论文信息
论文标题:CosFace: Large Margin Cosine Loss for Deep Face Recognition 论文作者:H. Wang, Yitong Wang, Zheng Zhou, Xing Ji, Zhifeng Li, Dihong Gong, Jin Zhou, Wei Liu 论文来源:2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition 论文地址:download 论文代码:download 引用次数:1594
1 介绍 当前提出的损失函数缺乏良好的鉴别能力,所以本文基于 “最大化类间方差和最小化类内方差” 的思想提出了 大边际余弦损失(LMCL)。
2 方法 2.1 引入 Softmax " role="presentation">Softmax Softmax
L s = 1 N ∑ i = 1 N − log p i = 1 N ∑ i = 1 N − log e f y i ∑ j = 1 C e f j ( 1 ) " role="presentation">L s = 1 N ∑ N i = 1 − log p i = 1 N ∑ N i = 1 − log e f y i ∑ C j = 1 e f j ( 1 ) L s = 1 N ∑ i = 1 N − log p i = 1 N ∑ i = 1 N − log e f y i ∑ j = 1 C e f j ( 1 )
其中,
f j = W j T x = ‖ W j ‖ ‖ x ‖ cos θ j f j = W T j x = ∥ W j ∥ ∥ x ∥ cos θ j f j = W j T x = ‖ W j ‖ ‖ x ‖ cos θ j
Note :θ j θ j θ j W j W j W j x " role="presentation">x x
分类任务的期望,是使得各个类别的数据均匀分布在超球面上。
NSL 损失 :【 固定权重向量 W " role="presentation">W W ‖ W ‖ = s " role="presentation">∥ W ∥ = s ‖ W ‖ = s x " role="presentation">x x ‖ x ‖ = s " role="presentation">∥ x ∥ = s ‖ x ‖ = s
L n s = 1 N ∑ i − log e s cos ( θ y i , i ) ∑ j e s cos ( θ j , i ) ( 3 ) " role="presentation">L n s = 1 N ∑ i − log e s cos ( θ y i , i ) ∑ j e s cos ( θ j , i ) ( 3 ) L n s = 1 N ∑ i − log e s cos ( θ y i , i ) ∑ j e s cos ( θ j , i ) ( 3 )
通过固定 ‖ x ‖ = s " role="presentation">∥ x ∥ = s ‖ x ‖ = s
例如,考虑二分类的情况,设 θ i θ i θ i C i C i C i i = 1 , 2 " role="presentation">i = 1 , 2 i = 1 , 2 C 1 C 1 C 1 cos ( θ 1 ) > cos ( θ 2 ) cos ( θ 1 ) > cos ( θ 2 ) cos ( θ 1 ) > cos ( θ 2 ) C 2 C 2 C 2
由于 NSL 学习到的特征没有足够的可区分性,只强调正确的分类。所以,本文在分类边界中引入余弦间隔,纳入 Softmax 的余弦公式中。
为开发一个大间隔分类器,进一步需要 cos ( θ 1 ) − m > cos ( θ 2 ) cos ( θ 1 ) − m > cos ( θ 2 ) cos ( θ 1 ) − m > cos ( θ 2 ) cos ( θ 2 ) − m > cos ( θ 1 ) cos ( θ 2 ) − m > cos ( θ 1 ) cos ( θ 2 ) − m > cos ( θ 1 ) m ≥ 0 " role="presentation">m ≥ 0 m ≥ 0 cos ( θ i ) − m " role="presentation">cos ( θ i ) − m cos ( θ i ) − m cos ( θ i ) cos ( θ i ) cos ( θ i )
L l m c = 1 N ∑ i − log e s ( cos ( θ y i , i ) − m ) e s ( cos ( θ y i , i ) − m ) + ∑ j ≠ y i e s cos ( θ j , i ) ( 4 ) " role="presentation">L l m c = 1 N ∑ i − log e s ( cos ( θ y i , i ) − m ) e s ( cos ( θ y i , i ) − m ) + ∑ j ≠ y i e s cos ( θ j , i ) ( 4 ) L l m c = 1 N ∑ i − log e s ( cos ( θ y i , i ) − m ) e s ( cos ( θ y i , i ) − m ) + ∑ j ≠ y i e s cos ( θ j , i ) ( 4 )
其中,
