-
最小二乘法求导-公式推导
多元线性回归模型
1. 建立模型:模型函数
Y ^ = X W T \hat{Y} = XW^T Y^=XWT
如果有 n+1 条数据,每条数据有 m+1 种x因素(每种x因素都对应 1 个权重w),则
👉已知数据:实际Y值= [ y 0 y 1 y 2 y 3 . . . y n ]y0y1y2y3...yn ,X= [ x 00 , x 10 . . . x m 0 x 01 , x 11 . . . x m 1 x 02 , x 12 . . . x m 2 x 03 , x 13 . . . x m 3 . . . x 0 n , x 1 n . . . x m n ][ y 0 y 1 y 2 y 3 . . . y n ] x00,x10...xm0x01,x11...xm1x02,x12...xm2x03,x13...xm3...x0n,x1n...xmn [ x 00 , x 10 . . . x m 0 x 01 , x 11 . . . x m 1 x 02 , x 12 . . . x m 2 x 03 , x 13 . . . x m 3 . . . x 0 n , x 1 n . . . x m n ]

👉未知数据:模型 Y ^ \hat{Y} Y^值= [ y 0 ^ y 1 ^ y 2 ^ . . . y n ^ ]y0^y1^y2^...yn^ 模型参数 W= [ w 0 , w 1 , w 2 , w 3 , . . . , w m ][ y 0 ^ y 1 ^ y 2 ^ . . . y n ^ ] [w0,w1,w2,w3,...,wm][ w 0 , w 1 , w 2 , w 3 , . . . , w m ] 2. 学习模型:损失函数
2.1 损失函数-最小二乘法
Loss = ∑ ( y ^ i 计算 − y i 实际 ) 2 ∑(\hat{y}_{i计算}-y_{i实际})² ∑(y^i计算−yi实际)2
Y 计算 ^ \hat{Y_{计算}} Y计算^= [ y 0 ^ y 1 ^ y 2 ^ . . . y n ^ ]
y0^y1^y2^...yn^ , 实际Y值= [ y 0 y 1 y 2 . . . y n ][ y 0 ^ y 1 ^ y 2 ^ . . . y n ^ ] y0y1y2...yn , Y 计算 ^ − Y \hat{Y_{计算}} -Y Y计算^−Y= [ y 0 ^ − y 0 y 1 ^ − y 1 y 2 ^ − y 2 . . . y n ^ − y n ][ y 0 y 1 y 2 . . . y n ] y0^−y0y1^−y1y2^−y2...yn^−yn [ y 0 ^ − y 0 y 1 ^ − y 1 y 2 ^ − y 2 . . . y n ^ − y n ]
则Loss = [ y 0 ^ − y 0 , y 1 ^ − y 1 , y 2 ^ − y 2 , . . . , y n ^ − y n ] [ y 0 ^ − y 0 y 1 ^ − y 1 y 2 ^ − y 2 . . . y n ^ − y n ][ y 0 ^ − y 0 , y 1 ^ − y 1 , y 2 ^ − y 2 , . . . , y n ^ − y n ] [y0^−y0,y1^−y1,y2^−y2,...,yn^−yn] y0^−y0y1^−y1y2^−y2...yn^−yn [ y 0 ^ − y 0 y 1 ^ − y 1 y 2 ^ − y 2 . . . y n ^ − y n ]
