-
从零开始构建一个电影知识图谱,实现KBQA智能问答[上篇]:本体建模、RDF、D2RQ、SPARQL endpoint与两种交互方式详细教学

项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实战掌握技能,助力用户更好利用 CSDN 平台,自主完成项目设计升级,提升自身的硬实力。

从零开始构建一个电影知识图谱,实现KBQA智能问答[上篇]:本体建模、RDF、D2RQ、SPARQL endpoint与两种交互方式详细教学
效果展示:

首先介绍我们使用的数据、数据来源和数据获取方法;其次,基于数据内部关系,介绍如何以自顶向下的方式构建本体结构。
码源见文章顶部或者文末
https://download.csdn.net/download/sinat_39620217/87989604
1.数据准备
实践篇使用的数据是与电影相关的。基本统计数据如下:
-
演员数量:505 人
-
电影数量:4518 部
-
电影类型:19 类
-
人物与电影的关系:14451
-
电影与类型的关系:7898
演员的基本信息包括:姓名、英文名、出生日期、死亡日期、出生地、个人简介。
电影的基本信息包括:电影名称、电影简介、电影评分、电影发行日期、电影类型。
数据是从 “The Movie Database (TMDb” 网站获取的,官方提供注册用户 API KEY 用于查询和下载数据。我本来打算从豆瓣获取电影数据,但现在豆瓣 API 已经关闭了个人用户申请入口。
本实例数据获取方法:以周星驰为初始入口,获取其出演的所有电影;再获取这些电影的所有参演演员;最后获取所有参演演员所出演的全部电影。经过去重处理,我们得到了 505 个演员的基本信息和 4518 部电影的基本信息。数据保存在 mysql 中,其 ER 图如下:

读者可以直接下载我们获取到的数据,或者用我们提供的脚本自己从网站获取额外的数据,再或者根据自己的需要重新编写脚本。
2.本体建模
本体的构建大体有两种方式:自顶向下和自底向上。
-
开放域知识图谱的本体构建通常用自底向上的方法,自动地从知识图谱中抽取概念、概念层次和概念之间的关系。这也很好理解,开放的世界太过复杂,用自顶向下的方法无法考虑周全,且随着世界变化,对应的概念还在增长。
-
领域知识图谱多采用自顶向下的方法来构建本体。一方面,相对于开放域知识图谱,领域知识图谱涉及的概念和范围都是固定或者可控的;另一方面,对于领域知识图谱,我们要求其满足较高的精度。现在大家接触到的一些语音助手背后对接的知识图谱大多都是领域知识图谱,比如音乐知识图谱、体育知识图谱、烹饪知识图谱等等。正因为是这些领域知识图谱来满足用户的大多数需求,更需要保证其精度。
本实例是一个电影领域的知识图谱,我们采用自顶向下的方法来构建本体结构。首先介绍下我们使用的工具 protégé(点击进入官网下载):
Protégé,又常常简单地拼写为 “Protege”,是一个斯坦福大学开发的本体编辑和知识获取软件。开发语言采用 Java,属于开放源码软件。由于其优秀的设计和众多的插件,Protégé 已成为目前使用最广泛的本体论编辑器之一(来自维基百科)。
打开 protege,看到和下图类似的界面。在 Ontology IRI 中填写我们新建本体资源的 IRI。读者可以填写自己的符合标准的 IRI。

点击 “Entities”tab 标签,选择“Classes” 标签。在这个界面,我们创建电影知识图谱的类 / 概念。注意,所有的类都是 “Thing” 的子类。最左边红色小方框中的按钮用于创建当前选中类的子类,中间的按钮用于创建兄弟类(平行类),最右边的按钮删除当前选中的类。我们创建了三个类,“人物”、“电影”、“类别”。右下方的界面是用于描述该类的一些特性,例如:“disjoint of” 是用于表示该类与哪些类是互斥的。本例中,三个类都是互斥的。也就是说,一个实例只能是三个类中的一个。我们没有在 protege 中显式地定义互斥关系,读者可以自己定义。

接下来我们切换到 “Object Properties” 页面,我们在此界面创建类之间的关系,即,对象属性。这里我们创建了三个对象属性,“hasActedIn” 表示某人参演了某电影,因此我们在右下方的 3 号矩形框中定义该属性的 “domain” 是人,4 号框定义 “range” 是电影。这个很好理解,“domain” 表示该属性是属于哪个类的,“range” 表示该属性的取值范围。2 号框表示该属性的逆属性是 “hasActor”,即,有了推理机,尽管我们的 RDF 数据只保存了 A 出演了 B,我们在查询的时候也能得到 B 的演员有 A。1 号方框中是一些描述该属性的词汇,我们在上一篇文章中已经介绍过,这里不再赘述。同理,我们定义另外两个属性,这里不再展示。