W = W ∗ ‖ W ∗ ‖ x = x ∗ ‖ x ∗ ‖ cos ( θ j , i ) = W j T x i ( 5 ) " role="presentation">W = W ∗ ∥ W ∗ ∥ x = x ∗ ∥ x ∗ ∥ cos ( θ j , i ) = W T j x i ( 5 ) W = W ∗ ‖ W ∗ ‖ x = x ∗ ‖ x ∗ ‖ cos ( θ j , i ) = W j T x i ( 5 )
2.2 方法对比
Softmax " role="presentation">Softmax Softmax 【m a g i n < 0 " role="presentation">m a g i n < 0 m a g i n < 0
‖ W 1 ‖ cos ( θ 1 ) = ‖ W 2 ‖ cos ( θ 2 ) ∥ W 1 ∥ cos ( θ 1 ) = ∥ W 2 ∥ cos ( θ 2 ) ‖ W 1 ‖ cos ( θ 1 ) = ‖ W 2 ‖ cos ( θ 2 )
边界依赖于权重向量的大小和角度的余弦,这导致在余弦空间中存在一个重叠的决策区域。
NSL " role="presentation">NSL NSL 【m a g i n = 0 " role="presentation">m a g i n = 0 m a g i n = 0
cos ( θ 1 ) = cos ( θ 2 ) cos ( θ 1 ) = cos ( θ 2 ) cos ( θ 1 ) = cos ( θ 2 )
通过去除径向变化,NSL 能够在余弦空间中完美地分类测试样本。然而,由于没有决策边际,它对噪声的鲁棒性并不大:决策边界周围的任何小的扰动都可以改变决策。
A-Softmax " role="presentation">A-Softmax A-Softmax
C 1 : cos ( m θ 1 ) ≥ cos ( θ 2 ) C 2 : cos ( m θ 2 ) ≥ cos ( θ 1 ) C 1 : cos ( m θ 1 ) ≥ cos ( θ 2 ) C 2 : cos ( m θ 2 ) ≥ cos ( θ 1 ) C 1 : cos ( m θ 1 ) ≥ cos ( θ 2 ) C 2 : cos ( m θ 2 ) ≥ cos ( θ 1 )
对于 C 1 C 1 C 1 θ 1 ≤ θ 2 m θ 1 ≤ θ 2 m θ 1 ≤ θ 2 m Margin " role="presentation">Margin Margin W 1 W 1 W 1 W 2 W 2 W 2 W 1 W 1 W 1 W 2 W 2 W 2 Margin " role="presentation">Margin Margin
LMCL " role="presentation">LMCL LMCL
C 1 : cos ( θ 1 ) ≥ cos ( θ 2 ) + m C 2 : cos ( θ 2 ) ≥ cos ( θ 1 ) + m C 1 : cos ( θ 1 ) ≥ cos ( θ 2 ) + m C 2 : cos ( θ 2 ) ≥ cos ( θ 1 ) + m C 1 : cos ( θ 1 ) ≥ cos ( θ 2 ) + m C 2 : cos ( θ 2 ) ≥ cos ( θ 1 ) + m
因此,cos ( θ 1 ) cos ( θ 1 ) cos ( θ 1 ) cos ( θ 2 ) cos ( θ 2 ) cos ( θ 2 ) C 1 C 1 C 1 Figure 2 " role="presentation">Figure 2 Figure 2 LMCL " role="presentation">LMCL LMCL Margin " role="presentation">Margin Margin 2 m " role="presentation">2 – √ m 2 m
2.3 特征归一化 特征归一化的必要性包括两个方面:
没有归一化之前的 Softmax " role="presentation">Softmax Softmax L 2 L 2 L 2 L 2 L 2 L 2 同时希望所有数据的特征向量都具有相同的二范数,以至于取决于余弦角来增强判别性能。在超球面上,来自相同类别的特征向量被聚类在一起,而来自不同类别的特征向量被拉开;
比如假设特征向量为 x x x cos ( θ i ) cos ( θ i ) cos ( θ i ) cos ( θ j ) cos ( θ j ) cos ( θ j ) ‖ x ‖ ( cos ( θ i ) − m ) > ‖ x ‖ ( cos ( θ j ) ) ∥ x ∥ ( cos ( θ i ) − m ) > ∥ x ∥ ( cos ( θ j ) ) ‖ x ‖ ( cos ( θ i ) − m ) > ‖ x ‖ ( cos ( θ j ) ) ( cos ( θ i ) − m ) < cos ( θ j ) ( cos ( θ i ) − m ) < cos ( θ j ) ( cos ( θ i ) − m ) < cos ( θ j ) ‖ x ‖ " role="presentation">∥ x ∥ ‖ x ‖ 此外尺度参数 s " role="presentation">s s s " role="presentation">s s s " role="presentation">s s 接下来分析 s " role="presentation">s s x " role="presentation">x x W " role="presentation">W W C " role="presentation">C C p W p W p W W " role="presentation">W W s " role="presentation">s s
