-
Pytorch学习整理笔记(一)
数据处理Dataset
主要是对Dataset的使用:
- 继承 Dataset
- 实现
init方法,主要是进行一些全局变量的定义,在对其初始化时需要赋值。 - 实现
getitem方法,获取每个数据 - 实现
len方法,获取数据size
from torch.utils.data import Dataset from PIL import Image import os class MyData(Dataset): # 继承 Dataset def __init__(self, root_dir, label_dir): # 全局初始化:类申明时进行赋值 self.root_dir = root_dir self.label_dir = label_dir self.path = os.path.join(self.root_dir, self.label_dir) # 拼接两个路径 self.imge_path = os.listdir(self.path) # 返回这个文件目录下所有文件名--list数组 def __getitem__(self, index): # 获取每一个图片 img_name = self.imge_path[index] img_item_path = os.path.join(self.root_dir, self.label_dir, img_name) img = Image.open(img_item_path) label = self.label_dir return img, label def __len__(self): # 返回数据长度 return len(self.imge_path) root_dir = "dataset/train" ants_label_dir = "ants_image" bees_label_dir = "bees_image" ants_dataset = MyData(root_dir, ants_label_dir) bees_dataset = MyData(root_dir, bees_label_dir) train_dataset = ants_dataset + bees_dataset # 可以直接用+整合两个数据集 img, label = train_dataset[0] # 获取数据- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
Tensorboard使用
TensorBoard 是Google开发的一个机器学习可视化工具。其主要用于记录机器学习过程,例如:
- 记录损失变化、准确率变化等
- 记录图片变化、语音变化、文本变化等,例如在做GAN时,可以过一段时间记录一张生成的图片
- 绘制模型
主要是
add_scalar和add_image的使用:-
下载Tensorboard:
pip install tensorboard

-
运行检测一些有没有出错:
tensorboard --logdir=logs --port=6007
 如果报错例如:
如果报错例如:
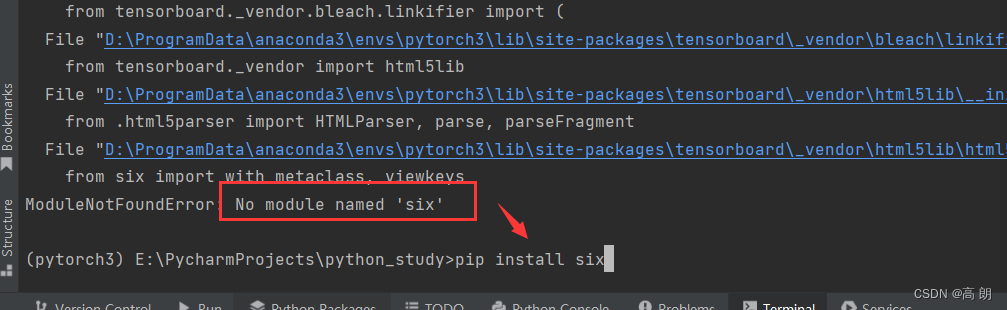
-
add_scalar方法:记录损失变化、准确率变化。 -
add_image方法:记录图形变化等。需要注意这个方法里面的参数是要求Tensor,ndarray等,并不是图片,需要进行转换。
 转换成ndarray:
转换成ndarray:
 但是这个numpy数据的通道数是在最后,(高,宽,通道),而我们这是方法默认是(通道,高,宽),所以需要修改一下,具体参考下面代码。
但是这个numpy数据的通道数是在最后,(高,宽,通道),而我们这是方法默认是(通道,高,宽),所以需要修改一下,具体参考下面代码。

