在多线程环境下,为了保证数据的线程安全,锁保证同一时刻,只有一个可以访问和更新共享数据。在单机系统我们可以使用synchronized锁或者Lock锁保证线程安全。synchronized锁是Java提供的一种内置锁,在单个JVM进程中提供线程之间的锁定机制,控制多线程并发。只适用于单机环境下的并发控制:

但是如果想要锁定多个节点服务,synchronized就不适用于了:
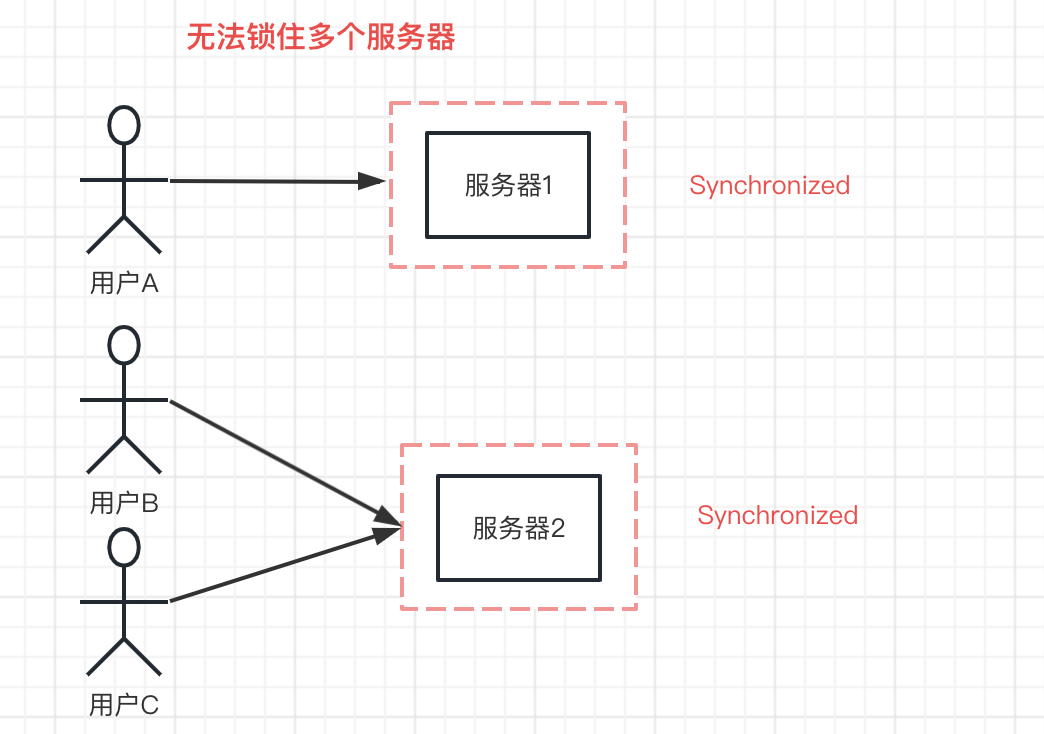
想要在多个节点中提供锁定,在分布式系统并发控制共享资源,确保同一时刻只有一个访问可以调用,避免多个调用者竞争调用和数据不一致问题,保证数据的一致性。
分布式锁就是控制分布式系统不同进程访问共享资源的一种锁的机制。不同进程之间调用需要保持互斥性,任意时刻,只有一个客户端能持有锁。
从单体锁到分布式锁,只不过是将锁的对象从一个进程的多个线程,转成多个进程。
共享资源包含:
- 数据库
- 文件硬盘
- 共享内存
实现思路
分布式锁的加锁和解锁是使用不同的数值来表示不同的状态,比如0表示空闲状态。
-
加锁
- 加锁时,判断锁是否空闲,如果空闲,修改状态为
1表示已加锁,返回成功。 - 如果不为空闲状态
0,则返回失败,表示没有获取到锁。
- 加锁时,判断锁是否空闲,如果空闲,修改状态为
-
解锁
- 将锁状态修改为空闲状态
0。
- 将锁状态修改为空闲状态
以上的加锁和解锁操作,都要保证是一个原子操作。
分布式锁特性
1. 互斥性
分布式锁最基本的特性,同一时刻只能一个节点服务拥有该锁,当有节点获取锁之后,其他节点无法获取锁,不同节点之间具有互斥性。
2. 超时机制
不考虑异常,正常情况下,请求获取锁之后,处理任务,处理完成之后释放锁。但是如果在处理任务发生服务异常,或者网络异常时,导致锁无法释放。其他请求都无法获取锁,变成死锁。
为了防止锁变成死锁,需要设置锁的超时时间。过了超时时间后,锁自动释放,其他请求能正常获取锁。
3. 自动续期
锁设置了超时机制后,如果持有锁的节点处理任务的时候过长超过了超时时间,就会发生线程未处理完任务锁就被释放了,其他线程就能获取到该锁,导致多个节点同时访问共享资源。对此,就需要延长超时时间。
开启一个监听线程,定时监听任务,监听任务线程还存活就延长超时时间。当任务完成、或者任务发生异常就不继续延长超时时间。
分布式实现
分布式主要有三种实现:
- 数据库
- Zookeeper
- Redis
通过模拟客户下单操作。
- 先判断库存是否充足
- 如果充足,先扣库存,再新增订单。
- 如果不足就提示库存不够。

先创建订单表和商品库存表:
--库存表--
create table t_product(
`id` bigint(20) not null auto_increment,
`name` varchar(64) not null comment "商品名",
`store` int default 0 comment "库存",
primary key(`id`)
)
insert into `t_product` values (1, '红米手机', 100);
-- 订单表 --
create table t_order(
`id` bigint(20) not null auto_increment,
`sn` varchar(64) not null comment '订单号',
`num` int default null comment '数量',
`price` int default null comment '单价',
`product_id` bigint default null comment '商品id',
`create_time` timestamp not null default CURRENT_TIMESTAMP comment '创建时间',
primary key(`id`)