Loss = ( Y 计算 ^ − Y ) T ( Y 计算 ^ − Y ) (\hat{Y_{计算}} -Y)^T(\hat{Y_{计算}} -Y) (Y计算^−Y)T(Y计算^−Y)👉 Y 计算 ^ = X T W \hat{Y_{计算}} = X^TW Y计算^=XTW,因此 Loss = ( X T W − Y ) T ( X T W − Y ) (X^TW-Y)^T(X^TW-Y) (XTW−Y)T(XTW−Y)
( X T W − Y ) T = W T X − Y T = W T X − Y T (X^TW-Y)^T=W^TX-Y^T= W^TX-Y^T (XTW−Y)T=WTX−YT=WTX−YT
则 Loss = ( X T W − Y ) T ( X T W − Y ) = W X T X W T − Y T X W T − W X T Y + Y T Y (X^TW-Y)^T(X^TW-Y)=WX^TXW^T-Y^TXW^T-WX^TY+Y^TY (XTW−Y)T(XTW−Y)=WXTXWT−YTXWT−WXTY+YTY
2.2 求导解析解
👉 ∂ ( L o s s ) ∂ ( W ) = ∂ ( W X T X W T ) ∂ ( W ) − ∂ ( Y T X W T ) ∂ ( W ) − ∂ ( W X T Y ) ∂ ( W ) + ∂ ( Y T Y ) ∂ ( W ) \frac{∂(Loss)}{∂(W)} =\frac{∂(WX^TXW^T)}{∂(W)}-\frac{∂(Y^TXW^T)}{∂(W)}-\frac{∂(WX^TY)}{∂(W)}+\frac{∂(Y^TY)}{∂(W)} ∂(W)∂(Loss)=∂(W)∂(WXTXWT)−∂(W)∂(YTXWT)−∂(W)∂(WXTY)+∂(W)∂(YTY)
根据以下矩阵求导证明:

👉 ∂ ( L o s s ) ∂ ( W ) = ∂ ( W X T X W T ) ∂ ( W ) − ∂ ( Y T X W T ) ∂ ( W ) − ∂ ( W X T Y ) ∂ ( W ) + ∂ ( Y T Y ) ∂ ( W ) \frac{∂(Loss)}{∂(W)} =\frac{∂(WX^TXW^T)}{∂(W)}-\frac{∂(Y^TXW^T)}{∂(W)}-\frac{∂(WX^TY)}{∂(W)}+\frac{∂(Y^TY)}{∂(W)} ∂(W)∂(Loss)=∂(W)∂(WXTXWT)−∂(W)∂(YTXWT)−∂(W)∂(WXTY)+∂(W)∂(YTY)
👉 ∂ ( L o s s ) ∂ ( W ) = 2 X T X W − 2 X T Y \frac{∂(Loss)}{∂(W)} =2X^TXW-2X^TY ∂(W)∂(Loss)=2XTXW−2XTY
👉当 ∂ ( L o s s ) ∂ ( W ) = 0 ,则 W = 1 2 ∗ ( X T X ) − 1 ( 2 X T Y ) = ( X T X ) − 1 ( X T Y ) \frac{∂(Loss)}{∂(W)}=0,则W =\frac{1}{2}*(X^TX)^{-1}(2X^TY)=(X^TX)^{-1}(X^TY) ∂(W)∂(Loss)=0,则W=21∗(XTX)−1(2XTY)=(XTX)−1(XTY)
当 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1计算时,只有当 X T X X^TX XTX为满秩矩阵时,W才有解
当 W = ( X T X ) − 1 ( X T Y ) W=(X^TX)^{-1}(X^TY) W=(XTX)−1(XTY)时,👉 ∂ ( L o s s ) ∂ ( W ) = 0 \frac{∂(Loss)}{∂(W)}=0 ∂(W)∂(Loss)=0,
仅仅能证明Loss取到极值,并不能说明是极小值,还是极大值!(实际最小二乘法,本质就是个凸函数-平方和函数,也不用下列证明)要如何判断Loss是极大值还是极小值?
