-
【JavaEE】JUC(java.util.concurrent)的常见类以及线程安全的集合类
目录
1、JUC(java.util.concurrent)的常见类
1.2.1、ReentrantLock和synchronized的区别
2.3.1、HashTable和ConcurrentHashMap的区别
1、JUC(java.util.concurrent)的常见类
JUC就是取java.util.concurrent的三个单词的首字母。所以JUC中存放的就是Java多线程开发使用到的工具类。
1.1、Callable接口的用法(创建线程的一种写法)
- Callable接口非常类似于Runnable接口,Runnable接口通过run方法描述一个任务,表示一个线程要干啥,但是run方法的返回值类型是void,不能返回一个任务的结果产出。
- 而Callable方法是通过重写call()方法,来描述一个线程执行的任务,在完成结果之后,可以返回一个计算结果。
这里我们通过一个代码来了解Callable接口
创建线程计算1+2+3+.....+1000,使用Callable版本
- 创建一个匿名内部类,实现Callable接口,Callable带有泛型参数,泛型参数表示返回值的类型
- 重写Callable的call方法,完成累加的过程,直接通过返回值返回计算结果。
- 把callable实例使用FutuerTask包装一下
- 创建线程,线程的构造方法传入FutureTask,此时新线程就会执行FutureTask内部的Callable的call方法,完成计算,计算结果就放到FutureTask对象中。
- 在主线程中调用futureTask.get()能够阻塞等待新线程计算完毕,并获取到FutureTask中的结果。
- public class TestDemo27 {
- public static void main(String[] args) throws ExecutionException, InterruptedException {
- //创建一个任务
- Callable
callable = new Callable () { - @Override
- public Integer call() throws Exception {
- int sum = 0;
- for (int i = 1; i < 1000; i++) {
- sum += i;
- }
- return sum;
- }
- };
- //创建一个线程,来执行第一个任务
- //Thread构造方法 不能直接将callable对象作为参数,需要使用FutureTask类进行包装一下,将FutureTask对象作为参数传给Thread。
- FutureTask
futureTask = new FutureTask<>(callable); - Thread t = new Thread(futureTask);
- t.start();
- System.out.println(futureTask.get());
- }
- }
✨我们这里来理解一下FutureTask类的作用。
我们去餐馆吃饭,在我们将菜点了之后,服务员给后厨大厨一张小票,也给我们一张小票。让后厨大厨根据小票上的要求制作,让我们通过小票去领我们自己的饭。我们使用的FutureTask就相当于一个小票,我们此时将futureTask传给t线程,就相当于大厨通过小票知道他要怎样做。我们通过futureTask.get()获取计算出来的结果,也就是我们的饭。
❓❓❓在上述的代码中,执行任务在t线程,而获取任务执行结果在主线程,这怎么能够确定多线程执行时,t线程一定在主线程之前结束??
❗❗❗我们在主线程中futureTask调用get方法,这个get方法,就有相当于join的作用,他会阻塞等待t线程执行完毕,再去执行主线程中的get方法。
✨总结Callable
- Callable和Runnable相对,都是描述一个"任务"。Callable描述的是带有返回值的任务,Runnable描述的是不带返回值的任务。
- Callable通常需要搭配FutureTask来使用。FutureTask用来保存Callable的返回值结果,因为Callable往往是在另一个线程中执行的,啥时候执行完并不确定。
- FutureTask就可以负责这个等待结果出来的工作。
1.2、ReentrantLock可重入互斥锁
ReentranLock这是锁的另一种实现方式,和synchronized定位类似,都是用来实现互斥效果,保证线程安全。
✨ReentrantLock的用法:
- lock():加锁,如果获取不到锁就死等。
- trylock(超时时间):加锁,如果获取不到锁,等待一定的时间之后就会放弃加锁。
- unlock():解锁
1.2.1、ReentrantLock和synchronized的区别
- synchronized是一个关键字,是JVM内部实现的(大概率是基于C++实现),ReentranLock是标准库中的一个类,在JVM外实现的(基于Java实现)
- synchronized使用时不需要手动释放锁,ReentrantLock使用时需要手动释放,使用起来更灵活,但是也容易遗漏unlock
- synchronized在申请锁的失败时,会死等。ReentrantLock可以通过trylock的方式等待一段时间就放弃。(让程序员更灵活的决定接下来咋做)
- synchronized是非公平锁,ReentrantLock默认是非公平锁,但是它提供了公平和非公平两种工作模式,可以通过构造方法传入一个true开启公平锁模式。
- 更强大的唤醒机制,synchronized是通过Object的wait/notify实现等待-唤醒,每次唤醒的是一个随机等待的线程,ReentrantLock搭配Condition类实现等待-唤醒。Condition这个类也能起到等待通知的效果,可以更精确控制唤醒某个指定的线程。
1.2.2、如何选择使用哪个锁
- 锁竞争不激烈的时候,使用synchronized,效率更高,自动释放更方便。
- 锁竞争激烈的时候,使用ReentrantLock,搭配trylock更灵活的控制加锁的行为,而不是死等。
- 如果需要使用公平锁,使用ReentrantLock.
