-
关于海量级存储用户标签体系架构
项目场景:
对于我们运营来说,需要给用户打上不同的身份标签。比如用户是否偏重,身高范围,是不是我们的会员。。。等等一些标签。
比如我们有100W用户。我们需要来给100W用户打上接近200个不同身份的标签应该如何去做?
设计方式
- 这里对于mysql表的设计我们有两种方式
-
一是采用新增列的方式来新增用户身份。一对一存储,但是这种存在的弊端是我们在新增用户身份时,每次都需要手动新增一列。来保存用户新的身份。而且有多少身份就需要多少列,对于mysql的性能会急剧降低。尽管我们可以进行垂直拆分来增加性能。但也会让mysql更难维护。以及扩展性变的很差。
-
二是采用一对多的形式来存储用户身份。表结构如下
ID 标签tag 标签描述 状态 1 is_vip 是否是VIP用户 1 2 is_male 是否是男性 1 3 bmi_is_ok bmi是否正常 1 ID uid 身份标签ID 状态 1 1 1 1 1 2 2 1 1 3 3 1 这样子做我们在新增身份的时候,就能灵活库扩展,在标签表新增之后,我们再按照指定的逻辑去给用户洗上标签。
如何在判断用户标签的时候实现低延时查询判断?
我们建立好标签之后是拿来用的,在业务逻辑代码中,我们经常会判断用户是否是属于某一种身份标签。以此来给用户下发不同的数据。并且在很多的业务逻辑中都有涉及,那么我们需要解决的问题就是如果实时去查询出用户是否属于某一种标签身份。
如果按照我们100W用户 一个用户200种标签的设想。那么我们表数据的存储量级是特别大的,尽管我们考虑了分表的设计。单表1000W数据去做查询也是很慢的。尤其我们很多场景下都需要实时做身份判断。
那么我们将采用redis来作为缓存数据。但是使用redis key value形式将所有用户的身份存储下来那是一个相当庞大的数据量。有没有更好的方式来进行存储呢?
首先我们抽出共性。我们的身份标签值只能为0和1,那么我们是不是可以采用bitmaps的方式来进行用户标签的存储呢?
结合bitmaps特性,我们可以有如下设计
{ // 所有vip用户 "user:is_vip":{ "01001001" }, // 所有男性用户 "user:is_male":{ "01101010" }, // 所有男性用户 "user:male":{ "01010011" }, // 用户1的所有标签 "user:all:1":{ "01101010" }, //用户2的所有标签 "user:all:2":{ "00100001" } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
使用上面的存储结构,我们就能快速的找出某人对应的身份信息。并且内存可控。
那么现在如何解决我们存储进去的问题
前置条件
1 以用户主表ID做为用户ID,且满足排序规则。那么我们可以直接使用用户ID来做为偏移量来判断用户的身份
比如我们要判断uid为3的用户是不是vip
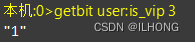
就能快速的或者用户是不是满足当前身份SETBIT GETBIT BITCOUNT 可以实现我们当前身份下有多少个用户满足 BITPOS BITOP BITFIELD 同时 借助以上redis命令我们能实现更多操作。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
SETBIT
设置用户身份

-
BITOP
对身份标签做运算

我们可以借助BITOP来进行身份的交叉运算。以此来快速判断多种身份以及统计结果。 -
GETBIT
获取用户身份

性能测试
setbit user:is_vip 10000000 给第10000000个用户设置是vip的身份(相当于也给前10000000个用户都设置了不是vip的身份)
在redis里面都是毫秒级响应解决方案:
根据上面的分析,我们大致可以确定身份存储的流程,首先我们在标签表新增一种身份,我们按照指定的逻辑来将对应的身份洗进数据库,同时使用bitmaps来存储下来,不设置过期失效,如果有对应身份更新。同步到redis bitmaps。为了保持数据精准性。同时可以设置定时任务来做定时刷新,保持缓存与数据库身份的同步更新。
-
相关阅读:
Ts —— 文件编译有那些配置项
Java面试之封装、继承和多态(简洁易懂版)
【Swin Transformer原理和源码解析】Hierarchical Vision Transformer using Shifted Windows
hive指定字段插入数据,包含了分区表和非分区表
《Linux设备驱动开发详解》之udev用户空间设备管理
FFmpeg常用命令行讲解及实战一
vulnhub之MATRIX-BREAKOUT 2 MORPHEUS
python与自然语言处理3朴素贝叶斯
哪些问题会让企业申报不了高新技术企业?
模拟一个火车站售票小例子
- 原文地址:https://blog.csdn.net/a1034996/article/details/128201837