当Loss处于极小值点时,一阶导 L o s s ′ = d ( L o s s ) W = 0 Loss^{'}=\frac{d(Loss)}{W}=0 Loss′=Wd(Loss)=0,二阶导 L o s s ′ ′ > 0 Loss^{''}>0 Loss′′>0
当Loss处于极大值点时,一阶导 L o s s ′ = d ( L o s s ) W = 0 Loss^{'}=\frac{d(Loss)}{W}=0 Loss′=Wd(Loss)=0,二阶导 L o s s ′ ′ < 0 Loss^{''}<0 Loss′′<0

已知最小二乘法损失函数一阶导 L o s s ′ = d ( L o s s ) W = ∂ ( L o s s ) ∂ ( W ) = 2 X X T W − 2 X Y T Loss^{'}=\frac{d(Loss)}{W}=\frac{∂(Loss)}{∂(W)} =2XX^TW-2XY^T Loss′=Wd(Loss)=∂(W)∂(Loss)=2XXTW−2XYT
则二阶导为 L o s s ′ ′ = d ( 2 X X T W − 2 X Y T ) W = 2 X X T = 2 ∗ [ x 00 , x 10 . . . x m 0 x 01 , x 11 . . . x m 1 x 02 , x 12 . . . x m 2 x 03 , x 13 . . . x m 3 . . . x 0 n , x 1 n . . . x m n ] [ x 00 , x 01 . . . x 0 n x 10 , x 11 . . . x 1 n x 20 , x 21 . . . x 2 n x 30 , x 31 . . . x 3 n . . . x m 0 , x m 1 . . . x m n ] = [ x 00 2 , . . . , . . . , . . . , . . . . . . , x 11 2 . . . . , . . . , . . . . . . , . . . , x 33 2 , . . . , . . . . . . , . . . , . . . , . . . , x m n 2 ] Loss^{''}=\frac{d(2XX^TW-2XY^T)}{W}=2XX^T=2*[ x 00 , x 10 . . . x m 0 x 01 , x 11 . . . x m 1 x 02 , x 12 . . . x m 2 x 03 , x 13 . . . x m 3 . . . x 0 n , x 1 n . . . x m n ] =[ x 00 , x 01 . . . x 0 n x 10 , x 11 . . . x 1 n x 20 , x 21 . . . x 2 n x 30 , x 31 . . . x 3 n . . . x m 0 , x m 1 . . . x m n ] Loss′′=Wd(2XXTW−2XYT)=2XXT=2∗ x00,x10...xm0x01,x11...xm1x02,x12...xm2x03,x13...xm3...x0n,x1n...xmn x00,x01...x0nx10,x11...x1nx20,x21...x2nx30,x31...x3n...xm0,xm1...xmn = x002,...,...,...,......,x112....,...,......,...,x332,...,......,...,...,...,xmn2 [ x 00 ² , . . . , . . . , . . . , . . . . . . , x 11 ² . . . . , . . . , . . . . . . , . . . , x 33 ² , . . . , . . . . . . , . . . , . . . , . . . , x m n ² ] 由于主元全为正数,且矩阵对称,因此二阶导数矩阵为正定实对称矩阵,特征值全大于0
马马虎虎…地…对于正定矩阵、实对称矩阵已经懵圈

2.3 迭代近似解-梯度下降法
参数迭代公式: w k + 1 = w k − η ∗ d ( L o s s k ) d w k w_{k+1} = w_k-η*\frac{d(Loss_k)}{dw_k} wk+1=wk−η∗dwkd(Lossk)
沿着梯度的方向,正常情况下,Loss值会逐渐减小。
但当达到最小值后,下一次迭代,Loss值就会逐渐变大,因此当迭代后的Loss值比上次迭代的Loss值大,即 L o s s k + 1 > L o s s k Loss_{k+1}>Loss_{k} Lossk+1>Lossk就停止迭代。并取上次迭代的Loss值(即 L o s s k Loss_k Lossk)作为最终损失函数值,以上次迭代的 W k W_k Wk参数,为模型参数。但有时迭代次数过大,会导致训练很久很久很久,因此,可以设置一个最大迭代次数。
当迭代次数超过最大迭代次数后,仍未找到极值点 L o s s k Loss_k Lossk,则停止迭代。(可修改参数初始值或学习率后,重新训练)
因此,迭代停止的条件为两个:
L o s s k + 1 > L o s s k Loss_{k+1}>Loss_{k} Lossk+1>Lossk 或 超过最大迭代次数不过!!! L o s s k + 1 > L o s s k Loss_{k+1}>Loss_{k} Lossk+1>Lossk 并不意味着取到极小值,因为又可能迭代步长过长,使Loss超过极值点,因此,一般可以限制一个Loss差值范围,但这个差值范围要设置为多少呢???
