-
torchnet简介
前言
最近项目开发过程中遇到了 t o r c h n e t . m e t e r torchnet.meter torchnet.meter来记录模型信息,搜了好多篇博客,都潦草草没有一点干货。于是参考了官方文档以及参考代码,根据自己的理解,在此做了一个其的使用教程:
torchnet简介
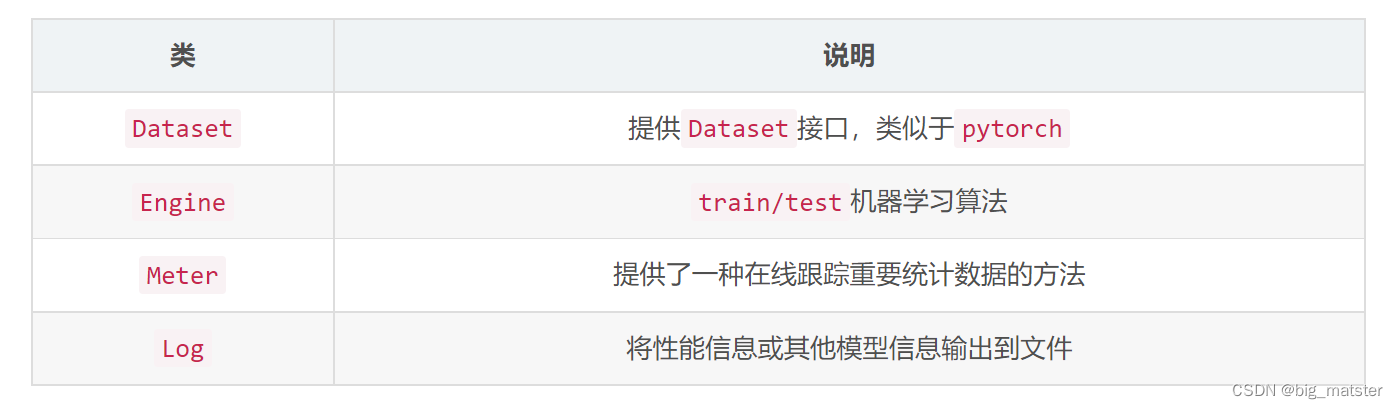
torchent是torch框架的一种,其提供了一套抽象的概念,旨在鼓励代码复用和模块化编程。提供了四个重要的类:
每个meter的子类都有三个方法:

Classification Meters
APMeter
APMeter计算每个类的AP,即平均精度average precision。
import torch from torch.nn import functional as F from torchnet import meter as tnt seed = 1024 torch.manual_seed(seed) # 128条数据, 10个类别 size = (128, 10) output = torch.rand(size=size) output = F.softmax(output, dim=1) target = torch.randint(0, 2, size=size) aper = tnt.APMeter() aper.add(output, target) """ add(output, target, weight=None): output: 模型的输出, 是一个NxK的tensor, 表示每个类别的概率, N表示样本数目, K表示类别数目, 所有类别的概率总和应为1 target: 样本的标签, 是一个NxK的二进制tensor, 即其值只能是0(负样本)或1(正样本) weight: 可选参数 """ print('AP: ', aper.value().numpy()) print('mAP: ', aper.value().sum().numpy() / 10) # AP: [0.535214 0.6198798 0.59850764 0.527964 0.4984482 0.5188082 0.5916564 0.41430935 0.48577505 0.41956347] # mAP: 0.5210125923156739- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
mAPMeter
mAPMeter计算所有类别的mAP,即平均AP。
import torch from torch.nn import functional as F from torchnet import meter as tnt seed = 1024 torch.manual_seed(seed) # 128条数据, 10个类别 size = (128, 10) output = torch.rand(size=size) # output /= output.sum(dim=1).unsqueeze(dim=1).expand(size=size) output = F.softmax(output, dim=1) target = torch.randint(0, 2, size=size) maper = tnt.mAPMeter() maper.add(output, target) """ add(output, target, weight=None): output: 模型的输出, 是一个NxK的tensor, 表示每个类别的概率, N表示样本数目, K表示类别数目, 所有类别的概率总和应为1 target: 样本的标签, 是一个NxK的二进制tensor, 即其值只能是0(负样本)或1(正样本) weight: 可选参数 """ print('mAP: ', maper.value().numpy()) # mAP: 0.5210126- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
ClassErrorMeter
计算模型的accuracy,即准确率。
import torch from torch.nn import functional as F from torchnet import meter as tnt seed = 1024 torch.manual_seed(seed) # 128条数据, 10个类别 size = (128, 10) output = torch.randn(size=size) output = F.softmax(output, dim=1) target = torch.randint(0, 10, size=(128,)) # 计算acc1和acc5, 默认计算acc1, 即topk=[1] classer = tnt.ClassErrorMeter(topk=[1, 5], accuracy=True) classer.add(output, target) """ add(output, target): output: 模型的输出, 是一个NxK的tensor, 表示每个类别的概率, N表示样本数目, K表示类别数目, 所有类别的概率总和应为1 target: 样本的标签, 是一个长度为N的tensor, 标签id从0开始 """ print('acc1: {0}%, acc5: {1}%'.format(classer.value()[0], classer.value()[1])) # acc1: 11.71875%, acc5: 56.25%- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
ConfusionMeter
ConfusionMeter计算多分类模型的confusion matrix,即混淆矩阵。不支持 multi-label和multi-class问题,对于这类问题可以使用 MultiLabelConfusionMeter:
import torch from torch.nn import functional as F from torchnet import meter as tnt seed = 1024 torch.manual_seed(seed) size = (128, 10) output = torch.randn(size=size) output = F.softmax(output, dim=1) target = torch.randint(0, 10, size=(128,)) # k表示类别的数目, normalized表示是否对混淆矩阵进行归一化, 默认False confer = tnt.ConfusionMeter(k=10, normalized=False) confer.add(output, target) """ add(output, target): output: 模型的输出, 是一个NxK的tensor, 表示每个类别的概率, N表示样本数目, K表示类别数目, 所有类别的概率总和应为1 target: 样本的标签, 是一个长度为N的tensor, 标签id从0开始 """ print('confusion matrix: \n', confer.value()) # confusion matrix: [[1 1 2 1 0 0 0 1 1 0] [0 1 1 4 1 1 1 0 2 2] [0 2 2 1 0 1 0 2 1 2] [1 0 1 0 1 5 0 1 3 0] [3 3 3 1 1 1 3 1 0 3] [1 2 1 2 2 3 3 0 4 1] [1 1 1 0 1 1 0 2 0 2] [1 1 1 1 0 1 2 2 1 2] [2 0 0 0 1 0 1 2 2 3] [1 1 3 1 1 1 0 1 3 3]] # normalized=True # confusion matrix: [[0.14285715 0.14285715 0.2857143 0.14285715 0. 