1.3、Semaphore信号量
信号量:用来表示"可用资源的个数"。本质上就是一个计数器。
✨理解信号量
- 可以把信号量想象成是停车场的展示牌:当前有车位100个,表示有100个可用资源。
- 当有车开进去的时候,就相当于申请一个可用资源,可用车位就-1(这个称为信号量的P操作)
- 当有车开出来的时候,就相当于释放一个可用资源,可用车位就+1(这个称为信号量的V操作)
- 如果计数器的值已经为0了,还尝试申请资源,就会阻塞等待,直到其他线程释放资源。
Semaphore的PV操作中的加减计数器操作都是原子的,可以在多线程环境下直接使用。
- 我们所说的锁,本质上是计数器为1的信号量,可用资源只有做一个,取值只有1和0两种,也叫做二元信号量。 一个线程获取到锁,这个时候信号量为0,只有等到线程将该锁释放掉,这个时候信号量为1,其他线程才能获取到锁。
- 我们可以认为信号量是更广义的锁,他不仅能管理锁,这中非0即1的资源;也能管理多个资源。
1.4、CountDownLatch
- 同时等待N个任务执行结束。
- 就好比跑步比赛,6个选手依次就位,发令枪一响,就表示开始,当最后一个人冲过终点,才能公布成绩。
✨将上面的情况可以使用多线程的思路进行描述
- 主线程,创建10个线程。主线程创建一个CountDownLatch对象,构造方法参数写10(表示10个参赛选手),10个线程分别完成各自的任务。
- 主线程使用CountDownLatch.await方法,来阻塞等待所有线程都执行完任务。
- 10个线程每个线程执行完,都会调用一个CountDownLatch.countDown方法(表示选手到达终点)
- 10个线程在调用countDown方法时,主线程调用的await方法会记录有几个线程调用了countDown方法(就相当于,裁判员在记录有几个选手已经过线了),当这10个线程都调用过countDown方法之后,此时主线程的await就会阻塞接触,接下来就可以进行后续工作了。
2、线程安全的集合类
我们在数据结构中说到的ArrayList、LinkedList、HashMap、PriorityQueue都是线程不安全的集合类。在多线程环境下使用,有可能会出现问题。
这些数据结构多线程不安全,但是还要使用,该做怎样的处理呢?
2.1、多线程环境使用ArrayList
1️⃣最直接的方法,就是使用锁(synchronized或ReentrantLock),手动保证.
多个线程去修改ArrayList此时就可能有问题,就可以给修改操作进行加锁。
2️⃣、可以使用Vector类来代替ArrayList类。
Vector类中的关键方法都是带有synchronized的,这样可以保证在多线程环境下,这个类是安全的。但是Java官方明确表示,将Vector这个类标记为不建议使用的类。
3️⃣、 使用collections.synchronizedList(new list集合类)
- collections.synchronizedList它就相当于一个外壳,将我们想要使用的list集合类,放在它里面,让list集合类当中的关键操作都带上synchronized。
- synchronizedList是标准库提供的一个基于synchronized进行线程同步的List.
