-
深度学习推荐系统(六)DeepFM模型及其在Criteo数据集上的应用
深度学习推荐系统(六)DeepFM模型及其在Criteo数据集上的应用
在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日, 依然是主流。 推荐模型主要有下面两个进展:
-
与传统的机器学习模型相比, 深度学习模型的表达能力更强, 能够挖掘更多数据中隐藏的模式
-
深度学习模型结构非常灵活, 能够根据业务场景和数据特点, 灵活调整模型结构, 使模型与应用场景完美契合
深度学习推荐模型,以多层感知机(MLP)为核心, 通过改变神经网络结构进行演化。

在进入深度学习时代后,FM的演化过程并没有停止,
FNN、DeepFM 及 NFM模型,使用不同的方式应用或改进了FM模型,并融合进深度学习模型中,持续发挥着其在特征组合上的优势。1 FNN模型原理
用一句话来说明FNN的主要思想:
用FM的隐向量完成Embedding层初始化。1.1 FNN的网络架构及原理
-
神经网络的参数往往采用随机初始化这种不包含任何先验信息的初始化方法。由于 Embedding 层的输入极端稀疏化,导致 Embedding 层的收敛速度非常缓慢,再加上Embedding层的参数数量往往占整个神经网络参数数量的大半以上,因此模型的收敛速度往往受限于Embedding 层。
-
FNN模型架构类似于Deep Crossing模型的经典深度神经网络
- 从稀疏输入向量到稠密向量的转换依然是embedding结构,但是针对Embedding层收敛速度慢的问题,FNN模型用FM模型替换了下面的Embedding层
- 并且在模型的正式训练之前,
先提前训练好FM,然后用FM训练好的特征隐向量对正式训练的模型进行Embedding层的初始化操作。这样在正式训练的时候,就加速了模型的收敛过程。 - 也就是说,神经网络训练的起点更接近目标最优点,自然加速了整个神经网络的收敛过程。
-
所以FNN采用了两阶段训练方式,这种两阶段方式的应用,是为了将FM作为先验知识加入到模型中,防止因为数据稀疏带来的歧义造成模型参数偏差。这样既可以加速模型收敛,也可以充分利用FM的特征表达。
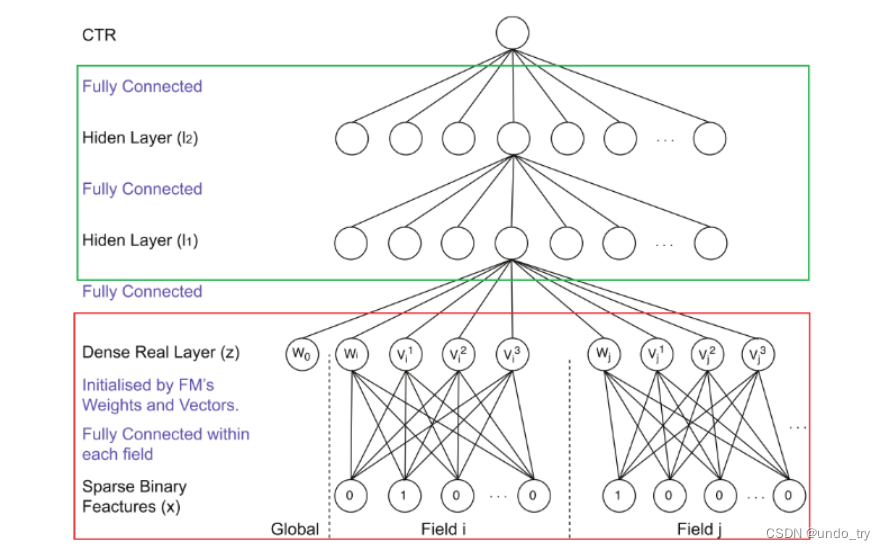
1.2 利用FM初始化Embedding层的过程
-
虽然在下图中,把FM中的参数指向了 Embedding层各神经元,但其具体意义是初始化Embedding神经元与输入神经元之间的连接权重。

-
在训练 FM的过程中,并没有对特征域进行区分,
但在 FNN模型中,特征被分成了不同特征域,因此每个特征域具有对应的 Embedding层,并且每个特征域Embedding的维度都应与FM隐向量维度保持一致。

1.3 FNN模型的缺点
-
FNN模型能力受限于FM表征能力的上限
-
FNN模型只关注于高阶组合特征的交叉
-
两阶段训练方式也存在问题
-
FM中特征组合,使用的隐向量的点积运算。将FM得到的隐向量移植到DNN中作为DNN的输入, 全连接层这时候会将输入向量的所有元素加权求和,且不会对Field进行区分。 这个其实又回到了之前说Deep Crossing时的问题,全连接隐层把所有特征进行了统一的交叉学习, 这样可能会使的即使没有关系的特征在这种情况下也会发生点关系。
-
这种两阶段的训练方式给神经网络的调参带来了难题, 因为FNN的底层参数是预训练得到的, 所以在反向传播更新参数的时候,不能学习率过大,否则会将FM得到的信息给抹去。所以底层的学习率要小一些。
-
2 DeepFM模型原理
-
简单的线性模型不能充分挖掘数据中的隐含信息,且忽略了特征间的交互,如果想交互,需要复杂的特征工程。
-
FM模型考虑了特征的二阶交叉,但是这种交叉仅停留在了二阶层次。
-
DNN,适合天然的高阶交叉信息的学习,但是低阶的交叉会忽略掉。
-
Wide&Deep模型把简单的LR模型和DNN模型进行了组合, 使得模型既能够学习高阶组合特征,又能够学习低阶的特征模式。但是W&D的wide部分是用了LR模型, 这一块依然是需要一些经验性的特征工程的,且Wide部分和Deep部分需要两种不同的输入模式, 这个在具体实际应用中需要很强的业务经验。
-
FNN把FM的训练结果作为初始化权重,并没有对神经网络的结构进行调整。
-
2017年由哈尔滨工业大学和华为联合提出的DeepFM模型,则将FM的模型结构与Wide&Deep 模型进行了整合,
用FM替代Wide部分。模型也是两部分组成, 左边的FM+右边的DNN,FM能够考虑低阶交叉, 而DNN能够学习高阶交叉,另外FM作为wide部分也具备了自动特征组合能力,所以说DeepFM模型是一个经典的模型。
2.1 DeepFM模型的网络架构及原理
-
DeepFM 对 Wide&Deep 模型的改进之处在于,它用FM替换了原来的 Wide 部分,
加强了浅层网络部分特征组合的能力。 -
如图所示,左边的FM部分与右边的深度神经网络部分
共享相同的 Embedding 层。左侧的FM部分对不同的特征域的Embedding进行了两两交叉,也就是将Embedding向量当作原 FM 中的特征隐向量。- FM模型负责特征之间的低阶交互过程,FM的输出是Addition单元和Inner Product units的加和, Addition单元反映1阶特征各自的影响, 而Inner product代表2阶特征交互的影响。
- 与FNN不同, FM这里的隐向量参数是直接和神经网络的参数一样,都是当做学习参数一块学习的,这样就省去了FM的预训练过程,而是以端到端方式训练整个网络。
- 与Wide&Deep不同的是,DeepFM中的Wide部分与Deep部分共享了输入特征,即Embedding向量。