s ≥ C − 1 C log ( C − 1 ) P W 1 − P W ( 6 ) " role="presentation">s ≥ C − 1 C log ( C − 1 ) P W 1 − P W ( 6 ) s ≥ C − 1 C log ( C − 1 ) P W 1 − P W ( 6 )
可以分析出,如果在类别数保持一定情况下,想要得到最佳的 p W p W p W s s s p W p W p W s s s
2.4 LMCL的理论分析 选择合适的 Margin " role="presentation">Margin Margin Margin " role="presentation">Margin Margin
考虑二分类问题,类别分别是 C 1 C 1 C 1 C 2 C 2 C 2 x " role="presentation">x x W i W i W i W i W i W i x " role="presentation">x x θ i θ i θ i cos ( θ 1 ) = cos ( θ 2 ) cos ( θ 1 ) = cos ( θ 2 ) cos ( θ 1 ) = cos ( θ 2 ) W 1 W 1 W 1 W 2 W 2 W 2 L M C L L M C L L M C L C 1 C 1 C 1 cos ( θ 1 ) − m = cos ( θ 2 ) cos ( θ 1 ) − m = cos ( θ 2 ) cos ( θ 1 ) − m = cos ( θ 2 ) θ 1 θ 1 θ 1 θ 2 θ 2 θ 2
我们发现 Margin 与 W 1 W 1 W 1 W 2 W 2 W 2 W 1 W 1 W 1 W 2 W 2 W 2 i " role="presentation">i i i " role="presentation">i i W i W i W i i " role="presentation">i i
理论上 m " role="presentation">m m 0 ≤ m ≤ ( 1 − max ( W i T W j ) ) , i ≠ j " role="presentation">0 ≤ m ≤ ( 1 − max ( W T i W j ) ) , i ≠ j 0 ≤ m ≤ ( 1 − max ( W i T W j ) ) , i ≠ j softmax " role="presentation">softmax softmax
0 ≤ m ≤ 1 − cos 2 π C , ( K = 2 ) 0 ≤ m ≤ C C − 1 , ( C ≤ K + 1 ) 0 ≤ m ≪ C C − 1 , ( C > K + 1 ) ( 7 ) " role="presentation">0 ≤ m ≤ 1 − cos 2 π C , ( K = 2 ) 0 ≤ m ≤ C C − 1 , ( C ≤ K + 1 ) 0 ≤ m ≪ C C − 1 , ( C > K + 1 ) ( 7 ) 0 ≤ m ≤ 1 − cos 2 π C , ( K = 2 ) 0 ≤ m ≤ C C − 1 , ( C ≤ K + 1 ) 0 ≤ m ≪ C C − 1 , ( C > K + 1 ) ( 7 )
C " role="presentation">C C K " role="presentation">K K Margin " role="presentation">Margin Margin m " role="presentation">m m m " role="presentation">m m
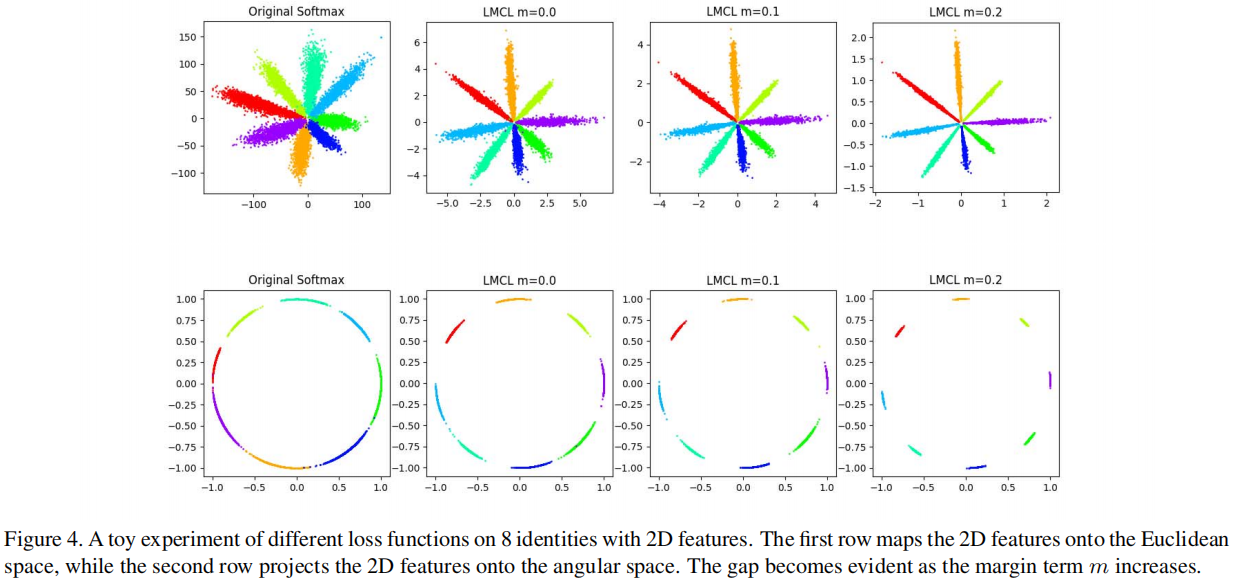
作者做了一个小实验验证了这些思想,取了 8 个人的人脸数据,用原始的 Softmax " role="presentation">Softmax Softmax m " role="presentation">m m 1 − cos ( 2 π 8 ) 1 − cos ( 2 π 8 ) 1 − cos ( 2 π 8 ) 0.29 " role="presentation">0.29 0.29 m = 0 , 0.1 , 0.2 " role="presentation">m = 0 , 0.1 , 0.2 m = 0 , 0.1 , 0.2 softmax " role="presentation">softmax softmax m " role="presentation">m m Margin " role="presentation">Margin Margin
__EOF__
-
本文作者: Blair 本文链接: https://www.cnblogs.com/BlairGrowing/p/17247447.html 关于博主: I am a good person 版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处! 声援博主: 如果您觉得文章对您有帮助,可以点击文章右下角【推荐 】