)
为了查询时防止幻读,我们还需要保证查询和插入是在同一个事务中。下单先判断是否有库存,有库存就减库存1,再新增订单。主要代码如下:
@Transactional
public void addOrder(Order order) throws Exception {
Product product = productDao.selectById(order.getProductId());
int store = product.getStore() - 1;
if (store >= 0) {
// 扣库存
product.setStore(store);
productDao.updateByPrimaryKey(product);
// 添加订单
orderDao.insert(order);
} else {
throw new Exception("哎呦喂,库存不足");
}
}
其中查询库存方法productDao.selectById的SQL语句是:
select id,name,store from t_product where id = xxx
使用压测工具apache ab开启多个线程,请求50次:
ab -n 10 -c 2 http://127.0.0.1:8080/xxxx
压测结果:
库存剩余:72,订单数量:50
**新增了 50 条订单,库存只扣了 28 **。
这是因为在并发环境下,多个线程下单操作,前面的线程还未更新库存,后面的线程已经请求进来,并获取到了未更新的库存,后续扣减库存都不是扣减最近的库存。线程越多,扣减的库存越少。这就是在高并发场景下发生的超卖问题。
1. 数据库实现分布式锁
Mysql数据库可以使用select xxx for update来实现分布式锁。
for update是一种行级锁,也叫排它锁。如果一条select语句后面加上for update,其他事务可以读取,但不能进进行更新操作。
将上面查询库存productDao.selectById方法的SQL语句后面加上for update:
select id,name,store from t_product where id = xxx for update
再使用apache ab开启多个线程,请求50次:
ab -n 10 -c 2 http://127.0.0.1:8080/xxxx
压测结果:
库存剩余:50,订单数量:50
数据库成功实现分布式锁
使用for update行级锁可以实现分布式锁,通过行级锁锁住库存,where后条件一定要走索引,不然会触发表锁,会降低MySQL的性能。
不过基于MySQL实现的分布式锁,存在性能瓶颈,在Repeatable read隔离级别下select for update操作是基于间隙锁锁实现,这是一种悲观锁,会存在线程阻塞问题。
当有大量的线程请求的情况下,大部分请求会被阻塞等待,后续的请求只能等前面的请求结束后,才能排队进来处理。
Zookeeper 实现分布式锁
数据库实现分布式锁存在性能瓶颈,无法支撑高并发的请求。可以使用Zookeeper实现分布式锁,Zookeeper提供一种分布式服务协调的中心化服务,而分布式锁的实现是基于Zookeeper的两个特性。
顺序临时节点:
Zookeeper 数据模型znode是以多层节点命名的空间,每个节点都用斜杠/分开的路径来表示,类似文件系统的目录。
节点类型分成持久节点和临时节点,每个节点还可以标记有序性。一旦节点被标记为有序性,那整个节点就有自动递增的特点。利用以上的特性,创建一个持久节点作为父节点,在父节点下面创建一个临时节点,并标记该临时节点为有序性。
Watch 机制:
Zookeeper 还提供了另一个重要的特性:Watch(事件监听器),在指定节点的上注册监听事件。当事件触发时,会将事件通知给对应的客户。
了解了Zookeeper的两个特性之后,那如何使用这两种特性来实现分布式锁呢?
