-
深度学习图像增强和模型微调
1 神经网络拟合复杂函数
大自然总是变化莫测,小蓝所在海底的生物们也经历了巨大的进化,豆豆的毒性与大小关系变得不再那么的简单,想要预测他们,只能靠一些不那么单调的函数:
机器学习的局限性


那么如何预测模型能够产生这种像山丘一样的曲线呢?是时候让神经元形成一个网络了!

一般地我们让网络结构图更加简洁,会省略调偏置项b:

不过为了更好的学习,我们这里加上偏置项b,对于第一层第一个神经元:
我们先通过线性函数计算:

再通过激活函数输出,利用梯度下降算法函数图像一定会变成这个样子:

对于第一层第二个神经元也可以获得:

把这两个神经元的输出作为第二层第一个神经元的输入:
先通过线性函数乘以权重计算:

再通过激活函数并通过梯度下降算法把最终的输出调节成这样:

整个参数调节的过程:

我们添加了一个神经元后相当于增加了一个抽象的维度,把输入放到不同的维度中,每个维度通过不断的调整权重并激活,从而产生对输入的不同理解,最后再把这些抽象维度中的输出合并降维得到输出。2 隐藏层介绍
而我们中间新添加的神经元节点也称之为“隐藏层”
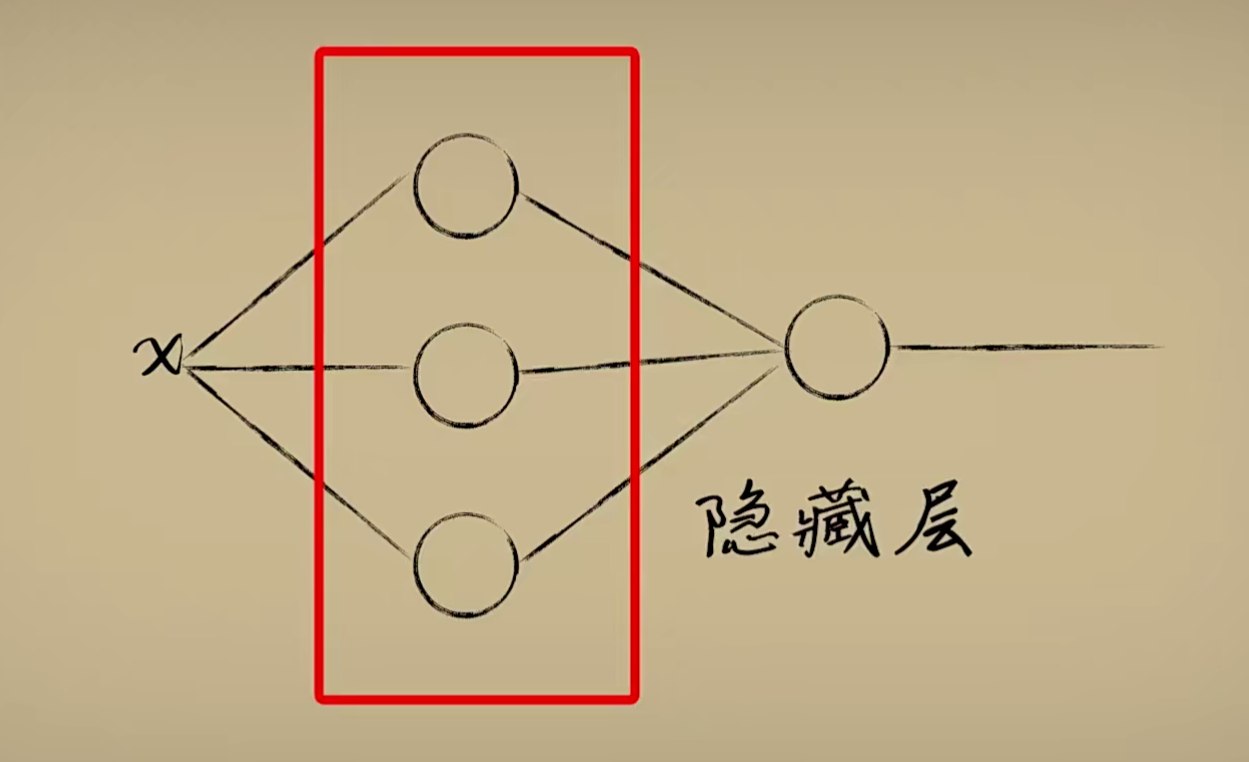
当我们建立一个复杂程度恰当的神经网络,经过充分的训练后,网络中各个神经元的参数调节被调节成不同值,这些功能单一的神经元联结组合出来的整体就可以近似出一个相当复杂的函数:

而机器学习神经网络的根基是
海量数据,因为越是充足的数据,就越大程度上蕴藏了问题的规律特征,新的问题数据也就越难以逃脱这些规律的约束。

一个训练之后拟合适当的模型进而遇到在遇到新的问题数据的时候也能大概率产生正确的预测,我们把这个现象称之为模型的“泛化”。

深度学习网络中的“深度”其实没有什么奥义,只是指一个神经网络中纵向的隐藏层比较多,通俗的讲:“很深”!但是隐藏层在理解什么,在提取什么都太过微妙,虽然我们对大致结果都有所把握,但却很难用精准的数学去进行描述,我们能过也只有设计一个网络。

