-
[github-100天机器学习]day4+5+6 Logistic regression
https://github.com/MLEveryday/100-Days-Of-ML-Code/blob/master/README.md
逻辑回归
逻辑回归用来处理不同的分类问题,这里的目的是预测当前被观察的对象属于哪个组。会给你提供一个离散的二进制输出结果,一个简单例子:判断一个人是否会在选举中投票。
how to work
逻辑回归使用基础逻辑函数通过估算概率来测量因变量和自变量间的关系。
做出预测
这些概率值必修转换成二进制数,以便实际中进行预测。这是逻辑函数sigmoid的任务,然后使用阈值分类器将(0,1)范围的值转换为0和1的值来表示结果。
区别
逻辑回归给出离散的输出
线性回归给出连续的输出sigmoid函数
一个S型曲线,可以实现将任意真实值映射为值域范围为0-1的值
θ ( s ) = \theta(s)= θ(s)= 1 1 + e − s {1\over 1+e^{-s}} 1+e−s1
极大似然估计–Maximum Likelihood Estimation
利用已知样本结果,反推最有可能导致这样结果的参数值。
用于估计参数,使得观测数据在给定模型下的概率最大化。
极大似然估计的核心思想是,选择使观测数据出现的概率最大的参数值,因为这些参数值使数据出现的可能性最高。基本原理
- 定义模型:首先,需要定义一个概率模型,通常用参数化的概率分布表示。这个模型包括一个参数向量(或参数集),需要估计。
- 建立似然函数:似然函数是关于模型参数的函数,它描述了给定参数值时观测数据的可能性。似然函数通常用 L ( θ ∣ x ) L(θ|x) L(θ∣x), θ θ θ是要估计的参数, x x x是观测数据。
- 最大化似然函数:通过找到使似然函数最大化的参数 θ θ θ,来进行估计。这通常可以通过计算似然函数的梯度,并使用数值优化方法(如梯度下降或牛顿法)来实现。
- 估计结果:得到最大似然估计就可以用它来代表参数的估计值。通常,估计的参数值具有使观测数据出现的可能性最大化的性质。
特征缩放
StandardScaler通过以下方式进行特征缩放:
计算每个特征的均值(mean)和标准差(standard deviation)。
对每个特征进行标准化,使其具有均值为0和标准差为1的分布。具体计算方式是将每个特征的值减去均值,然后除以标准差。###1 import numpy as np import matplotlib.pyplot as plt import pandas as pd dataset = pd.read_csv('Social_Network_Ads.csv') X = dataset.iloc[:, [2, 3]].values ## 选取2,3两列--Age+ salary y = dataset.iloc[:, 4].values ## 选取最后一列 #from sklearn.cross_validation import train_test_split#old from sklearn.model_selection import train_test_split, cross_val_score#new X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # 特征缩放是数据预处理的一个重要步骤,它有助于确保不同特征之间的尺度一致,避免某些特征对模型训练产生过大的影响。 from sklearn.preprocessing import StandardScaler ##特征缩放 sc = StandardScaler()# 使用了StandardScaler类来标准化特征 X_train = sc.fit_transform(X_train) # 在训练集上计算均值和标准差,并进行特征缩放 X_test = sc.transform(X_test) # 在测试集上使用相同的均值和标准差进行特征缩放- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
### 2 from sklearn.linear_model import LogisticRegression # 使用了scikit-learn(sklearn)库中的逻辑回归(Logistic Regression)模型, classifier = LogisticRegression() classifier.fit(X_train, y_train) # X_train 是训练集的特征数据,y_train 是对应的训练集目标(标签)。 # 通过拟合(fitting)逻辑回归模型,模型会学习如何根据输入特征来预测目标变量 y。- 1
- 2
- 3
- 4
- 5
- 6
- 7
### 3 y_pred = classifier.predict(X_test)# 使用训练好的模型进行预测 # predict 方法接受测试数据作为输入,然后返回模型根据输入数据的特征所做的预测。- 1
- 2
- 3
