-
Meta AI的Nougat能够将数学表达式从PDF文件转换为机器可读文本
大多数科学知识通常以可移植文档格式(PDF)的形式存储,这也是互联网上第二突出的数据格式。然而,从这种格式中提取信息或将其转换为机器可读的文本具有挑战性,尤其是在涉及数学表达式时。
为了解决这个问题,以前的研究提出了光学字符识别(OCR),这是一种检测和分类图像中单个字符和单词的有效技术,通过将科学文献视为图像来处理科学文献,但它们无法捕捉句子之间的关系逐行处理句子。
在一篇新论文《Nougat:学术文献的神经光学理解》中,Meta AI研究团队提出了学术文献的神经光学理解(Nougat),这是一种视觉转换器模型,可以有效地将PDF格式存储的科学文献转换为轻量级标记语言,甚至涉及密集的数学方程式。

该团队将他们的主要贡献总结如下:
1、发布能够将PDF转换为轻量级标记语言的预训练模型。我们在 GitHub 上发布代码和模型。
2、我们引入了一个管道来创建数据集,用于将 PDF 与源代码配对。
3、我们的方法仅依赖于页面的图像,允许访问扫描的纸张和书籍。
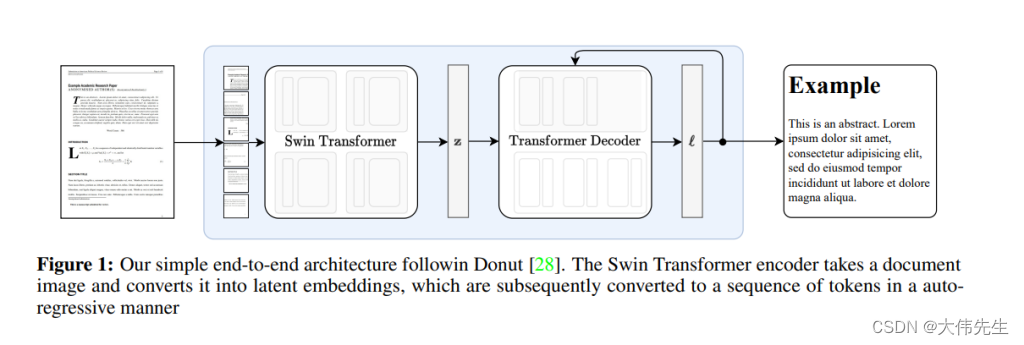
拟建的Nougat以Donut建筑为基础。Swin-Transformer编码器将文档图像作为输入,并输出一系列潜在嵌入。接下来,通过具有自回归方式的交叉关注的变换器解码器架构,将编码图像解码为令牌序列。最后,输出被投影到词汇表的大小。
值得注意的是,研究人员利用视觉文档理解的最新进展来完成新的OCR任务,但与以前的方法相反,Nougat不需要依赖OCR或嵌入式文本表示,只需要光栅化的文档页面。
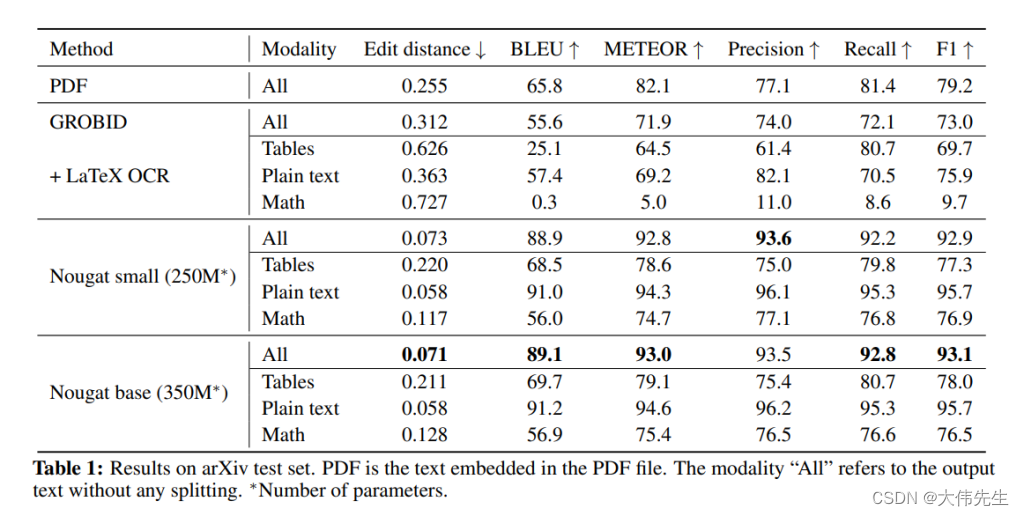
在他们的实证研究中,该团队将Nougat与基线模型GROBID进行了比较,Nougat在所有指标中都达到了最高性能,包括编辑距离,BLEU,METEOR和F-measure。
总体而言,这项工作表明,Nougat不仅具有从数字出生的PDF中提取文本的巨大潜力,而且可以处理扫描的纸张和教科书。该团队希望他们的工作可以作为未来相关领域更多研究的起点。
该代码可在项目的GitHub上找到。
论文Nougat:arXiv学术文献的神经光学理解。
-
相关阅读:
[mit6.1810] lab Utilities
ET-B32C如何让屏幕常亮(屏幕不熄灭或待机状态)
第四十四章 在CSP应用程序中本地化文本 - 显示本地化字符串的其他选项
工业智能网关BL110应用之三十九:LAN口如何配置采集Modbus协议设备S475
uboot 命令使用(4)
【漏洞复现】weblogic-10.3.6-‘wls-wsat‘-XMLDecoder反序列化(CVE-2017-10271)
【跟着大佬学JavaScript】之数组去重(结果对比)
Linux性能模拟测试
基于51单片机的音乐盒播放器proteus仿真
数据结构-单链表
- 原文地址:https://blog.csdn.net/virone/article/details/132636898