-
最后将 FM 的输出与 Deep 部分的输出一同输入最后的输出层,参与最后的目标拟合。

2.2 DeepFM模型的优点
-
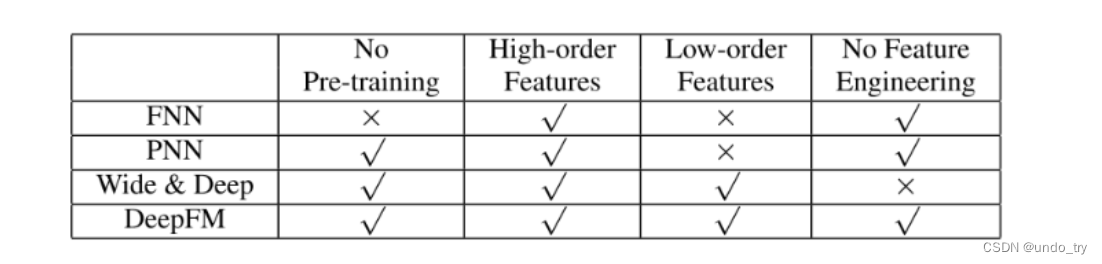
FNN模型: 预训练的方式增加了开销,模型能力受限于FM表征能力的上限,且只考虑了高阶交互
-
PNN模型:IPNN的内积计算非常复杂, OPNN的外积近似计算损失了很多信息,结果不稳定, 且同样忽视了低阶交互
-
W&D模型:虽然是考虑到了低阶和高阶交互,兼顾了模型的泛化和记忆,但是Wide部分输入需要专业的特征工程经验
-
DeepFM同时考虑了上面的这些问题, 用FM换掉了W&D的LR,并Wide部分和Deep部分通过低阶和高阶特征交互来影响特征表示,从而更精确地对特征表示进行建模的策略共享了特征Embedding。
2.3 DeepFM模型的代码复现
2.3.1 FM的公式推导
其实,DeepFM代码复现,主要在于FM公式在pytorch中的实现
化简后FM的公式如下:
我们定义三个矩阵,
一个是全局偏置,w0的shape为(1,)
一个是一阶权重矩阵,w1的shape为(总特征数, 1)
一个是二阶交叉矩阵,w2的shape为(总特征数, embedding的维度)
那么,对于1阶交叉,代码如下
# 一阶交叉 # inputs的shape为(批次大小,总特征数) first_order = w0 + torch.mm(inputs, w1) # 输出的shape为 (批次大小, 1)- 1
- 2
- 3
对于2阶交叉,代码如下
# 二阶交叉 这个用最终的化简公式进行计算 # inputs为公式中X_i,w2为公式中v_if second_order = 1/2 * torch.sum( torch.pow(torch.mm(inputs, w2), 2) - torch.mm(torch.pow(inputs,2), torch.pow(w2, 2)), dim = 1, keepdim = True # 求和保持纬度不变 )- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.3.2 DeepFM代码复现
import torch.nn as nn import torch.nn.functional as F import torch class FM(nn.Module): """FM part""" def __init__(self, latent_dim, fea_num): """ latent_dim: 各个离散特征隐向量的维度 fea_num: 这个最后离散特征embedding之后的拼接和dense拼接的总特征个数 """ super(FM, self).__init__() self.latent_dim = latent_dim # 定义三个矩阵, 一个是全局偏置,一个是一阶权重矩阵, 一个是二阶交叉矩阵 # 注意这里的参数由于是可学习参数,需要用nn.Parameter进行定义 self.w0 = nn.Parameter(torch.zeros([1, ])) self.w1 = nn.Parameter(torch.rand([fea_num, 1])) self.w2 = nn.Parameter(torch.rand([fea_num, latent_dim])) def forward(self, inputs): # 一阶交叉 first_order = self.w0 + torch.mm(inputs, self.w1) # (samples_num, 1) # 二阶交叉 这个用FM的最终化简公式 second_order = 1 / 2 * torch.sum( torch.pow(torch.mm(inputs, self.w2), 2) - torch.mm(torch.pow(inputs, 2), torch.pow(self.w2, 2)), dim=1, keepdim=True ) # (samples_num, 1) return first_order + second_order class Dnn(nn.Module): """ Dnn part """ def __init__(self, hidden_units, dropout=0.): """ hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度 dropout: 失活率 """ super(Dnn, self).__init__() self.dnn_network = nn.ModuleList( [nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))]) self.dropout = nn.Dropout(p=dropout) def forward(self, x): for linear in self.dnn_network: x = linear(x) x = F.relu(x) x = self.dropout(x) return x ''' WideDeep模型: 主要包括Wide部分和Deep部分 ''' class DeepFM(nn.Module): def __init__(self, feature_info, hidden_units, embed_dim=8): """ DeepCrossing: feature_info: 特征信息(数值特征, 类别特征, 类别特征embedding映射) hidden_units: 列表, 隐藏单元 dropout: Dropout层的失活比例 embed_dim: embedding维度 """ super(DeepFM, self).