首先,创建一个持久类型的父节点,当用户请求时,就在父节点创建临时类型的子节点,并标记临时节点为有序性。
建立子节点之后,对父节点下面所有临时节点进行排序,判断刚创建的临时节点是否是最小的节点,如果是最小的节点,就获取锁。如果不最小的节点,则等待锁,并且获取该节点上一个顺序节点,并为其注册监听事件,等待触发事件并获得锁。
当请求完毕后,删除该节点,并触发监听事件,下一个顺序节点获得锁,流程如下所示:

curator将上面实现分布式锁的思路封装好了,直接调用即可。
引入curator依赖:
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>4.3.0version>
dependency>
使用InterProcessMutex分布式可重入排它锁,一般流程如下:
InterProcessMutex lock = new InterProcessMutex(client, lockPath);
// 加锁
interProcessMutex.acquire();
// 执行代码xxxxxxx
// 解锁
interProcessMutex.release();
为了避免每次请求都要创建InterProcessMutex实例,创建InterProcessMutex的bean:
private String address = "xxxxx";
@Bean
public InterProcessMutex interProcessMutex() {
CuratorFramework zkClient = getZkClient();
String lockPath = "/lock";
InterProcessMutex lock = new InterProcessMutex(zkClient,lockPath);
return lock;
}
private CuratorFramework getZkClient() {
ExponentialBackoffRetry retry = new ExponentialBackoffRetry(1000,3,5000);
CuratorFramework zkClient = CuratorFrameworkFactory.builder()
.connectString(address)
.sessionTimeoutMs(5000)
.connectionTimeoutMs(5000)
.retryPolicy(retry).build();
zkClient.start();
return zkClient;
}
在高并发场景下,多个用户请求系统,并获取临时节点顺序:

使用interProcessMutex获取锁和释放锁:
- 获取锁
interProcessMutex.acquire() - 释放锁
interProcessMutex.release()
请求接口如下:
@RestController
public class Controller {
@Autowired
private InterProcessMutex interProcessMutex;
@GetMapping("/sec-kill")
public String secKill() throws Exception {
// 获取锁
interProcessMutex.acquire();
// 扣减库存,创建订单等操作....