- synchronizedList的关键操作上都带有synchronized
4️⃣、 使用CopyOnWriteArrayList(支持"写时拷贝"的集合类)
CopyOnWrite容器即写时复制的容器。
- 当我们往一个容器里添加元素的时候,不直接往当前容器中添加,而是先将当前容器进行Copy,复制出一个新的容器,然后往新的容器里添加元素。
- 添加完元素之后,在将原容器的引用指向新的容器。(引用的赋值操作,本身就是原子的)
所以CopyOnWrite容器也是一种读写分离的思想,读和写是不同的容器。
多线程读ArrayList是,此时没有线程安全的问题,但是当一些线程读,一些线程修改的时候,就会出现线程安全问题,但是使用CopyOnWriteArrayList,就不会产生线程安全问题了,读和写相互不影响。
- 优点:这样做的好处就是,修改的同时对于读操作,是没有任何影响的,读的时候就会读取原来的旧数据,不会出现,读一个带有"修改了一半"的中间版本,也就是说适合于读多写少的情况,也适合数据小的情况,在我们日常配置数据的时候,经常就会用到这类操作。这种策略也叫做"双缓冲区策略"。就像我们在打游戏的时候,显卡就是采用的这种方式,显示器在读前一帧的画面的时候,显卡在画下一帧的画面。读的时候,在旧的集合中读,写的时候在新的集合中写,两种不会产生影响。
- 缺点:占用内存较多,新写的数据不能第一时间读取到。
2.2、多线程使用队列
我们之前说过的BlockingQueue就是线程安全的,在之前线程池的博客中已经说到了,这里就不过多说明了。
2.3、多线程使用哈希表
HashMap本身不是线程安全的。
🧨在多线程环境下使用哈希表可以使用:
1️⃣HashTable(虽然线程安全,但是不建议使用)
HashTable只是简单的把关键方法加上了synchronized关键字。
2️⃣ConcurrentHashMap(建议使用)
2.3.1、HashTable和ConcurrentHashMap的区别
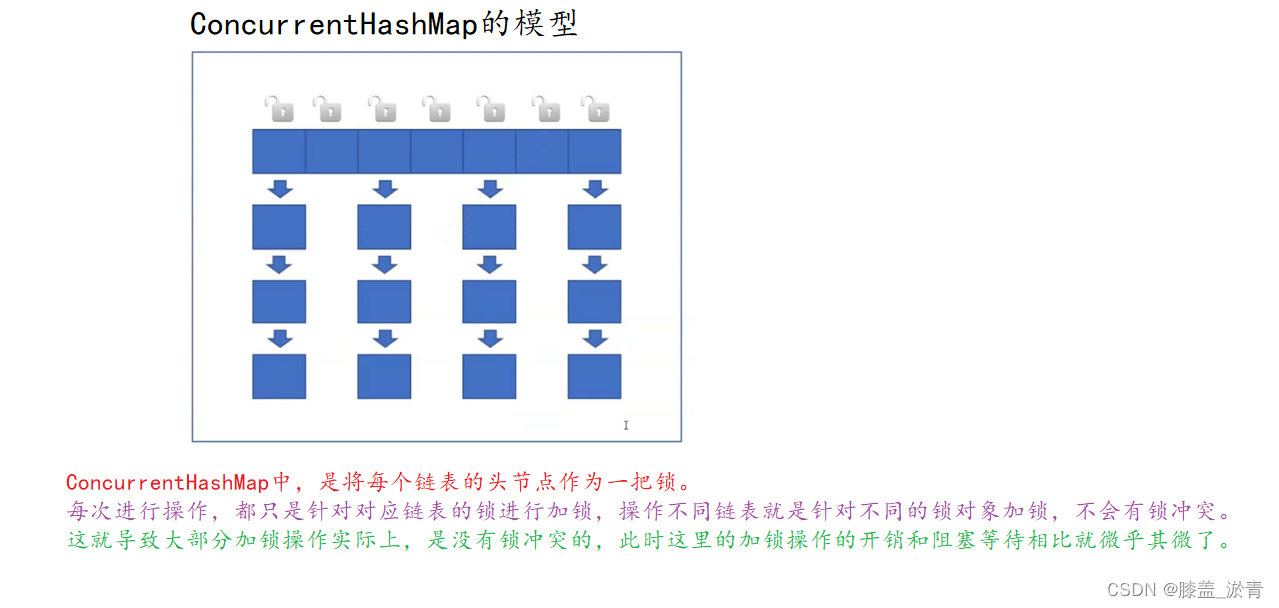
1️⃣加锁粒度的不同(触发锁冲突的频率)
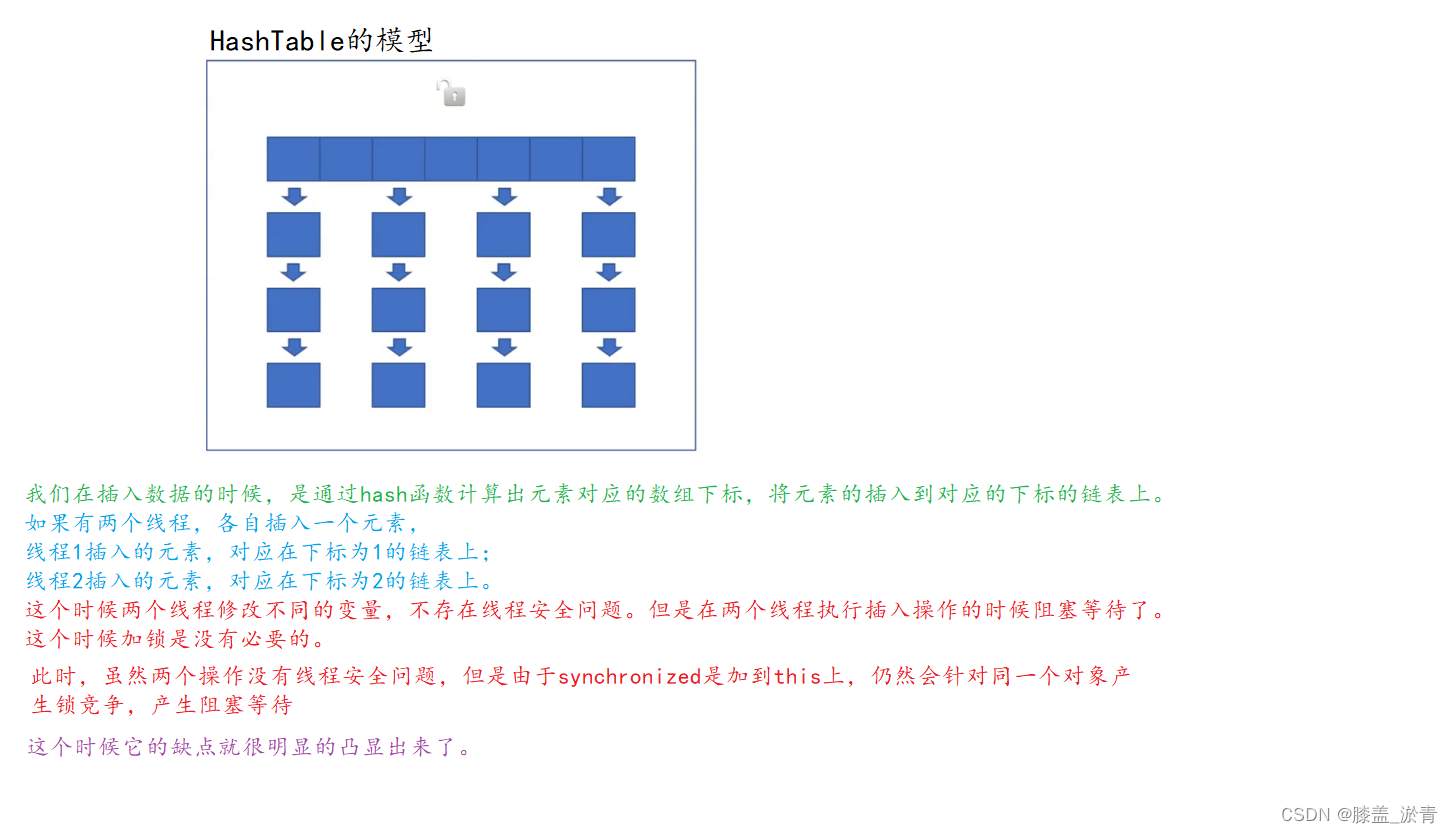
HashTable是针对整个哈希表加锁,任何的增删改查操作,都会触发加锁,也就都会可能有锁竞争。
🎉我们通过下面的场景来展现HashTable出现的问题。