-
最后记得关闭
close()
# tensorboard : loss函数的生成 from torch.utils.tensorboard import SummaryWriter import numpy as np from PIL import Image writer = SummaryWriter("logs") # 事件文件存储在logs下面 image_path = "dataset/train/bees_image/16838648_415acd9e3f.jpg" img_PIL = Image.open(image_path) img_array = np.array(img_PIL) writer.add_image("test", img_array, 1, dataformats='HWC') # 默认是通道在前,如果不是则需要dataformats进行设置,改变step进行图像变化 # x:scalar_value y: global_step tag: 标题 for i in range(100): writer.add_scalar("y=2*x", 2*i, i) writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Transforms
可以将transforms理解为一个工具箱:图像预处理方法
例如方法:ToTensor可以将PIL Image or numpy.ndarray这些类型转化为tensor对象,方便后期使用。import cv2 from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms # python的用法-》tensor数据类型 # 通过transforms.ToTensor去看两个问题 :pic (PIL Image or numpy.ndarray): Image to be converted to tensor. # 1、transforms该如何使用(python) # 2、为什么我们需要Tensor数据类型 # 创键一个PIL对象 img_path = "dataset/train/ants_image/0013035.jpg" img = Image.open(img_path) writer = SummaryWriter("logs") # 将PIL对象转换为tensor tensor_trans = transforms.ToTensor() tensor_img = tensor_trans(img) writer.add_image("Tensor_img", tensor_img) # 创建一个numpy.ndarray对象 img_path2 = "dataset/train/ants_image/36439863_0bec9f554f.jpg" cv_img = cv2.imread(img_path2) # 将numpy.ndarray对象转换为tensor tensor_img2 = tensor_trans(cv_img) writer.add_image("Tensor_img", tensor_img2, 2) writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
其他一些常用的:缩放,裁剪,归一等
from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms writer = SummaryWriter("logs") # ToTensor img = Image.open("dataset/train/ants_image/6743948_2b8c096dda.jpg") trans_totensor = transforms.ToTensor() img_tenser = trans_totensor(img) writer.add_image("ToTensor", img_tenser) # Normalize 标准化 trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 均值 标准差 图片是3个 img_norm = trans_norm(img_tenser) # output[channel] = (input[channel] - mean[channel]) / std[channel] # (input-0.5)/0.5 = 2*input - 1 # if input[0,1] => output[-1,1] writer.add_image("Normalize", img_norm) # Resize trans_resize = transforms.Resize((512, 512)) # 把size 修改为512x512 img_resize = trans_resize(img) # 直接传PIL对象,返回的还是修改了size的PIL对象 img_resize = trans_totensor(img_resize) # 将PIL对象转换为tensor writer.add_image("Resize", img_resize) # Compose - resize -2 第二种改变size的方式 trans_compose = transforms.Compose([transforms.Resize((32, 32)), # 缩放 transforms.ToTensor() # 图片转张量,同时归一化操作,0-255=》0-1 ]) img_resize_2 = trans_compose(img) writer.add_image("Resize2", img_resize_2, 1) # RandomCrop 随机裁剪 trans_compose_2 = transforms.Compose([transforms.RandomCrop(32, padding=4), # 随机裁剪 transforms.ToTensor() # 图片转张量,同时归一化操作,0-255=》0-1]) ]) for i in range(10): img_crop = trans_compose_2(img) writer.add_image("Random-crop", img_crop, i) writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
torchvision数据集使用
- CIFAR10数据集:相关介绍:https://www.cs.toronto.edu/~kriz/cifar.html
- 下载与测试:
 具体代码:
具体代码:
import torchvision # download 下载 train 训练 root 下载地址 train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True) test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True) print(test_set[0]) print(test_set.classes) img, target = test_set[0] print(img) print(target) print(test_set.classes[target]) img.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
上面生成的数据类型并不是tensor,可以使用transforms对其进行转换:

import torchvision dataset_transfroms = torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), # 转换为张量并归一 # 还可以添加其他操作,裁剪,缩放等 ]) train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transfroms, download=True) test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transfroms, download=True) print(test_set[0])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 结合
tensorboard使用:


import torchvision from torch.utils.tensorboard import SummaryWriter dataset_transfroms = torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), # 转换为张量并归一 # 还可以添加其他操作,裁剪,缩放等 ]) train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transfroms, download=True) test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transfroms, download=True) writer = SummaryWriter("logs") for i in range(20): img, target = test_set[i] writer.add_image("test_set", img, i) writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
DataLoader使用
Dataset:抽象类可以创建数据集,但是抽象类不能实例化,所以需要构建这个抽象类的子类来创建数据集,并且我们还可以定义自己的继承和重写方法。其中最重要的是len和getitem这两个函数,len能够给出数据集的大小,getitem用于查找数据和标签。(参考最前面dataset部分)DataLoader:处理模型输入数据的一个工具类,可以实现batch和shuffle的读取。- 具体代码操作:
import torchvision from torch.utils.data import DataLoader # 准备测试数据集 test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor()) # batch_size 每个数据块的大小 drop_last 舍弃最后不足数据块大小的数据 shuffle 乱序 num_workers 0默认主线程 test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False) # 测试数据集第一张大小 img, target = test_data[0] print(img.shape) print(target) # 每一个DataLoader是有batch_size个数据的 imgs和targets for data in test_loader: imgs, targets = data print(imgs.shape) print(targets)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
 主要是
主要是DataLoader()里面参数的理解:dataset: 传入的数据集batch_size: 每个batch有多少个样本shuffle: 在每个epoch开始的时候,对数据进行重新排序num_workers: 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)drop_last: 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被 扔掉了…如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。
nn.Module的使用
- 官方使用文档:https://pytorch.org/docs/stable/index.html

