-
云原生Kubernetes:二进制部署K8S多Master架构(三)
目录
一、理论
1.K8S多Master架构
(1) 场景
Kubernetes作为容器集群系统,通过健康检查+重启策略实现了Pod故障自我修复能力,通过调度算法实现将Pod分布式部署,并保持预期副本数,根据Node失效状态自动在其他Node拉起Pod,实现了应用层的高可用性。
针对Kubernetes集群,高可用性还应包含以下两个层面的考虑:Etcd数据库的高可用性和Kubernetes Master组件的高可用性。 而Etcd在单Master项目中已经采用3个节点组建集群实现高可用,所以需要对Master节点高可用进行说明和实施。
Master节点扮演着总控中心的角色,通过不断与工作节点上的Kubelet和kube-proxy进行通信来维护整个集群的健康工作状态。如果Master节点故障,将无法使用kubectl工具或者API做任何集群管理。
Master节点主要有三个服务kube-apiserver、kube-controller-manager和kube-scheduler,其中kube-controller-manager和kube-scheduler组件自身通过选择机制已经实现了高可用,所以Master高可用主要针对kube-apiserver组件,而该组件是以HTTP API提供服务,因此对它高可用与Web服务器类似,增加负载均衡器对其负载均衡即可,并且可水平扩容。
(2)架构