from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) # 对预测结果进行评估 # 使用了 confusion_matrix 函数来计算混淆矩阵,以便对分类模型的性能进行评估。 # 混淆矩阵是评估分类模型的一个重要工具,它显示了模型的预测结果与实际标签之间的关系- 1
- 2
- 3
- 4
- 5
具体来说,混淆矩阵包含以下四个关键指标:
真正例(True Positives,TP):模型正确预测为正类别的样本数量。
假正例(False Positives,FP):模型错误预测为正类别的样本数量。
真负例(True Negatives,TN):模型正确预测为负类别的样本数量。
假负例(False Negatives,FN):模型错误预测为负类别的样本数量。
通过这些指标,您可以计算各种性能指标,如准确率、召回率、精确度和F1分数# 计算准确率 accuracy = (TP + TN) / (TP + TN + FP + FN) # 计算召回率 recall = TP / (TP + FN) # 计算精确度 precision = TP / (TP + FP) # 计算F1分数 f1_score = 2 * (precision * recall) / (precision + recall)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
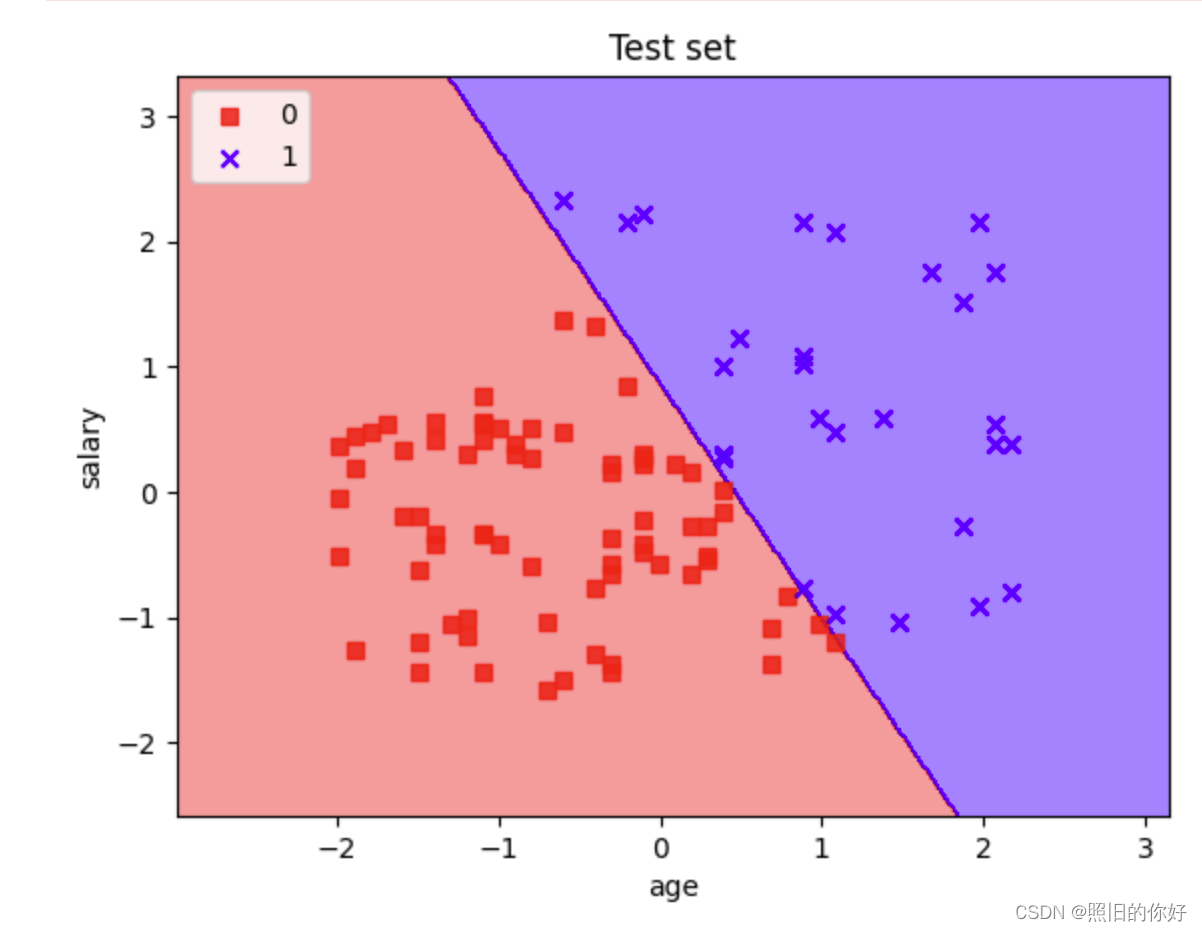
# 绘制分类器的决策边界和数据点的可视化 # 使用了matplotlib库来创建决策区域图,并将测试集的样本点可视化 import matplotlib.pyplot as plt import numpy as np from matplotlib.colors import ListedColormap def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02): # setup marker generator and color map markers = ('s', 'x', 'o', '^', 'v') colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan') cmap = ListedColormap(colors[:len(np.unique(y))]) # plot the decision surface x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution)) Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T) Z = Z.reshape(xx1.shape) plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap) plt.xlim(xx1.min(), xx1.max()) plt.ylim(xx2.min(), xx2.max()) # plot class samples for idx, cl in enumerate(np.unique(y)): plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],alpha=0.8, c=cmap(idx),marker=markers[idx], label=cl) # highlight test samples if test_idx: X_test, y_test = X[test_idx, :], y[test_idx] plt.scatter(X_test[:, 0], X_test[:, 1], c='', alpha=1.0, linewidth=1, marker='o', s=55, label='test set') plot_decision_regions(X_test, y_pred, classifier=classifier) plt.xlabel('age') plt.ylabel('salary') plt.legend(loc='upper left') plt.title("Test set") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
-
相关阅读:
使用kalibr标定工具进行单目相机和双目相机的标定
4.三种方式创建springboot项目
云借阅图书管理系统[基于SSM框架的项目]
Linux下打开ISO文件两种方法
Android 接入腾讯IM即时通信(详细图文)
Qt+FFmpeg+opengl从零制作视频播放器-3.解封装
【深度学习】 Python 和 NumPy 系列教程(四):Python容器:2、元组tuple详解(初始化、索引和切片、元组特性、常用操作、拆包、遍历)
浅谈系统稳定性与高可用保障的几种思路
代码随想录 动态规划Ⅸ
嵌入式硬件常见英文总结
- 原文地址:https://blog.csdn.net/weixin_43769170/article/details/131572614