所以很多人戏称深度学习是“炼丹”:

3 代码实现
我们对上述过程代码实现:豆豆数据集模拟:
dataset.pyimport numpy as np def get_beans(counts): xs = np.random.rand(counts)*2 xs = np.sort(xs) ys = np.zeros(counts) for i in range(counts): x = xs[i] yi = 0.7*x+(0.5-np.random.rand())/50+0.5 if yi > 0.8 and yi < 1.4: ys[i] = 1 return xs,ys- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
豆豆毒性分布如下:

梯度下降:one_hidden_layer_net.pyimport dataset import matplotlib.pyplot as plt import numpy as np # 豆豆数量m m = 100 xs, ys = dataset.get_beans(m) # 配置图像 plt.title("Size-Toxicity Function", fontsize=12) plt.xlabel("Bean Size") plt.ylabel("Toxicity") plt.scatter(xs, ys) def sigmoid(x): return 1 / (1 + np.exp(-x)) # 第一层 # 第一个神经元 # 第几个神经元在第几个输入_第几层 w11_1 = np.random.rand() b1_1 = np.random.rand() # 第二个神经元 w12_1 = np.random.rand() b2_1 = np.random.rand() # 第二层 w11_2 = np.random.rand() w21_2 = np.random.rand() b1_2 = np.random.rand() # 前向传播 def forward_propgation(xs): z1_1 = w11_1 * xs + b1_1 a1_1 = sigmoid(z1_1) z2_1 = w12_1 * xs + b2_1 a2_1 = sigmoid(z2_1) z1_2 = w11_2 * a1_1 + w21_2 * a2_1 + b1_2 a1_2 = sigmoid(z1_2) return a1_2, z1_2, a2_1, z2_1, a1_1, z1_1 a1_2, z1_2, a2_1, z2_1, a1_1, z1_1 = forward_propgation(xs) plt.plot(xs, a1_2) plt.show() # 训练5000次 for _ in range(5000): for i in range(100): x = xs[i] y = ys[i] # 先来一次前向传播 a1_2, z1_2, a2_1, z2_1, a1_1, z1_1 = forward_propgation(x) # 反向传播 # 误差代价e e = (y - a1_2) ** 2 #### deda1_2 = -2 * (y - a1_2) da1_2dz1_2 = a1_2 * (1 - a1_2) dz1_2dw11_2 = a1_1 dz1_2dw21_2 = a2_1 dedw11_2 = deda1_2 * da1_2dz1_2 * dz1_2dw11_2 dedw21_2 = deda1_2 * da1_2dz1_2 * dz1_2dw21_2 dz1_2db1_2 = 1 dedb1_2 = deda1_2 * da1_2dz1_2 * dz1_2db1_2 #### dz1_2da1_1 = w11_2 da1_1dz1_1 = a1_1 * (1 - a1_1) dz1_1dw11_1 = x dedw11_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1 * da1_1dz1_1 * dz1_1dw11_1 dz1_1db1_1 = 1 dedb1_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1 * da1_1dz1_1 * dz1_1db1_1 dz1_2da2_1 = w21_2 da2_1dz2_1 = a2_1 * (1 - a2_1) dz2_1dw12_1 = x dedw12_1 = deda1_2 * da1_2dz1_2 * dz1_2da2_1 * da2_1dz2_1 * dz2_1dw12_1 dz2_1db2_1 = 1 dedb2_1 = deda1_2 * da1_2dz1_2 * dz1_2da2_1 * da2_1dz2_1 * dz2_1db2_1 # alpha为学习率 alpha = 0.03 w11_2 = w11_2 - alpha * dedw11_2 w21_2 = w21_2 - alpha * dedw21_2 b1_2 = b1_2 - alpha * dedb1_2 w12_1 = w12_1 - alpha * dedw12_1 b2_1 = b2_1 - alpha * dedb2_1 w11_1 = w11_1 - alpha * dedw11_1 b1_1 = b1_1 - alpha * dedb1_1 if _ % 100 == 0: # 绘制动态 plt.clf() ## 清空窗口 plt.scatter(xs, ys) a1_2, z1_2, a2_1, z2_1, a1_1, z1_1 = forward_propgation(xs) plt.plot(xs, a1_2) plt.pause(0.01) # 暂停0.01秒- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114

-
相关阅读:
【黑马云盘 Debug】ASSERT: “i >= 0 && i < size()“
Vue-CLI项目搭建
wireshark 流量抓包例题
RibbitMQ学习笔记延迟队列
金融市场,资产管理与投资基金
Redis key(BigKey、MoreKey)的存储策略
数据库系统原理与应用教程(071)—— MySQL 练习题:操作题 110-120(十五):综合练习
类与面向对象
RabbitMQ相关概念
算法--搜索与图
- 原文地址:https://blog.csdn.net/ZGL_cyy/article/details/128211388