-
std : : vector
一.简介
std::vector的底层实现通常基于动态数组(dynamic array),它是一种连续分配的内存块,允许元素的快速随机访问。下面是std::vector的一些关键特点和底层实现细节:-
连续内存块:
std::vector内部使用一块连续的内存块来存储其元素,这使得元素的随机访问非常高效,因为可以通过指针算术运算来访问元素。 -
动态大小:
std::vector允许动态地增加或减少其大小。当元素数量达到内部分配的容量时,std::vector会重新分配更大的内存块,并将元素复制到新的内存块中。这种自动内存管理使得向量的大小可以根据需要进行调整,而不需要手动管理内存。 -
容量和大小:
std::vector有两个重要的属性,即容量(capacity)和大小(size)。- 容量是
std::vector当前内部分配的内存块的大小,通常大于或等于大小。当向量的大小超过容量时,会触发内存重新分配,容量会增加。 - 大小是
std::vector中实际存储的元素数量。
- 容量是
-
动态内存分配:
std::vector使用new和delete运算符(或malloc和free函数,取决于具体实现)来动态分配和释放内存。当需要重新分配内存时,它会为新的内存块分配内存,然后将元素从旧的内存块复制到新的内存块,最后释放旧内存。 -
异常安全:
std::vector的实现通常会提供异常安全性,这意味着如果在内存重新分配过程中发生异常,不会导致数据丢失或内存泄漏。这是通过使用临时副本和交换技术来实现的。 -
迭代器:
std::vector提供了迭代器(iterator)来遍历元素,迭代器通常是指针的封装,可以用于访问std::vector中的元素。 -
内存效率:由于
std::vector的元素存储在连续的内存块中,它在内存访问上具有很好的局部性,这有助于提高内存访问效率。
总之,
std::vector是一个非常灵活和高效的容器,它提供了动态数组的功能,使得元素的访问和管理变得非常方便。虽然std::vector的大小可以动态增长,但由于内存重新分配的开销,如果需要频繁插入或删除元素,可能需要考虑其他容器类型,如std::list或std::deque,它们可以更高效地支持插入和删除操作。扩展:
动态数组(Dynamic Array)是一种数据结构,它是一个连续分配的内存块,用于存储具有相同数据类型的元素。动态数组的大小可以动态增长或缩小,以适应元素的插入和删除操作。
以下是动态数组的主要特点和操作:
-
连续内存块:动态数组的元素存储在一块连续的内存块中,这意味着元素的地址在内存中是连续的,这有助于快速随机访问元素。通过索引访问元素的时间复杂度是 O(1)。
-
动态大小:动态数组允许在运行时动态增加或减少其大小。这意味着您可以向数组中添加元素或从数组中删除元素,而不需要预先知道数组的大小。这种动态大小的特性使得动态数组非常灵活。
-
内存分配:当向动态数组添加元素并且没有足够的内存容量时,动态数组会自动分配更大的内存块,将现有元素复制到新的内存块中,并释放旧的内存块。这个过程称为重新分配(re-allocation)。
-
时间复杂度:动态数组的插入和删除操作的时间复杂度取决于插入或删除的位置。在末尾进行插入和删除操作通常是最高效的,时间复杂度为 O(1),因为不需要移动元素。在数组中间进行插入或删除操作可能需要移动后续元素,时间复杂度为 O(n)。
-
容量和大小:动态数组具有容量(capacity)和大小(size)两个重要属性。
- 容量是动态数组内部分配的内存块的大小,通常大于或等于大小。
- 大小是动态数组中实际存储的元素数量。
-
迭代器:动态数组通常提供迭代器(iterator),可以用于遍历数组中的元素。
动态数组是一种非常常见和有用的数据结构,它具有灵活性和高效性的优点。
二.运用场景
std::vector是 C++ 标准库提供的一个动态数组容器,它在许多不同的场景中都非常有用。以下是一些常见的std::vector的运用场景:-
动态数组:
std::vector是一种动态数组,它可以根据需要自动增加或减少大小。这使得它成为存储不确定数量元素的首选选择,而不需要预先知道数组的大小。 -
数据收集:
std::vector适用于收集大量数据,例如从文件、网络或用户输入中读取的数据。您可以使用push_back()方法轻松添加新数据。 -
容器替代:
std::vector可以替代 C 数组,因为它提供了更多的功能和安全性。与 C 数组不同,std::vector知道自己的大小,而且可以动态调整大小。 -
迭代访问:如果需要通过索引或迭代器访问元素,并且需要快速随机访问能力,
std::vector是一个很好的选择。它的时间复杂度为 O(1)。 -
栈和队列:虽然
std::vector主要设计用于随机访问,但它也可以用作栈(先进后出)或队列(先进先出)。使用push_back()和pop_back()方法可以将其用作栈,而使用push_back()和erase()可以将其用作队列。 -
算法和数据处理:
std::vector与标准库中的各种算法结合使用,可以用于各种数据处理任务,例如排序、查找、筛选、转换等。 -
高性能计算:在需要高性能的数值计算领域,
std::vector通常用于存储大量数值数据,例如图形处理、科学计算、模拟等。 -
游戏开发:在游戏开发中,
std::vector常用于存储游戏对象、粒子、动画帧等。 -
数据传输:
std::vector可以用于数据传输,例如从文件读取数据到向量,然后将向量传递给其他处理模块。
需要注意的是,虽然
std::vector在许多情况下非常有用,但在某些特定情况下,其他容器类型(例如std::list、std::deque、std::set、std::map等)可能更适合特定的数据结构和操作。因此,在选择容器类型时,需要根据具体的需求和性能要求进行权衡和选择。三.写个比较器
(一)简单组合
方法一:直接静态函数
- #include
- #include
- #include
- using namespace std;
- static bool cmp(const pair<int, int>& a, const pair<int, int>& b) {
- if (a.first == b.first) return a.second < b.second;
- return a.first < b.first;
- }
- void display(vector
- int main() {
- vector
- display(ans);
- cout << endl;
- sort(ans.begin(), ans .end(), cmp);
- display(ans);
- return 0;
- }