最后,我们切换到 “Data properties”,我们在该界面创建类的属性,即,数据属性。其定义方法和对象属性类似,除了没有这么丰富的描述属性特性的词汇。其实不难理解,这些描述特性的词汇是传递、对称、反对称、自反等,表明其必定有指向其他资源或自身的边,而我们之前提到过,数据属性相当于树的叶子节点,只有入度,而没有出度。

其实区分数据属性和对象属性还有一个很直观的方法,我们观察其 “range”,取值范围即可。对象属性的取值范围是类,而数据属性的取值范围则是字面量,如下图。

protege 也支持以可视化的方式来展示本体结构。我们点击 “Window” 选项,在 “Tabs” 中选择 “OntoGraf”,然后 “Entities” 旁边就多了一个标签页。在右侧窗口中移动元素,可以很直观地观察本体之间的关系。

在这个小节,我们简单地介绍了如何用 protege 自顶向下地构建知识图谱的本体结构。对于 Protege 更详细的操作和介绍,请参考这篇文档。
3.关系数据库到 RDF

本文首先介绍 W3C 的 RDB2RDF 工作小组制定的两个标准,用于将关系型数据库的数据转换为 RDF 格式的数据。然后介绍如何利用 d2rq 这个工具把我们 Mysql 中的数据转为 RDF。
3.1 两个标准
第一个标准是 direct mapping,即直接映射。何为直接映射?。
之所以说RDFS/OWL是RDF的“衣服”,因为它们都是用来描述RDF数据的。为了不显得这么抽象,我们可以用关系数据库中的概念进行类比。用过Mysql的读者应该知道,其database也被称作schema。这个schema和我们这里提到的schema language十分类似。我们可以认为数据库中的每一张表都是一个类(Class),表中的每一行都是该类的一个实例或者对象(学过java等面向对象的编程语言的读者很容易理解)。表中的每一列就是这个类所包含的属性。如果我们是在数据库中来表示人和地点这两个类别,那么为他们分别建一张表就行了;再用另外一张表来表示人和地点之间的关系。RDFS/OWL本质上是一些预定义词汇(vocabulary)构成的集合,用于对RDF进行类似的类定义及其属性的定义。
Notice: RDFS/OWL序列化方式和RDF没什么不同,其实在表现形式上,它们就是RDF。其常用的方式主要是RDF/XML,Turtle。另外,通常我们用小写开头的单词或词组来表示属性,大写开头的表示类。数据属性(data property,实体和literal字面量的关系)通常由名词组成,而对象数据(object property,实体和实体之间的关系)通常由动词(has,is之类的)加名词组成。剩下的部分符合驼峰命名法。为了将它们表示得更清楚,避免读者混淆,之后我们都会默认这种命名方式。读者实践过程中命名方式没有强制要求,但最好保持一致。
规则十分简单:
-
数据库的表作为本体中的类(Class)。比如我们在 mysql 中保存的数据,一共有 5 张表。那么通过映射后,我们的本体就有 5 个类了,而不是我们自己定义的三个类。
-
表的列作为属性(Property)。
-
表的行作为实例 / 资源。
-
表的单元格值为字面量
-
如果单元格所在的列是外键,那么其值为 IRI,或者说实体 / 资源。
在实际应用中我们很少用到这种方法,尽管它是最便捷的方式。详细的解释和示例,请参考 W3C 的官方文档 (A Direct Mapping of Relational Data to RDF)。
Direct mapping 的缺点很明显,不能把数据库的数据映射到我们自己定义的本体上。RDB2RDF 工作小组指定了另外一个标准——R2RML,可以让用户更灵活的编辑和设置映射规则。
我不打算在这里详细地讲解 R2RML 的具体语法和规则,读者可以自己参考 W3C 的文档 (R2RML: RDB to RDF Mapping Language)。其实可以把它当做一个工具,用的时候再查文档即可,不用把所有的特性和语法都记下来,只需要知道它是什么,能干什么即可。为了让读者有个直观地认识,我们以 mysql 中的数据为例,介绍怎么把 person 这个表映射到我们在 protege 中定义的 Person 类上,person_name 映射到 personName 上。
@prefix rr:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
rr:template 指定实体 / 资源的 IRI 生成模板,括号中的字符串是对应表中的某个列名。在本例中指每个人物的 IRI 由我们预定义的前缀加人物 ID 组成。rr:Class 声明这些实体 / 资源的类是我们在 Ontology 中定义的 Person。rr:predicate 指定谓语,即属性。rr:objectMap 指定该属性的值是来源于哪一列。其他属性的定义类似,读者可以自己查文档尝试。关于外键的定义,读者也可以参考文档相关示例。
R2RML 也支持 SQL 语句来对查询结果进行映射。比如,我们有一列表示某人的性别,我们可以用 SQL 语句选取男性的行,把这些行映射成我们定义的男性类。女性同理。这种特性大大增强了其灵活性。
下面我们介绍如何用 d2rq 这个工具把 mysql 的数据转为 RDF。
3.2 D2RQ
D2RQ 的官方介绍是:
Accessing Relational Databases as Virtual RDF Graphs