__init__() self.dense_features, self.sparse_features, self.sparse_features_map = feature_info # embedding层, 这里需要一个列表的形式, 因为每个类别特征都需要embedding self.embed_layers = nn.ModuleDict( { 'embed_' + str(key): nn.Embedding(num_embeddings=val, embedding_dim=embed_dim) for key, val in self.sparse_features_map.items() } ) # 统计embedding_dim的总维度 # 一个离散型(类别型)变量 通过embedding层变为10纬 embed_dim_sum = sum([embed_dim] * len(self.sparse_features)) # 总维度 = 数值型特征的纬度 + 离散型变量经过embedding后的纬度 dim_sum = len(self.dense_features) + embed_dim_sum hidden_units.insert(0, dim_sum) # dnn网络 self.dnn_network = Dnn(hidden_units) # dnn的线性层 self.dnn_final_linear = nn.Linear(hidden_units[-1], 1) # fm self.fm = FM(embed_dim, dim_sum) def forward(self, x): # 1、先把输入向量x分成两部分处理、因为数值型和类别型的处理方式不一样 dense_input, sparse_inputs = x[:, :len(self.dense_features)], x[:, len(self.dense_features):] # 2、转换为long形 sparse_inputs = sparse_inputs.long() # 2、不同的类别特征分别embedding sparse_embeds = [ self.embed_layers['embed_' + key](sparse_inputs[:, i]) for key, i in zip(self.sparse_features_map.keys(), range(sparse_inputs.shape[1])) ] # 3、把类别型特征进行拼接,即emdedding后,由3行转换为1行 sparse_embeds = torch.cat(sparse_embeds, axis=-1) # 4、数值型和类别型特征进行拼接 x = torch.cat([sparse_embeds, dense_input], axis=-1) # FM部分 wide_out = self.fm(x) # Deep部分,使用全部特征 deep_out = self.dnn_final_linear(self.dnn_network(x)) # out 将FM部分的输出和Deep部分的输出进行合并 outputs = torch.sigmoid(torch.add(wide_out, deep_out)) return outputs if __name__ == '__main__': x = torch.rand(size=(1, 5), dtype=torch.float32) feature_info = [ ['I1', 'I2'], # 连续性特征 ['C1', 'C2', 'C3'], # 离散型特征 { 'C1': 20, 'C2': 20, 'C3': 20 } ] # 建立模型 hidden_units = [128, 64, 32] net = DeepFM(feature_info, hidden_units) print(net) print(net(x))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
DeepFM( (embed_layers): ModuleDict( (embed_C1): Embedding(20, 8) (embed_C2): Embedding(20, 8) (embed_C3): Embedding(20, 8) ) (dnn_network): Dnn( (dnn_network): ModuleList( (0): Linear(in_features=26, out_features=128, bias=True) (1): Linear(in_features=128, out_features=64, bias=True) (2): Linear(in_features=64, out_features=32, bias=True) ) (dropout): Dropout(p=0.0, inplace=False) ) (dnn_final_linear): Linear(in_features=32, out_features=1, bias=True) (fm): FM() ) tensor([[1.]], grad_fn=<SigmoidBackward0>)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3 DeepFM模型在Criteo数据集的应用
数据的预处理可以参考