🎉此时我们通过下面的场景来展现ConcurrentHashMap在遇到与HashTable相同的问题时,它的处理方式,以及优点。
📕补充:
上述情况是从Java1.8开始的,在Java1.7及其之前,ConcurrentHashMap使用"分段锁",目的和上述类似,相当于是好几个链表共用一把锁(这个设定,不科学,效率不够高,代码写起来也比较麻烦)
2️⃣ConcurrentHashMap更充分的利用了CAS机制(无锁编程),比如获取或更新元素个数,就可以直接使用CAS完成,不必加锁。
3️⃣优化了扩容策略
🎉对于HashTable,如果元素太多,就会涉及到扩容,扩容需要重新申请内存空间,搬运元素(把元素从旧的哈希表上删除,插入到新的哈希表上)。如果旧的HashTable中的元素非常多,搬运一次,成本就很高。刚好给HashTable中插入(put)元素的时候,负载因子超过了阈值,一次性搬运全部数据就会导致put操作非常的卡顿。
🎉对于ConcurrentHashMap扩容的策略,是化整为零,它不会试图依次性的把所有的元素都搬运到新表当中去,而是每次搬运一部分。
- 当put触发扩容,此时就会直接创建更大的内存空间,但是并不会直接把所有元素都搬运过去,而是值搬运一小部分,这个时候的搬运速度就会比较快。
- 此时就相当于存在两份hash表了,此时插入元素操作,就会直接往新表中插入元素;删除元素,就会删除旧表当中的元素;查找元素,就会新表和旧表一起都查。并且每次操作过程中,都搬运一部分元素,直至最后搬运完成。
-
相关阅读:
Linux aarch64交叉编译之 weston窗口管理程序
如何 build 一个 mysql_client 镜像
【无题】仙女话术
【算法篇】四种链表总结完毕,顺手刷了两道面试题紧张的羊
ElasticSearch(四):ES nested嵌套文档与父子文档处理
数据结构与算法:数据结构基础
【linux】Could not update ICEauthority file /home/xxx/.ICEauthority问题解决
9.17-数值分析
No module named ‘importlib.metadata‘
算法与数据结构【30天】集训营——线性表之链式表的表示与实现及顺表与链表比较(04)
- 原文地址:https://blog.csdn.net/m0_73067372/article/details/130900673