interProcessMutex.release();
return "ok";
}
}
如果获取锁之后,系统发生异常,系统就一直持有锁,后续请求也无法获取锁,导致死锁。需要设置锁超时机制,interProcessMutex.acquire添加超时时间:
interProcessMutex.acquire(watiTime,TimeUnit);
超时时间设置要根据业务执行时间来设定,不能太长,也不能太短。
Zookeeper一些特点
Zookeeper实现的分布式锁,相对数据库,性能有很大的提高。Zookeeper配置集群,发生单点故障时、或者系统挂掉时,临时节点会因为 session 连接断开而自动删除。- 频繁的创建和删除节点,并且每个节点都有
watch事件,对Zookeeper服务来说压力大。相对Redis的性能,还存在差距。
3. Redis 实现分布式锁
Redis 实现分布式锁,是最复杂的,但是也是性能最高的。
- 加锁:
SETNX key value如果键不存在时,对键设值,返回1。如果键存在,不做任何操作,返回0。setnx全称是set if not exist。 - 解锁:
DEL key,通过删除key释放锁,删除键之后,其他线程可以争夺锁。
Redis也需要考虑超时问题,一般都是用SETNX + EXPIRE组合来实现超时设置,伪代码如下:
pubic boolean lock(Jedis jedis,String key,String value,long expireTime) {
long flag = jedis.setnx(key,value);
// 成功获取锁
if(flag) {
// 如果这里突然崩溃,无法设置过期时间,将发生死锁
jedis.expirt(key,expireTime);
return true;
}
return false;
}
通过setnx方法获取锁,如果key存在,就返回失败。如果不存在,就设值成功,设值成功之后,再通过expirt设置超时时间。
如果在设置超时时间和设置锁之间出现系统崩溃,此时没有给锁设置过期时间,将会出现死锁问题。
在Redis 2.6.12版本后SETNX增加了过期时间参数:
pubic boolean lock(Jedis jedis,String key,String value,long expireTime) {
long flag = jedis.setnx(key,value,expireTime);
// 成功获取锁
if(flag) {
return true;
}
return false;
}
解锁,需要删除键值即可,其他线程就能竞争锁了:
pubic void lock(Jedis jedis,String key) {
jedis.del(key);
}
一般请求controlle如下:
@RestController
public class Controller {
@Autowired
private InterProcessMutex interProcessMutex;
@GetMapping("/sec-kill")
public String secKill() throws Exception {
// 获取锁
lock();
// 扣减库存,创建订单等操作....
unLock();
return "ok";
}
}
Redis设置了超时时间后,就解决死锁的问题,但也会引发其他问题。
如果设置的超时时间比较短,而业务执行的时间比较长。比如超时时间设置5s,而业务执行需要10s,此时业务还未执行完,其他请求就会获取到锁,两个请求同时请求业务数据,不满足分布式锁的互斥性,无法保证线程的安全,如下流程所示:

超时解锁导致并发:
用户A先获取锁,还未执行完业务代码,此时已经过了超时时间,锁被释放。用户B获取到锁,此时用户A和用户B并发执行业务数据,
锁误删除:
用户A执行完业务代码后,执行释放锁操作,而此时用户A已经被超时释放,锁被用户B持有,此时释放锁,就把用户B的锁误删了。
解决方案:
首先要将超时时间设置的长一些,满足业务执行的时间。如果系统对吞吐量要求比较严格,根据具体的业务的执行时间来设置超时时间,超时时间比业务执行时间长一些,超时时间不能设置太长也不能设置太短。
针对锁误删除的问题。每个线程在获取锁时,设置一个的线程标识,比如UUID,作为唯一的标识,设置value值,在解锁时,先判断是是否是自己线程的标识,如果不是,就不做删除:
pubic void lock(Jedis jedis,String key,String value) {
if (jedis.get(key).equals(value)) {
jedis.del(key);
}
}
除了设置合理超时时间外,可能还有偶尔几个线程执行业务代码,因为网络环境执行时间变长。这时候就需要再加一个线程,定时执行,自动续期锁。
4.Redission 分布式锁
Redis虽然作为分布式锁来说,性能是最好的。但是也是最复杂的,上面总结Redis主要有下面几个问题:
- 死锁
- 设置超时后
- 锁误删
- 业务还继续执行,导致多个线程并发执行
线上都是用Redission实现分布式锁,Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。Redisson是基于netty通信框架实现的,所以支持非阻塞通信,性能优于Jedis。
Redisson分布式锁四层保护:
- 防死锁
- 防误删
