MS2659
文举论金:黄金原油全面走势分析策略指导。
Unity 之 定时调用函数的方法
不要忽视web渗透测试在项目中起到的重要性
Quill 文本编辑器
Kafka3.x核心速查手册二、客户端使用篇-6、消息发送幂等性
SpringSecurity OAuth2 配置 token有效时长
DotNetCore.Cap分布式事务实现最终一致性
localStorage设置过期时间用法
springcloud之自我介绍
- 原文地址:https://blog.csdn.net/Vincent_Zhang233/article/details/132898474