这又是一门学问了,我还不懂、、、、另外,有可能出现反复震荡,无法收敛到极小值的现象,那怎么办。。。凉拌
简单点:迭代停止的条件为-超过最大迭代次数,或迭代后的 L o s s k + 1 > L o s s k Loss_{k+1}>Loss_{k} Lossk+1>Lossk
3. 手动代码实现
# 1. 建立模型:多元线性回归模型 rows,columns = X.shape X = np.array(X) W = np.zeros(columns+1) X_0 = np.ones((rows,1)) X = np.concatenate((X_0,X),axis=1) Y_hat = np.matmul(X,W.T) # 创建多元线性回归模型 # print(Y.shape,Y_hat.shape) # 2. 学习模型:损失函数模型+优化算法 # 求导法 def learn_model(X,Y,Y_hat): W = np.matmul((np.matmul(X.T,X))**-1,np.matmul(X.T,Y)) Y_hat = np.matmul(X,W.T) Loss = np.sum((Y - Y_hat) *(Y - Y_hat)) print("——————————求导法——————————") print(f'模型参数W为:{W}') print(f"最终损失值为{round(Loss, 2)}") return W,Loss,Y_hat # 梯度下降法 def gradient_down(Y_hat,W): Loss1 = np.sum((Y - Y_hat) *(Y - Y_hat)) Loss = np.sum((Y - Y_hat) *(Y - Y_hat)) η = 0.01 # np.arange([0.1 for i in range(columns)]) # 设置学习率η times = 30 # Y_hat = X*(W.T) while Loss1 <= Loss and times!=0: Loss = Loss1 gradient = 2*np.matmul(np.matmul(X.T,X),W) - 2*np.matmul(X.T,Y) W = W - η * gradient Y_hat = np.matmul(X,W.T) Loss1 = np.sum((Y - Y_hat) *(Y - Y_hat)) # print(f"第{31-times}次迭代,损失值为:{round(Loss,2)}") times -= 1 print("——————————迭代法——————————") print(f"最终迭代次数为{30-times},损失值为{round(Loss,2)}") print(f'模型参数W为:{W}') learn_model(X,Y,Y_hat) gradient_down(Y_hat,W)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
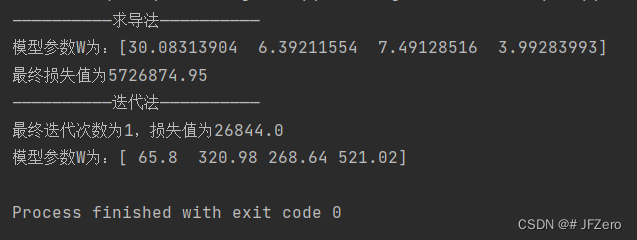
3.1 求导法的实践问题
我不理解!!!!!!!为什么求导法得出的LOSS值,居然大于梯度下降法迭代1次的Loss值
why???
what’s wrong with my 程序。。。。虽然没有进行归一化处理。。。但也不至于这么个结果啊!
于是,进行一下归一化处理# 归一化处理 datas_1 = (datas_1-datas_1.min())/(datas_1.max()-datas_1.min())- 1
- 2

I don’t understand
实际进行多元线性回归时,是不需要进行归一化的。因为预测Y的实值 Y ^ = X W T \hat{Y}=XW^T Y^=XWT,对X归一化后,数值大小发生了改变,预测出的实值也不再是原本的数值大小。
就像是原本收益Y一般是1000的,归一化后预测就会变得非常小,例如0.9
猜想:迭代法的W = ( X T X ) − 1 ( X T Y ) W=(X^TX)^{-1}(X^TY) W=(XTX)−1(XTY),要求 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1是满秩矩阵,但实际数据的 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1并不是满秩矩阵,但numpy也能求出非满秩矩阵的逆矩阵,猜测,可以是伪逆矩阵求解。。。。【不懂,我胡说八道…】总之,求导法实际不太可行。
3.1 梯度下降法的实践问题
梯度下降法有个很大的问题,很大很大的问题,学习率η的选取问题!!!!big problem
唉,懒得复盘了
η小小的改变,迭代效果差距非常大!!!!!!!!