(3)Nginx+Keepalived高可用负载均衡器
① 架构

② 场景
1)Nginx是一个主流Web服务和反向代理服务器,这里用四层实现对apiserver实现负载均衡。
Keepalived是一个主流高可用软件,基于VIP绑定实现服务器双机热备,在上述拓扑中, 2)Keepalived主要根据Nginx运行状态判断是否需要故障转移(漂移VIP),例如当Nginx主节点挂掉,VIP会自动绑定在Nginx备节点,从而保证VIP一直可用,实现Nginx高可用。
3)如果项目部署在公有云上,一般都不支持keepalived,可以直接用它们的负载均衡器产品,直接负载均衡多台Master kube-apiserver,架构与上面一样。
在两台Master节点操作。
2.配置master02
(1)环境
- 关闭防火墙
- systemctl stop firewalld
- systemctl disable firewalld
- 关闭selinux
- setenforce 0 #临时关闭
- sed -i 's/enforcing/disabled/' /etc/selinux/config #永久关闭
- 关闭swap
- swapoff -a
- sed -ri 's/.*swap.*/#&/' /etc/fstab
- 设置主机名
- hostnamectl set-hostname master02
- 在各节点添加hosts
- cat >> /etc/hosts << EOF
- 192.168.204.176 master02
- 192.168.204.171 master01
- 192.168.204.173 node01
- 192.168.204.175 node02
- EOF
- 将桥接的IPv4流量传递到iptables的链
- cat > /etc/sysctl.d/k8s.conf << EOF
- net.bridge.bridge-nf-call-ip6tables = 1
- net.bridge.bridge-nf-call-iptables =1
- EOF
- sysctl --system #重新载入一下
- 时间同步
- yum install ntpdate -y
- ntpdate time.windows.com
3.master02 节点部署
(1)从 master01 节点上拷贝证书文件、各master组件的配置文件和服务管理文件到 master02 节点
- scp -r /opt/etcd/ root@192.168.204.176:/opt/
- scp -r /opt/kubernetes/ root@192.168.204.176:/opt
- scp /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service root@192.168.204.176:/usr/lib/systemd/system/
(2)修改配置文件kube-apiserver中的IP
- vim /opt/kubernetes/cfg/kube-apiserver
- KUBE_APISERVER_OPTS="--logtostderr=true \
- --v=4 \
- --etcd-servers=https://192.168.204.171:2379,https://192.168.204.173:2379,https://192.168.204.175:2379 \
- --bind-address=192.168.204.176 \ #修改
- --secure-port=6443 \
- --advertise-address=192.168.204.176 \ #修改
- ......
(3)在 master02 节点上启动各服务并设置开机自启
- systemctl start kube-apiserver.service
- systemctl enable kube-apiserver.service
- systemctl start kube-controller-manager.service
- systemctl enable kube-controller-manager.service
- systemctl start kube-scheduler.service
- systemctl enable kube-scheduler.service
(4)查看node节点状态
- ln -s /opt/kubernetes/bin/* /usr/local/bin/
- kubectl get nodes
- kubectl get nodes -o wide
4.负载均衡部署
配置load balancer集群双机热备负载均衡(nginx实现负载均衡,keepalived实现双机热备)
(1)在lb01、lb02节点上操作
配置nginx的官方在线yum源,配置本地nginx的yum源
- cat > /etc/yum.repos.d/nginx.repo << 'EOF'
- [nginx]
- name=nginx repo
- baseurl=http://nginx.org/packages/centos/7/$basearch/
- gpgcheck=0
- EOF
yum install nginx -y修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台master的节点ip和6443端口
- vim /etc/nginx/nginx.conf
- events {
- worker_connections 1024;
- }
- #添加
- stream {
- log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
- access_log /var/log/nginx/k8s-access.log main;
- upstream k8s-apiserver {
- server 192.168.111.171:6443;
- server 192.168.111.176:6443;
- }
- server {
- listen 6443;
- proxy_pass k8s-apiserver;
- }
- }
- http {
- ......
检查配置文件语法
nginx -t启动nginx服务,查看已监听6443端口
- systemctl start nginx
- systemctl enable nginx
- netstat -natp | grep nginx
部署keepalived服务
yum install keepalived -y修改keepalived配置文件
- vim /etc/keepalived/keepalived.conf
- ! Configuration File for keepalived
- global_defs {
- # 接收邮件地址
- notification_email {
- acassen@firewall.loc
- failover@firewall.loc
- sysadmin@firewall.loc
- }
- # 邮件发送地址
- notification_email_from Alexandre.Cassen@firewall.loc
- smtp_server 127.0.0.1
- smtp_connect_timeout 30
- router_id NGINX_MASTER #lb01节点的为 NGINX_MASTER,lb02节点的为 NGINX_BACKUP
- }
- #添加一个周期性执行的脚本
- vrrp_script check_nginx {
- script "/etc/nginx/check_nginx.sh" #指定检查nginx存活的脚本路径
- }
- vrrp_instance VI_1 {
- state MASTER #lb01节点的为 MASTER,lb02节点的为 BACKUP
- interface ens33 #指定网卡名称 ens33
- virtual_router_id 51 #指定vrid,两个节点要一致
- priority 100 #lb01节点的为 100,lb02节点的为 90
- advert_int 1
- authentication {
- auth_type PASS
- auth_pass 1111
- }
- virtual_ipaddress {
- 192.168.204.100/24 #指定 VIP
- }
- track_script {
- check_nginx #指定vrrp_script配置的脚本
- }
- }
创建nginx状态检查脚本
- vim /etc/nginx/check_nginx.sh
- #!/bin/bash
- #egrep -cv "grep|$$" 用于过滤掉包含grep 或者 $$ 表示的当前Shell进程ID
- count=$(ps -ef | grep nginx | egrep -cv "grep|$$")
- if [ "$count" -eq 0 ];then
- systemctl stop keepalived
- fi
- chmod +x /etc/nginx/check_nginx.sh
启动keepalived服务(一定要先启动了nginx服务,再启动keepalived服务)
- systemctl start keepalived
- systemctl enable keepalived
- ip a #查看VIP是否生成
修改node节点上的bootstrap.kubeconfig,kubelet.kubeconfig配置文件为VIP
- cd /opt/kubernetes/cfg/
- vim bootstrap.kubeconfig
- server: https://192.168.204.100:6443
- vim kubelet.kubeconfig
- server: https://192.168.204.100:6443
- vim kube-proxy.kubeconfig
- server: https://192.168.204.100:6443
node节点重启kubelet和kube-proxy服务
- systemctl restart kubelet.service
- systemctl restart kube-proxy.service
在 lb01 上查看 nginx 和 node 、 master 节点的连接状态
netstat -natp | grep nginx(2)在 master01 节点上操作
测试创建pod
kubectl run nginx --image=nginx查看Pod的状态信息
kubectl get pods在对应网段的node节点上操作,可以直接使用浏览器或者curl命令访问
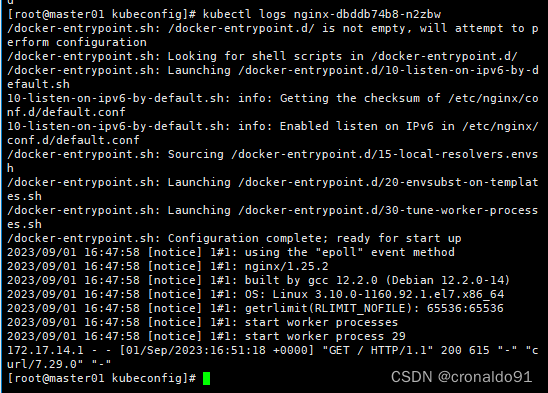
curl 172.17.14.2这时在master01节点上查看nginx日志,发现没有权限查看
kubectl logs nginx-dbddb74b8-n2zbw在master01节点上,将cluster-admin角色授予用户system:anonymous
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous这时在master01节点上查看nginx日志
kubectl logs nginx-dbddb74b8-n2zbw二、实验
由实验:二进制部署K8S单Master架构(二)继续进行
1.环境
表1 K8S环境
主机 IP 软件 硬件 k8s集群master01 192.168.204.171 kube-apiserver kube-controller-manager kube-scheduler etcd 4核4G k8s集群node1 192.168.204.173 kubelet kube-proxy docker flannel 4核4G k8s集群node2 192.168.204.175 kubelet kube-proxy docker flannel 4核4G k8s集群master02 192.168.204.176 kube-apiserver kube-controller-manager kube-scheduler etcd 4核4G 负载均衡器1(lb01) 192.168.204.177 nginx,keepalived 2核2G 负载均衡器2(lb02) 192.168.204.178 nginx,keepalived 2核2G 2.配置master02
(1)环境
关闭防火墙