深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用_undo_try的博客-CSDN博客
3.1 准备训练数据
import pandas as pd import torch from torch.utils.data import TensorDataset, Dataset, DataLoader import torch.nn as nn from sklearn.metrics import auc, roc_auc_score, roc_curve import warnings warnings.filterwarnings('ignore')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
# 封装为函数 def prepared_data(file_path): # 读入训练集,验证集和测试集 train_set = pd.read_csv(file_path + 'train_set.csv') val_set = pd.read_csv(file_path + 'val_set.csv') test_set = pd.read_csv(file_path + 'test.csv') # 这里需要把特征分成数值型和离散型 # 因为后面的模型里面离散型的特征需要embedding, 而数值型的特征直接进入了stacking层, 处理方式会不一样 data_df = pd.concat((train_set, val_set, test_set)) # 数值型特征直接放入stacking层 dense_features = ['I' + str(i) for i in range(1, 14)] # 离散型特征需要需要进行embedding处理 sparse_features = ['C' + str(i) for i in range(1, 27)] # 定义一个稀疏特征的embedding映射, 字典{key: value}, # key表示每个稀疏特征, value表示数据集data_df对应列的不同取值个数, 作为embedding输入维度 sparse_feas_map = {} for key in sparse_features: sparse_feas_map[key] = data_df[key].nunique() feature_info = [dense_features, sparse_features, sparse_feas_map] # 这里把特征信息进行封装, 建立模型的时候作为参数传入 # 把数据构建成数据管道 dl_train_dataset = TensorDataset( # 特征信息 torch.tensor(train_set.drop(columns='Label').values).float(), # 标签信息 torch.tensor(train_set['Label'].values).float() ) dl_val_dataset = TensorDataset( # 特征信息 torch.tensor(val_set.drop(columns='Label').values).float(), # 标签信息 torch.tensor(val_set['Label'].values).float() ) dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=16) dl_vaild = DataLoader(dl_val_dataset, shuffle=True, batch_size=16) return feature_info,dl_train,dl_vaild,test_set- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
file_path = './preprocessed_data/' feature_info,dl_train,dl_vaild,test_set = prepared_data(file_path)- 1
- 2
- 3
3.2 建立DeepFM模型
from _01_deep_fm import DeepFM hidden_units = [128, 64, 32] net = DeepFM(feature_info, hidden_units)- 1
- 2
- 3
- 4
# 测试一下模型 for feature, label in iter(dl_train): out = net(feature) print(feature.shape) print(out.shape) print(out) break- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.3 模型的训练
from AnimatorClass import Animator from TimerClass import Timer # 模型的相关设置 def metric_func(y_pred, y_true): pred = y_pred.data y = y_true.data return roc_auc_score(y, pred) def try_gpu(i=0): if torch.cuda.device_count() >= i + 1: return torch.device(f'cuda:{i}') return torch.device('cpu') def train_ch(net, dl_train, dl_vaild, num_epochs, lr, device): """⽤GPU训练模型""" print('training