-
第六章 图 四、图的广度优先遍历(BFS算法、广度优先生成树、广度优先生成森林)
一、实现步骤
广度优先遍历的实现步骤如下:
1.从图的某一个节点开始,将该节点标记为已经访问过的节点。
2.将该节点加入到队列中。
3.当队列非空时,执行以下操作:
a. 取出队列队首节点,并遍历该节点与之相邻的所有未被访问过的节点,并将这些节点标记为已经访问过的节点。
b. 将遍历到的所有未被访问过的节点加入到队列中。
4.重复步骤 3,直到队列为空为止。
在实现广度优先遍历时,需要使用一个数组来保存节点的访问状态,使用一个队列来保存需要遍历的节点。同时,也可以使用一个映射表来保存节点之间的关系,从而方便查找节点和它们之间的关系。
二、代码
- #include
- #include
- #define MAX_VERTEX_NUM 100
- // 邻接表的定义
- typedef struct _edge_node {
- int adjvex; // 邻接点编号
- struct _edge_node *next; // 下一个邻接点
- } EdgeNode;
- typedef struct _vertex_node {
- int data; // 节点数据
- EdgeNode *first_edge; // 第一个邻接点
- } VertexNode;
- VertexNode graph[MAX_VERTEX_NUM]; // 邻接表
- int visited[MAX_VERTEX_NUM]; // 访问标记数组
- int queue[MAX_VERTEX_NUM]; // 队列
- int front = 0, rear = 0; // 队列指针
- // 初始化邻接表
- void init_graph(int n) {
- for (int i = 0; i < n; i++) {
- graph[i].data = i;
- graph[i].first_edge = NULL;
- }
- }
- // 添加边
- void add_edge(int v1, int v2) {
- EdgeNode *e = (EdgeNode*)malloc(sizeof(EdgeNode));
- e->adjvex = v2;
- e->next = graph[v1].first_edge;
- graph[v1].first_edge = e;
- }
- // 广度优先遍历
- void bfs(int v, int n) {
- visited[v] = 1;
- queue[rear++] = v;
- while (front != rear) {
- int u = queue[front++];
- printf("%d ", u);
- EdgeNode *e = graph[u].first_edge;
- while (e) {
- if (!visited[e->adjvex]) {
- visited[e->adjvex] = 1;
- queue[rear++] = e->adjvex;
- }
- e = e->next;
- }
- }
- }
- int main() {
- int n, m;
- printf("请输入图的顶点数和边数:\n");
- scanf("%d%d", &n, &m);
- init_graph(n);
- printf("请输入边的信息:\n");
- for (int i = 0; i < m; i++) {
- int v1, v2;
- scanf("%d%d", &v1, &v2);
- add_edge(v1, v2);
- add_edge(v2, v1);
- }
- printf("请输入遍历的起始点:\n");
- int v;
- scanf("%d", &v);
- printf("广度优先遍历结果为:");
- bfs(v, n);
- printf("\n");
- return 0;
- }
空间复杂度:最坏情况,辅助队列的大小为V,O(V);
时间复杂度:若采用邻接矩阵存储O(
 );若采用邻接表存储O(
);若采用邻接表存储O( );
);三、手算遍历序列
假设有如下无向图:

我们可以从它的任意结点开始遍历
1、假如我们从结点7开始遍历
2、首先访问7,此时,遍历序列为7
3、访问7的邻接结点为3,4,6,8;此时,遍历序列为7,3,4,6,8
4、访问3的邻接结点,发现都被访问过了,跳过。
5、访问4的邻接结点,发现都被访问过了,跳过。
6、访问6的邻接结点2;此时,遍历序列为7,3,4,6,8,2
7、访问8的邻接结点,发现都被访问过了,跳过。
8、访问2的邻接结点1;此时,遍历序列为7,3,4,6,8,2,1
9、访问1的邻接结点5;此时,遍历序列为7,3,4,6,8,2,1,5
10、没有邻接结点了,遍历辅助队列,查看是否还有为遍历结点,发现还有结点9,10,11
11、重新调用BFS算法,从结点9开始遍历
依此类推,最终得到遍历序列7,3,4,6,8,2,1,5,9,10,11。
结论:对于无向图,调用BFS函数的次数=连通分量数
四、广度优先生成树,广度优先生成森林
一、无向图
书接上回:我们才遍历了一个图,所谓优先生成树,也就是每个结点最先被访问的路径,它们组成起来画出的图。
1、我们首先访问的是结点7,目前没有路径就先不动

2、通过结点7,我们访问了结点3,4,6,8;它们是第一次被访问,我们画出路径;

3、然后由结点6,访问了结点2

4、依此类推,得到最后的图

注意:我这个生成树只是其中的一种,根据存储结构的不同,所得到的树也不同。
邻接矩阵:生成树唯一。
邻接表:生成树不唯一。
由与我们还有一个连通向量,所以再加上下图就是广度优先生成森林

二、有向图
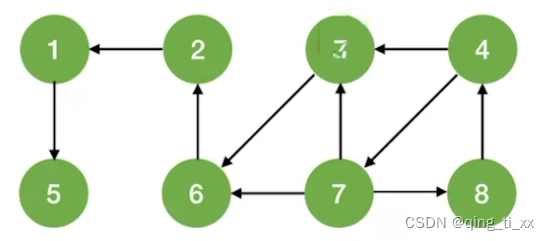
由于有向图只能单向通行所以要多次调用BFS算法。
-
相关阅读:
Shiro【散列算法、Shiro会话、退出登录 、权限表设计、注解配置鉴权 】(五)-全面详解(学习总结---从入门到深化)
Vue 3 setup 中通过 ref 获取子组件实例数据(TS版)
【深度学习】Chinese-CLIP 使用教程,图文检索,跨模态检索,零样本图片分类
【leetcode】【2022/9/3】646. 最长数对链
你在终端启动的进程,最后都是什么下场?(下)
Eclipse的下载与安装
jwbasta-vue 平台上线
闲置服务器废物利用_离线下载_私人影院_个人博客_私人云笔记_文件服务器
干洗店管理系统洗鞋店预约上门小程序洗护流程;
Splunk API : {“preview“:false,“lastrow“:true}
- 原文地址:https://blog.csdn.net/icbbm/article/details/132783586