- 可重入
- 自动续期
Redisson实现Redis分布式锁,支持单机和集群模式,
引入maven依赖:
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.8.2version>
dependency>
添加Redission配置:
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
// 单机模式
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379")
.setPassword("xxxx");
// 集群模式
/*config.useClusterServers()
.setScanInterval(2000) // 集群状态扫描间隔时间,单位是毫秒
//可以用"rediss://"来启用SSL连接
.addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001")
.addNodeAddress("redis://127.0.0.1:7002");*/
return Redisson.create(config);
}
}
使用Redission分布式锁,分成三个步骤:
- 获取锁
redissonClient.getLock("lock") - 加锁
rLock.lock() - 解锁
rLock.unlock()
请求controlle示例如下:
@RestController
public class Controller {
@Autowired
private RedissonClient redissonClient;
@GetMapping("/sec-kill")
public String secKill() throws Exception {
// 获取锁
RLock rLock = redissonClient.getLock("lock");
// 加锁
rLock.lock();
// 执行业务数据
// 解锁
rLock.unlock();
return "ok";
}
}
Redission实现的分布式锁,直接调用,不需要锁异常、超时并发、锁删除等问题,它把处理上面的问题的代码都封装好了,直接调用即可。
Redlock 算法
在单机模式下,Redis发生单机故障,Redis master宕机了该怎么办?是否将锁转移到slave呢?答案是不行的,因为Redis复制是异步的,无法满足锁互斥性。
Redlock算法可以解决上面的问题,在集群模式下,Redission 使用Redlock算法,使用单机实例的方式顺序获取集群下的锁。如果请求超时,则认定该节点不可用。当获取锁的实例数超过半数时,则获取锁成功。如果获取锁失败,即没有获取超过半数的实例,那么久释放所有节点的锁。
Watch dog 看门狗机制
Redission通过看门狗的实现自动续期的功能,当分布式锁获取到锁后,对应的Redis宕机了,会出现死锁的状态,为避免出现这种状态,锁一般会设置一个过期时间。默认是30s,超过30s后,会自动释放锁。
Redission实例被关闭之前,不断的延长锁的有效期,拿到线程的锁如果没有完成业务操作,那么看门狗会一直延长锁的超时时间。默认情况下,每10s延长一次超时时间,续期时间是30s,可以通过Config.lockWatchdogTimeout来设定。

Redisson还提供了可以指定leaseTime参数的加锁方法来指定加锁的时间。超过这个时间后锁便自动解开了,不会延长锁的有效期。
总结
- 分布式锁是由于单机锁无法满足分布式系统锁,在分布式环境下,需要分布式锁来控制共享内容,保证线程的安全。
- 分布式满足几个特性
- 互斥性
- 超时释放锁
- 自动续期
- 分布式锁实现方式
Mysql使用排它锁,select xxxx for update。实现比较简单,但是数据库无法支撑大量请求访问,性能较差。Zookeeper先创建一个持久类型的节点,当多个线程请求时,在持久类型节点创建顺序临时节点,先判断自己是否是最小节点,如果是持有锁,执行后续逻辑,如果不是就找到上一个顺序节点,并添加watch监听事件。线程处理结束后。触发监听事件,通知下一个节点获取锁。Zookeeper性能优于数据库,但是频繁的创建、删除节点并且创建watch监听,对服务器的压力也大。- 使用
Redis实现分布式锁性能是最优,也是最复杂的。SETNX key value获取锁,如果key存在,则成功获取锁,否则获取锁失败。使用del删除节点释放锁。复杂在于需要平衡超时时间和锁续期。不设置超时时间,会发生死锁。设置了超时时间就可能出现业务处理时间大于超时时间,出现多个锁同时访问共享数据,以及锁误删的情况。解决方案是根据具体的业务时间设置合理的超时时间,锁误删的话要给每个线程设置一个唯一的id。此外,如果业务时间大于超时时间,开启线程定时续约时间。 - 针对
Redis实现分布式锁存在的问题Redisson提供了解决方案,Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid),Redisson是基于netty通信框架实现的,所以支持非阻塞通信,性能也比较高。Redisson有四种特性防死锁、防误删、可重入、自动续期。支持单机和集群模式。自动续期是使用watch dog看门狗机制,在实例关闭前,不断地延长锁的有效期。默认10s延迟一次,延长时间为30s。