on', device) net.to(device) # 二值交叉熵损失 loss_func = nn.BCELoss() optimizer = torch.optim.Adam(params=net.parameters(), lr=lr) animator = Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train auc', 'val loss', 'val auc'] ,figsize=(8.0, 6.0)) timer, num_batches = Timer(), len(dl_train) log_step_freq = 10 for epoch in range(1, num_epochs + 1): # 训练阶段 net.train() loss_sum = 0.0 metric_sum = 0.0 for step, (features, labels) in enumerate(dl_train, 1): timer.start() # 梯度清零 optimizer.zero_grad() # 正向传播 predictions = net(features) loss = loss_func(predictions, labels.unsqueeze(1) ) try: # 这里就是如果当前批次里面的y只有一个类别, 跳过去 metric = metric_func(predictions, labels) except ValueError: pass # 反向传播求梯度 loss.backward() optimizer.step() timer.stop() # 打印batch级别日志 loss_sum += loss.item() metric_sum += metric.item() if step % log_step_freq == 0: animator.add(epoch + step / num_batches,(loss_sum/step, metric_sum/step, None, None)) # 验证阶段 net.eval() val_loss_sum = 0.0 val_metric_sum = 0.0 for val_step, (features, labels) in enumerate(dl_vaild, 1): with torch.no_grad(): predictions = net(features) val_loss = loss_func(predictions, labels.unsqueeze(1)) try: val_metric = metric_func(predictions, labels) except ValueError: pass val_loss_sum += val_loss.item() val_metric_sum += val_metric.item() if val_step % log_step_freq == 0: animator.add(epoch + val_step / num_batches, (None,None,val_loss_sum / val_step , val_metric_sum / val_step)) print(f'final: loss {loss_sum/len(dl_train):.3f}, auc {metric_sum/len(dl_train):.3f},' f' val loss {val_loss_sum/len(dl_vaild):.3f}, val auc {val_metric_sum/len(dl_vaild):.3f}') print(f'{num_batches * num_epochs / timer.sum():.1f} examples/sec on {str(device)}')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
lr, num_epochs = 0.01, 10 train_ch(net, dl_train, dl_vaild, num_epochs, lr, try_gpu())- 1
- 2

3.4 模型的预测
y_pred_probs = net(torch.tensor(test_set.values).float()) y_pred = torch.where( y_pred_probs>0.5, torch.ones_like(y_pred_probs), torch.zeros_like(y_pred_probs) ) y_pred.data[:10]- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
-
相关阅读:
jQuery 树型菜单完整代码
Docker安装与卸载
压线生填报志愿不用愁,看这一篇就够了
uniapp开发笔记----发布成微信小程序体验版本
基于SpringBoot的医疗预约服务管理系统
MySQL注入绕安全狗脚本 -- MySQLByPassForSafeDog,以及端口爆破工具 -- PortBrute配置使用
网络工程师怎么才算开窍
HTTP与SOCKS5的区别对比
ChatGPT在机器人护理和老年人支持中的潜在角色如何?
C Primer Plus(6) 中文版 第4章 字符串和格式化输入/输出 4.3 常量和C预处理器
- 原文地址:https://blog.csdn.net/qq_44665283/article/details/132723593