- 理解什么是卷积操作:没时间整理,可自行搜索或参考官方文档https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
输入图像(5x5) 与卷积核(3x3)的卷积操作代码:调整每次移动的步长
import torch import torch.nn.functional as F input = torch.tensor([[1, 2, 0, 3, 1], [0, 1, 2, 3, 1], [1, 2, 1, 0, 0], [5, 2, 3, 1, 1], [2, 1, 0, 1, 1]]) # 卷积核 kernel = torch.tensor([[1, 2, 1], [0, 1, 0], [2, 1, 0]]) # input tensor of shape (minibatch,in_channels,iH,iW)(minibatch,in_channels,iH,iW) # input shape是需要有4个参数,我们上面那个矩阵只有两个,需要reshape input = torch.reshape(input, (1, 1, 5, 5)) kernel = torch.reshape(kernel, (1, 1, 3, 3)) # 修改步长stride output = F.conv2d(input, kernel, stride=1) output2 = F.conv2d(input, kernel, stride=2) output3 = F.conv2d(input, kernel, stride=(1, 2)) print(output) print(output2) print(output3) # 修改填充padding output4 = F.conv2d(input, kernel, stride=1, padding=1) print(output4)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
输出:
tensor([[[[10, 12, 12], [18, 16, 16], [13, 9, 3]]]]) tensor([[[[10, 12], [13, 3]]]]) tensor([[[[10, 12], [18, 16], [13, 3]]]]) tensor([[[[ 1, 3, 4, 10, 8], [ 5, 10, 12, 12, 6], [ 7, 18, 16, 16, 8], [11, 13, 9, 3, 4], [14, 13, 9, 7, 4]]]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 一些函数中
Parameters参数的理解
stride (int or tuple, optional)–移动的步长,默认1,表示横向和纵向都是1,可以是元组分别控制横向和纵向移动的步长。padding—对输入进行填充,默认是0,也就是不填充,1表示填充一圈(上下左右各填充1行/列)且默认填充数值为0,
神经网络
- 卷积层
相关参数理解:
 搭建简单的卷积操作:
搭建简单的卷积操作:import torch import torchvision from torch import nn from torch.nn import Conv2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True) # 测试数据集 dataloader = DataLoader(dataset, batch_size=64) # 搭建神经网络 class NN(nn.Module): def __init__(self): super(NN, self).__init__() self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) def forward(self, x): x = self.conv1(x) return x # NN((conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1) ) writer = SummaryWriter("logs") nnn = NN() step = 0 for data in dataloader: imgs, target = data output = nnn(imgs) print(output.shape) # torch.Size([64, 6, 30, 30]) writer.add_images("input", imgs, step) # 修改通道数 6-》3 自己计算块 output = torch.reshape(output, (-1, 3, 30, 30)) writer.add_images("output", output, step) step = step + 1 writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39

- 最大池化:保留输入特征,减少数据量。https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html#torch.nn.MaxPool2d
卷积是做卷积后所有的和,最大池化是直接取最大值,当池化核遇到不足以全部覆盖时,ceil_mode为true时保留,false舍弃

import torch from torch import nn from torch.nn import MaxPool2d input = torch.tensor([[1, 2, 0, 3, 1], [0, 1, 2, 3, 1], [1, 2, 1, 0, 0], [5, 2, 3, 1, 1], [2, 1, 0, 1, 1]], dtype=torch.float32) # Input: (N,C,Hin,Win) 修改shape满足输入要求 input = torch.reshape(input, (-1, 1, 5, 5)) class NN(nn.Module): def __init__(self): super(NN, self).__init__() self.maxpool1 = MaxPool2d(3, ceil_mode=True) def forward(self, input): output = self.maxpool1(input) return output nnn = NN() output = nnn(input) print(output)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
控制台打印:
tensor([[[[2., 3.], [5., 1.]]]])- 1
- 2
具体数据集:
import torch import torchvision.datasets from torch import nn from torch.nn import MaxPool2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10("./data", train=False, download=True, transform=torchvision.transforms.ToTensor()) dataloader = DataLoader(dataset, batch_size=64) class NN(nn.Module): def __init__(self): super(NN, self).__init__() self.maxpool1 = MaxPool2d(3, ceil_mode=True) def forward(self, input): output = self.maxpool1(input) return output nnn = NN() writer = SummaryWriter("logs") step = 0 for data in dataloader: imgs, target = data writer.add_images("input", imgs, step) output = nnn(imgs) writer.add_images("output", output, step) step = step + 1 writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35

- 非线性激活
常见函数:

 ReLU函数使用:
ReLU函数使用:
import torch from torch import nn from torch.nn import ReLU input = torch.tensor([[1, -0.5], [-1, 3]]) # 指定batch_size input = torch.reshape(input, (-1, 1, 2, 2)) class NN(nn.Module): def __init__(self): super(NN, self).__init__() self.relu1 = ReLU(inplace=False) # inplace:是否把输出的结果替换掉输入input,默认False可不指定 def forward(self, input): output = self.relu1(input) return output nnn = NN() output = nnn(input) print(output)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
输出:
tensor([[[[1., 0.], [0., 3.]]]])- 1
- 2
Sigmoid的使用:
import torch import torchvision.datasets from torch import nn from torch.nn import ReLU, Sigmoid from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=64) class NN(nn.Module): def __init__(self): super(NN, self).__init__() self.relu1 = ReLU(inplace=False) # inplace:是否把输出的结果替换掉输入input,默认False可不指定 self.sigmoid1 = Sigmoid() def forward(self, input): output = self.sigmoid1(input) return output nnn = NN() writer = SummaryWriter("logs") step = 0 for data in dataloader: imgs, target = data writer.add_images("input", imgs, step) output = nnn(imgs) writer.add_images("output", output, step) step = step + 1 writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36

- 线性层

import torch import torchvision from torch import nn from torch.nn import Linear from torch.utils.data import DataLoader dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=64, drop_last=True) class NN(nn.Module): def __init__(self): super(NN, self).__init__() self.linear1 = Linear(196608, 10) # in_features输入的神经元个数 out_features输出神经元个数 bias 是否包含偏置 def forward(self, input): output = self.linear1(input) return output nnn = NN() for data in dataloader: imgs, target = data output = torch.reshape(imgs, (1, 1, 1, -1)) # 将形状展平,最后一个值语与linear的in_features对应 # 上面等价与 torch.flatten(imgs) print(output.shape) output = nnn(output) print(output.shape) Files already downloaded and verified torch.Size([1, 1, 1, 196608]) torch.Size([1, 1, 1, 10]) torch.Size([1, 1, 1, 196608]) torch.Size([1, 1, 1, 10]) torch.Size([1, 1, 1, 196608]) .....- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
其他部分可参考官方文档:
https://pytorch.org/docs/stable/nn.html#

- 小实战
实现CIFAR 10 model
 如何计算
如何计算stride和padding这两个参数,其他参数都是已知的输入输出的channel数,以及这个卷积大小都是已知的,通过下图公式可求出两个参数

stride=1和padding=2【padding = (kernel_size-1)/2 保持大小不变的话】import torch from torch import nn from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential from torch.utils.tensorboard import SummaryWriter class NN(nn.Module): def __init__(self): super(NN, self).__init__() # self.conv1 = Conv2d(3, 32, kernel_size=5, stride=1, padding=2) # self.maxpool1 = MaxPool2d(2) # self.conv2 = Conv2d(32, 32, kernel_size=5, stride=1, padding=2) # self.maxpool2 = MaxPool2d(2) # self.conv3 = Conv2d(32, 64, kernel_size=5, stride=1, padding=2) # self.maxpool3 = MaxPool2d(2) # self.flatten = Flatten() # 展平 64*4*4 = 1024个=》通过线性层转化为64=》再通过线性到输出的10 # self.linear1 = Linear(1024, 64) # self.linear2 = Linear(64, 10) self.model1 = Sequential( Conv2d(3, 32, kernel_size=5, stride=1, padding=2), MaxPool2d(2), Conv2d(32, 32, kernel_size=5, stride=1, padding=2), MaxPool2d(2), Conv2d(32, 64, kernel_size=5, stride=1, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self, x): # x = self.conv1(x) # x = self.maxpool1(x) # x = self.conv2(x) # x = self.maxpool2(x) # x = self.conv3(x) # x = self.maxpool3(x) # x = self.flatten(x) # x = self.linear1(x) # x = self.linear2(x) x = self.model1(x) return x nnn = NN() # 检查架构是否有错 input = torch.ones((64, 3, 32, 32)) output = nnn(input) print(output.shape) writer = SummaryWriter("logs") writer.add_graph(nnn, input) writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
tensorboard 显示的模型:

-
相关阅读:
vue3 的动态路由 以及history模式
【面试题】JS 常见的 6 种继承方式(常见)
Python爬虫实战,requests+xlwings模块,Python实现制作天气预报表!
程序员挖“洞”致富:发现一个漏洞,获赏 1272 万元
图像处理 QImage
HTTP与HTTPS的区别及HTTPS如何安全的传输数据
protocol 协议语言介绍
【Linux文件篇】软硬链接与动静态库链接的实用指南
C++ 智能指针常用总结
2023年25个Java8面试问题和答案
- 原文地址:https://blog.csdn.net/qq_43466788/article/details/132795931