没错,以虚拟 RDF 图的方式访问关系数据库是其最主要的一个特性。它的机理就是通过 mapping 文件,把对 RDF 的查询等操作翻译成 SQL 语句,最终在 RDB 上实现对应操作。在做知识图谱项目的时候,我们可以灵活地选择数据访问方式。当对外提供服务,查询操作比较频繁的情况下,最好是将 RDB 的数据直接转为 RDF,会节省很多 SPARQL 到 SQL 的转换时间。
D2RQ 提供了自己的 mapping language,其形式和 R2RML 类似。D2RQ 发布了 r2rml-kit 以支持 W3C 制定的两个映射标准。D2RQ 有一个比较方便的地方,可以根据你的数据库自动生成预定义的 mapping 文件,用户可以在这个文件上修改,把数据映射到自己的本体上。就我们这个例子而言,数据关系比较简单,自己编辑 R2RML 文件或者在 D2RQ 生成的 mapping 文件上修改效率差不多。在数据关系很复杂的时候,我建议直接在 D2RQ 生成的 mapping 文件上修改,会节省很多时间。D2RQ 的 mapping language 也很简洁,同样支持对 SQL 结果进行映射,其 SQL 是用 condition 关键词隐式地表达,不像 R2RML 是显式的 SQL 语句。更多的细节请参考官方文档。
下载 D2RQ,进入其目录,运行下面的命令生成默认的 mapping 文件:
generate-mapping -u root -o kg_demo_movie_mapping.ttl jdbc:mysql:///kg_demo_movie- 1
- 2
root 是 mysql 的用户名,没有密码则不输入,-o 指定输出文件路径及名称,jdbc:mysql:///kg_demo_movie 指定我们要映射的数据库。该命令的其他参数及使用方式请参考文档。
根据我们的 mysql 数据库生成的默认 mapping 文件:
#部分展示 @prefix map: <#> . @prefix db: <> . @prefix vocab:. @prefix rdf: . @prefix d2rq: - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
下面是根据我们定义的本体修改的 mapping 文件。首先,为了表达简练,我们给本体的 IRI 设置一个前缀。这样
http://www.kgdemo.com#Person- 1
- 2
就可以表达为
:Person- 1
- 2
其他的词汇同理。
接下来,把默认的映射词汇改为我们本体中的词汇即可。在处理外键的时候要注意当前编辑的属性的 domain 和 range,belongsToClassMap 是 domain,refersToClassMap 是 range。
#部分展示 @prefix map: <#> . @prefix db: <> . @prefix vocab:. @prefix rdf: . @prefix d2rq: - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
语法规则比较简单,具体的操作不再赘述,读者可以参考相关文档 (The D2RQ Mapping Language)。
D2RQ 支持的数据库有 Oracle、MySQL、PostgreSQL、SQL Server、HSQLDB、Interbase/Firebird。也支持其他某些数据库,但可能会有限制。请参考数据库兼容性说明 (Accessing Relational Databases as Virtual RDF Graphs)。
使用下面的命令将我们的数据转为 RDF:
.\dump-rdf.bat -o kg_demo_movie.nt .\kg_demo_movie_mapping.ttl- 1
- 2
kg_demo_movie_mapping.ttl 是我们修改后的 mapping 文件。其支持导出的 RDF 格式有 “TURTLE”, “RDF/XML”, “RDF/XML-ABBREV”, “N3”, 和“N-TRIPLE”。“N-TRIPLE” 是默认的输出格式。
kg_demo_movie.nt 中关于演员的片段:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
kg_demo_movie.nt 中关于电影的片段:
. - 1
- 2
- 3
- 4
- 5
- 6
4.D2RQ SPARQL endpoint与两种交互方式
这次我们介绍利用 D2RQ 开启 SPARQL endpoint 服务和两种交互方式:在浏览器中进行查询或者编写 python 脚本进行交互。跳过之前实践篇练习的读者,需要做的准备有:导入数据到 Mysql,下载 mapping 文件
4.1 SPARQL endpoint
前一篇介绍 SPARQL 的文章中提到,SPARQL endpoint 是 SPARQL 协议的一部分,用于处理客户端的请求,可以类比 web server 提供用户浏览网页的服务。通过 endpoint,我们可以把数据发布在网上,供用户查询。
D2RQ,是以虚拟 RDF 的方式来访问关系数据库中的数据,即我们不需要显式地把数据转为 RDF 形式。通过默认,或者自己定义的 mapping 文件,我们可以用查询 RDF 数据的方式来查询关系数据库中的数据。换个说法,D2RQ 把 SPARQL 查询,按照 mapping 文件,翻译成 SQL 语句完成最终的查询,然后把结果返回给用户。下面是 D2R Server 的架构图:

进入 d2rq 目录,使用下面的命令启动 D2R Server:
d2r-server.bat kg_demo_movie_mapping.ttl- 1
- 2
“kg_demo_movie_mapping.ttl” 是我们定义的 mapping 文件。其他参数和配置请参考官方文档。默认端口是 2020,在浏览器输入 “http://localhost:2020/”,可以看到如下界面:

红色方框 1 是我们定义的类别,点击某个类别,我们可以看到其对应的所有实例(默认显示 50 个,可以在 mapping 文件中修改服务器配置)。选中某个实例,可以看到其包含的所有属性,如下图:

点击红色方框 2 中的链接,进入 endpoint,如下图:

4.2 浏览器中查询
输入框默认的 SPARQL 查询是获取所有的 RDF 三元组,“LIMIT” 关键词指定返回结果数量的上限。点击下图红框中的 “Go!”,执行查询:

读者可以自行尝试上篇文章中的例子:
“周星驰出演了哪些电影?”

“英雄这部电影有哪些演员参演?”
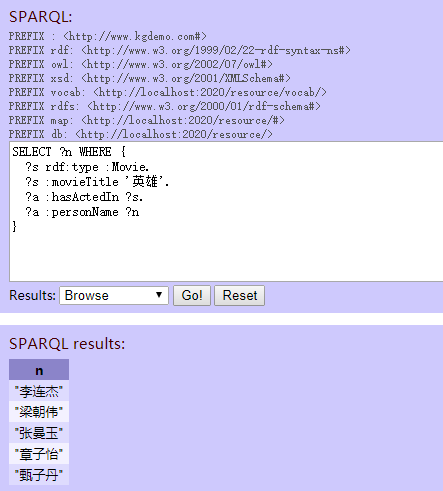
“巩俐参演的评分大于 7 的电影有哪些?”

读者也可以通过命令行的方式进行查询,具体方法请参考官方的文档。
4.3 编写 Python 脚本进行交互
构建基于知识图谱的应用,我们希望将 SPARQL 查询集成在代码当中,对其进行包装便于后续开发。这里介绍一个 Python 第三方库:SPARQLWrapper。如其名,这是一个 Python 下的包装器,可以让我们十分方便地和 endpoint 进行交互。下面是通过 SPARQLWrapper,向 D2RQ endpoint 发送查询 “巩俐参演的评分大于 7 的电影有哪些”,得到结果的代码。
from SPARQLWrapper import SPARQLWrapper, JSON sparql = SPARQLWrapper("http://localhost:2020/sparql") sparql.setQuery(""" PREFIX :- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
运行结果:
2046 Memoirs of a Geisha 荆轲刺秦王 大红灯笼高高挂 霸王别姬 活着 唐伯虎点秋香 秋菊打官司 菊豆 Hong gao liang 画魂 风月 Piao Liang Ma Ma The Hand- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
初始化 Wrapper 需要的参数是 endpoint 对外提供服务的链接,D2RQ 默认的链接是 “http://localhost:2020/sparql”。
小结总结
这篇文章简单地介绍了如何利用 D2RQ 开启 SPARQL endpoint 服务和两种进行交互的方式。D2RQ 是以虚拟 RDF 图的方式来访问关系数据库,在访问频率不高,数据变动频繁的场景下,这种方式比较合适。对于访问频率比较高的场景(比如 KBQA),将数据转为 RDF 再提供服务更为合适。接下来的实践篇我们将介绍如何利用 Apache Jena,创建基于显式 RDF 数据的 SPARQL endpoint;并展示,在加入推理机后,对数据进行本体推理我们可以得到额外的信息。
码源见文章顶部或者文末
-
-
相关阅读:
前端清除所有cookie
ES的索引结构与算法解析
如何使用 Nginx 部署 React App 到 linux server
怎样评测对比报表工具的性能?
48MySQL数据库基础
【周报2023-11-17】
LTE小区搜索过程及SCH/BCH设计
无叶风扇32位MCU单片机MM32SPIN0230
在小程序中对flex布局的理解
[论文阅读]SSN——基于形状特征网络的点云多类目标检测
- 原文地址:https://blog.csdn.net/sinat_39620217/article/details/131662574
