-
Linux部署kettle并设置定时任务
一.安装Kettle
linux中使用kettle时首先需要jdk环境,这里就不概述linux中jdk的安装与配置了。
1.首先将kettle压缩包放入linux并解压
unzip data-integration.zip
kettle安装路径为:/root/Kettle9.3/data-integration
设置权限
chmod -R 755 /root/Kettle9.3/data-integration2.执行命令查看kitchen版本
linux中执行作业时使用kitchen;执行转换使用pan
出现以下界面则表示安装成功
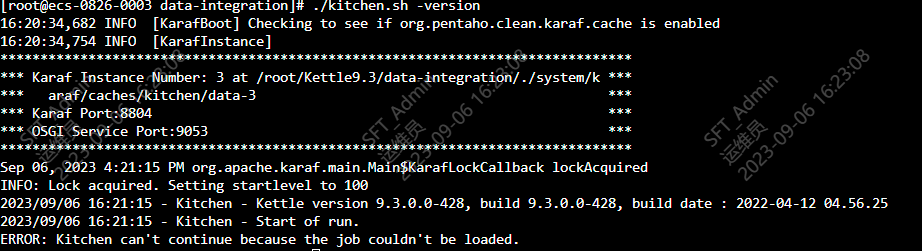
3.配置资源库
kettle在linux中会存在一个隐藏文件夹其中存放了一些配置文件。
cd ~查看隐藏文件,会看到一个.kettle文件夹
ls -a

其中repositories.xml即为资源库配置文件。当你linux文件夹中不存在以上图片中的文件时。
便需要在windows中的C:\Users\电脑用户名称\.kettle 中将文件复制到linux即可。
repositories.xml配置如下所示:

- "1.0" encoding="UTF-8"?>
- <repositories>
- <repository>
- <id>KettleFileRepositoryid>
- <name>YNSOURCEname>
- <description>File repositorydescription>
- <is_default>trueis_default>
- <base_directory>/root/Kettle9.3/kettleDatabase_directory>
- <read_only>Nread_only>
- <hides_hidden_files>Nhides_hidden_files>
- repository>
- repositories>
base_directory:便是本地资源库地址(需要将作业和转换都放置到该目录下)
name:资源库名称(后续在执行作业时需要用到)
二.设置环境变量
设置环境变量: 在/etc/profile文件中添加以下配置:
/root/Kettle9.3/data-integration 为linux中kettle的安装路径,第一步中已表明
- export KETTLE=/root/Kettle9.3/data-integration
- export PATH=${KETTLE}:$PATH
然后查看设置的环境变量
echo $PATH保存设置
source /etc/profile三.执行作业
需要先创建一个作业并将其放入资源库地址中。(作业中包含的转换等同时放入)
如果存放数据库文件设置的话也需要放入。
执行语句:
./kitchen.sh -rep YNSOURCE -user admin -pass admin -file=/root/Kettle9.3/kettleData/ceshi.kjb
YNSOURCE:资源库名称
-user admin -pass admin:资源库的账号密码,未设置便使用该语句即可(默认账号密码)
/root/Kettle9.3/kettleData/ceshi.kjb:作业地址
回车执行即可。
当出现ERROR: Kitchen can't continue because the job couldn't be loaded.报错时不用理会等待继续执行即可。

四.设置定时任务
采用了crontab来进行定时任务的设置。
因此需要编写一个执行kettle作业的脚本
1.创建脚本
vim run_kettle_job.sh2.编写脚本内容
- #!/bin/bash
- cd /root/Kettle9.3/data-integration
- ./kitchen.sh -rep YNSOURCE -user admin -pass admin -file=/root/Kettle9.3/kettleData/ceshi.kjb
3.设置权限
chmod -R 755 run_kettle_job.sh4.打开crontab
crontab -e5.设置定时任务
0 * * * * bash /root/Kettle9.3/run_kettle_job.sh
6.查看定时任务
crontab -l五.常见问题
1.路径问题
本人kettle任务有多个作业,多个作业里又嵌套着作业以及转换,因此在调用这多个作业的时候为了统一管理就将其包在一个作业中。但是将kettle文件从windows放到linux部署运行时,出现了以下路径问题:
Unable to load the job: please specify the name:and repository directory OR该问题在网络上并没有找到解决方法,但是通过不断的尝试也顺利解决了该问题,因此进行记录。(感觉这是一个kettle的小bug)
(1) 以下图片是报错时,主kettle任务入口的作业。会发现嵌套的子作业使用的是相对路径(正常情况下使用资源库后,kettle会默认在相对路径前拼接资源库地址,从而访问作业或者转换)。
但是目前这样是存在问题的。不过通过尝试后发现kettle在linux中部署时,对于运行作业中的嵌套作业路径并没有做默认处理。也就是说它找job_system是认为路径为/SYSTEM/job_system。当我将其手动修改为linux中的绝对路径时,job_system作业便可以成功运行了(内部嵌套的作业以及转换路径不用修改)。所以说ketle的一个小bug就是主作业中嵌套的子作业地址没有被成功识别。
针对该问题,我在job_indicator外又包了一层作业,从而减少对job_indicator中各子作业路径的修改。然后在脚本中将job_indicator作业修改为job_all后即可。
-
相关阅读:
程序的编译汇编和链接
【数据挖掘】Pandas介绍
若依VUE 从一个页面跳转另一个页面并携带参数
Spring MVC具有哪些优点及缺点呢?
SSM框架的师范学院教务信息查询系统的设计与实现源码
LeetCode每日一练 —— 环形链表问题(面试四连问)
openGauss_单机部署
思科模拟器--08.三层交换机配置实验(两个交换机)--24.5.22
Elasticsearch实用教程---从门->进阶->精通
R语言survival包clogit函数构建条件logistic回归模型、summary函数查看模型汇总统计信息、通过似然比检验分析结果判断模型有无统计学意义
- 原文地址:https://blog.csdn.net/weixin_51296247/article/details/132719878