关闭selinux

关闭swap

设置主机名

在各节点添加hosts

将桥接的IPv4流量传递到iptables的链

重新载入一下
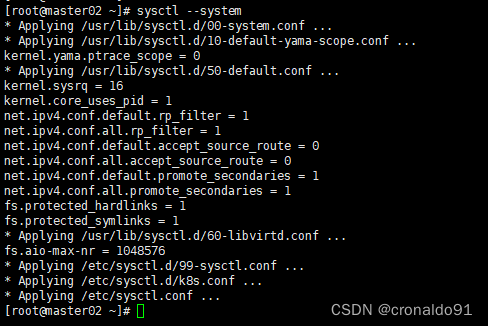
时间同步


3.master02 节点部署
(1)从 master01 节点上拷贝证书文件、各master组件的配置文件和服务管理文件到 master02 节点

(2)修改配置文件kube-apiserver中的IP


(3)在 master02 节点上启动各服务并设置开机自启

(4)查看node节点状态

4.负载均衡部署
配置load balancer集群双机热备负载均衡(nginx实现负载均衡,keepalived实现双机热备)
(1)在lb01、lb02节点上操作
配置nginx的官方在线yum源,配置本地nginx的yum源


修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台master的节点ip和6443端口


检查配置文件语法

启动nginx服务,查看已监听6443端口

部署keepalived服务

修改keepalived配置文件


创建nginx状态检查脚本


启动keepalived服务(一定要先启动了nginx服务,再启动keepalived服务)
vip已在lb01生成
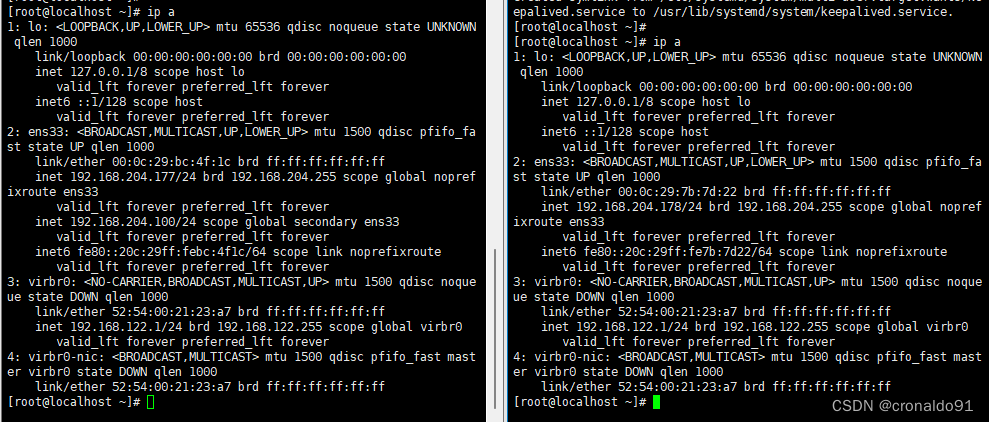
修改node节点上的bootstrap.kubeconfig,kubelet.kubeconfig配置文件为VIP
node1:




node2:






重启kubelet和kube-proxy服务

在 lb01 上查看 nginx 和 node 、 master 节点的连接状态

(2)在 master01 节点上操作
测试创建pod

查看Pod的状态信息
正在创建中

创建完成,运行中

READY为1/1,表示这个Pod中有1个容器
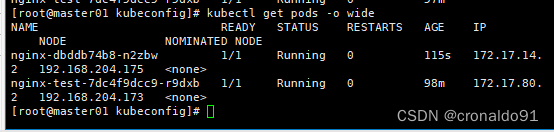
在对应网段的node节点上操作,可以直接使用浏览器或者curl命令访问

这时在master01节点上查看nginx日志,发现没有权限查看

在master01节点上,将cluster-admin角色授予用户system:anonymous

这时在master01节点上查看nginx日志
三、总结
kube-controller-manager和kube-scheduler组件自身通过选择机制已经实现了高可用,所以Master高可用主要针对kube-apiserver组件。
nginx实现负载均衡,keepalived实现双机热备。
启动keepalived服务(一定要先启动了nginx服务,再启动keepalived服务)。
-
相关阅读:
新老电脑的文件/数据同步记录
java计算机毕业设计快滴预约平台源码+系统+mysql数据库+lw文档+部署
es的检索-DSL语法和Java-RestClient实现
教你实现物联网HMI/网关的趋势功能
Python日期和时间库datetime
问题 A: 二叉排序树 - 文本输出
QFramework引入Command
IP协议从0到1
功能安全 ISO26262
数据采集中的基本参数
- 原文地址:https://blog.csdn.net/cronaldo91/article/details/132632271