看网上说,η也应该随着切线斜率同步改变的,但是。。。。。懒得想了
还不如直接就多运行几次,慢慢调整一下η的值就好

对比一下手动训练模型和sklearn训练模型的速度查了一下sklearn的官方文档,说是用随机梯度下降法,但具体的实现没有曝光
但是,sklearn的速度好快啊!!!!!我…是它的670倍。。。。。。。。呵呵。。。调包侠岂不是更快活!!!

import pandas as pd import numpy as np from sklearn import linear_model import time import matplotlib.pyplot as plt # 获取所需数据:'推荐分值', '专业度','回复速度','用户群活跃天数' datas = pd.read_excel('./datas1.xlsx') important_features = ['推荐分值', '辅导老师专业度','回复速度','群活跃天数'] datas_1 = datas[important_features] # 明确实值Y为'推荐分值',X分别为'专业度','回复速度','用户群活跃天数' Y = datas_1['推荐分值'] X_original = datas_1.drop('推荐分值',axis=1) # 1. 建立模型:多元线性回归模型 rows,columns = X_original.shape X_original = np.array(X_original) X_0 = np.ones((rows,1)) X = np.concatenate((X_0,X_original),axis=1) # 计时器:这是计时装饰器函数,参数 func 是被装饰的函数 def cal_time(func): def wrapper(*args, **kw): start_time = time.time() func(*args, **kw) end_time = time.time() print(f'用时:{end_time-start_time}秒\n') return wrapper # 2. 学习模型:损失函数模型+优化算法 # 求导法 @cal_time def learn_model(): W = np.matmul((np.matmul(X.T,X))**-1,np.matmul(X.T,Y)) Y_hat = np.matmul(X,W.T) Loss = np.sum((Y - Y_hat) *(Y - Y_hat)) print("——————————手动:求导法——————————") print(f'模型参数W为:{W}') print(f"最终损失值为{round(Loss, 2)}") return W,Loss,Y_hat # 梯度下降法 @cal_time def gradient_down(): W0 = np.zeros(columns + 1) Y_hat = np.matmul(X, W0.T) # 创建多元线性回归模型 Loss0 = np.sum((Y - Y_hat) *(Y - Y_hat)) a = 0.00002 # 设置学习率a times = 10000000 num = 0 while num <= times: gradient = 2*np.matmul(np.matmul(X.T,X),W0) - 2*np.matmul(X.T,Y) W1 = W0 - a * gradient Y_hat = np.matmul(X,W1.T) Loss1 = np.sum((Y - Y_hat) *(Y - Y_hat)) if Loss1 > Loss0: break # print(f"第{num+1}次迭代,损失值为:{round(Loss0,2)}") num += 1 Loss0 = Loss1 W0 = W1 print("——————————手动:梯度下降法——————————") print(f'模型参数W为:{W0}') print(f"最终迭代次数为{num+1},损失值为{round(Loss0,2)}") # sklearn的坐标下降法 @cal_time def sklearn_mulreg(): # 1. 建立模型 reg = linear_model.LinearRegression() # 2. 学习模型 reg.fit(X_original, Y) w = reg.coef_ b = reg.intercept_ print("——————————sklearn:随机梯度下降法——————————") print(f'模型参数W为:{w,b}') Y_hat = np.matmul(X_original, w)+b Loss = np.sum((Y - Y_hat) * (Y - Y_hat)) print(f"加了正则化,最终损失值为{round(Loss,2)}") learn_model() gradient_down() sklearn_mulreg()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
-
相关阅读:
JS07_回调函数与异步编程
使用 Tailwind CSS 自定义基础样式层
算法 学习杂谈
羧甲基荧光素6-FAM修饰聚缩醛Polyacetal/HA透明质酸纳米载体6-FAM-Polyacetal|6-FAM-HA(齐岳)
身份认证与提权攻击中的专属名词与缩略语整理
Rust基础知识讲解
Java 8的18个常用日期处理
软件项目管理==风险计划
支持向量机--svm.SVC类
GitHub 报告发布:TypeScript 取代 Java 成为第三受欢迎语言
- 原文地址:https://blog.csdn.net/weixin_50348308/article/details/130861622