方法二:写入结构体
- #include
- #include
- #include
- using namespace std;
- struct cmp {
- bool operator()(const pair<int,int>&a,const pair<int,int>&b) {
- if (a.first == b.first) return a.second < b.second;
- return a.first < b.first;
- }
- };
- void display(vector
- int main() {
- vector
- display(ans);
- sort(ans.begin(), ans .end(), cmp());
- cout << "----------" << endl;
- display(ans);
- return 0;
- }
在使用的时候,cmp() 表示实例化对象,要是不想实例化对象怎么办呢?这个时候我们可以把比较操作定义成静态成员函数,这样就可以通过这个结构体的名称来调用这个函数,而不需要实例化对象。
- #include
- #include
- #include
- using namespace std;
- struct numcmp {
- static bool cmp(const pair<int, int>& a, const pair<int, int>& b) {
- if (a.first == b.first) return a.second < b.second;
- return a.first < b.first;
- }
- };
- void display(vector
- int main() {
- vector
- display(ans);
- cout << endl;
- sort(ans.begin(), ans .end(), numcmp::cmp);
- display(ans);
- return 0;
- }

区别:
这两种写法在功能上是等效的,它们都可以用于自定义比较操作,以对pair或其他数据结构进行排序。然而,它们之间有一些细微的区别和优劣势:
-
可读性:使用函数指针或函数对象(结构体中的
operator())来定义比较操作,通常更易于理解和阅读。函数名可以明确指示比较的目的,而不需要查看结构体的成员。 -
灵活性:将比较操作封装在结构体中(函数对象方式)通常更灵活,因为你可以在结构体中存储额外的状态或配置,以影响比较的行为。这对于实现不同的排序方式很有用。
-
命名冲突:如果你有多个不同的比较操作,并且它们需要在不同的上下文中使用,将它们放入结构体中可以避免函数名冲突的问题,因为每个结构体都有自己的作用域。函数指针方式可能需要更多的命名空间管理。
-
语法:函数指针方式更紧凑,但在语法上可能略显繁琐。函数对象方式需要创建一个结构体并在排序函数中使用括号运算符来调用,这可能看起来有点冗长。
总的来说,选择哪种方式取决于你的需求和个人偏好。如果你只需要一个简单的比较操作,函数指针可能更合适。但如果你需要更复杂的比较逻辑,或者希望更好地组织和封装比较操作,那么使用函数对象(结构体中的
operator())可能更好。(二)对象
- 一样的思路
- #include
- #include
- #include
- using namespace std;
- class student {
- public:
- int age;
- string name;
- int height;
- int weight;
- student(int _age, string _name, int _height,int _weight) :age(_age), name(_name), height(_height),weight(_weight) {};
- };
- struct numcmp {
- static bool cmp(student*a,student*b) {
- if (a->height == b->height) {
- if (a->weight == b->weight) return a->age < b->age;
- return a->weight < b->weight;
- }
- return a->height < b->height;
- }
- };
- void display(vector
- for (auto it : ans) cout << it->age << " " << it->name << " " << it->height <<" "<
weight << "\t\t"; - }
- int main() {
- student *s1=new student(16, "张三", 175,160);
- student *s2=new student(19, "李四", 175,190);
- student *s3=new student(14, "王五", 160,150);
- vector
- ans.emplace_back(s1);
- ans.emplace_back(s2);
- ans.emplace_back(s3);
- display(ans);
- cout << endl;
- sort(ans.begin(), ans .end(), numcmp::cmp);
- display(ans);
- delete s1;//注意资源的释放
- delete s2;
- delete s3;
- return 0;
- }

注意:
- 当使用new创建对象时,直接对象指针装入vector(在堆上创建对象,需要delete释放)


- 当直接使用构造函数创建对象时,需要将对象的地址装入vector,vector中存储的是指向对象的指针。(在栈上创建对象)
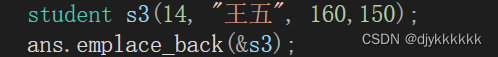
-
-
相关阅读:
LVS实战笔记-DR单网段
jssip在vue里调用出现‘get‘ on proxy: property ‘uri‘ is a read-only
2022牛客暑期多校第一场G、A、D
CMake构建学习笔记16-使用VS进行CMake项目的开发
DDD 学习笔记
汽车服务门店小程序模板制作指南
【Linux】题解:Linux环境基础开发工具——Git
【C++基于多设计模式下的同步&异步日志系统】
机器人控制算法简要概述
一种基于堆的链式优先队列实现(使用golang)
- 原文地址:https://blog.csdn.net/Ricardo_XIAOHAO/article/details/132796416