0. 0. 0.14285715 0.14285715 0. ] [0. 0.07692308 0.07692308 0.30769232 0.07692308 0.07692308 0.07692308 0. 0.15384616 0.15384616] [0. 0.18181819 0.18181819 0.09090909 0. 0.09090909 0. 0.18181819 0.09090909 0.18181819] [0.08333334 0. 0.08333334 0. 0.08333334 0.41666666 0. 0.08333334 0.25 0. ] [0.15789473 0.15789473 0.15789473 0.05263158 0.05263158 0.05263158 0.15789473 0.05263158 0. 0.15789473] [0.05263158 0.10526316 0.05263158 0.10526316 0.10526316 0.15789473 0.15789473 0. 0.21052632 0.05263158] [0.11111111 0.11111111 0.11111111 0. 0.11111111 0.11111111 0. 0.22222222 0. 0.22222222] [0.08333334 0.08333334 0.08333334 0.08333334 0. 0.08333334 0.16666667 0.16666667 0.08333334 0.16666667] [0.18181819 0. 0. 0. 0.09090909 0. 0.09090909 0.18181819 0.18181819 0.27272728] [0.06666667 0.06666667 0.2 0.06666667 0.06666667 0.06666667 0. 0.06666667 0.2 0.2 ]]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
Regression/Loss Meters
AverageValueMeter
AverageValueMeter计算均值和标准差
from torchnet import meter as tnt avger = tnt.AverageValueMeter() for i in range(10): avger.add(i) """ add(value): value: 一个数值 """ print('mean: {0}, std: {1}'.format(avger.value()[0], avger.value()[1])) # mean: 4.5, std: 3.0276503540974917- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
AUCMeter
计算AUC,即ROC曲线下的面积,用于二分类。
import torch from torch.nn import functional as F from torchnet import meter as tnt seed = 1024 torch.manual_seed(seed) size = (128, ) output = torch.randn(size=size) output = F.sigmoid(output) target = torch.randint(0, 2, size=size) aucer = tnt.AUCMeter() aucer.add(output, target) """ add(output, target): output: 模型的输出分数, 是一个一维的tensor target: 样本的标签, 也是一个一维的tensor, 其值只能是0(负样本)或1(正样本) """ print('AUC: ', aucer.value()[0]) # AUC: 0.5208791208791209- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
MovingAverageValueMeter
计算当前状态前的windowsize个数的均值和标准差。即计算最后windowsize个数的均值和标准差。
from torchnet import meter as tnt # windowsize 需要计算的个数 mavger = tnt.MovingAverageValueMeter(windowsize=5) for i in range(10): mavger.add(i) """ add(value): value: 一个数值 """ print('mean: {0}, std: {1}'.format(mavger.value()[0].item(), mavger.value()[1])) # mean: 7.0, std: 1.5811388300841898- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
MSEMeter
计算模型的MSE,即均方误差。
from torchnet import meter as tnt seed = 1024 torch.manual_seed(seed) size = (128, 10) output = torch.randint(0, 10, size=size) target = torch.randint(0, 10, size=size) mser = tnt.MSEMeter(root=False) mser.add(output, target) """ add(output, target): output: 模型的输出类别, 是一个NxK的tensor target: 样本的标签, 也是一个NxK的tensor """ print('MSE: ', mser.value().item()) # MSE: 17.3515625- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Miscellaneous Meters
TimeMeter
用来计算模型处理数据的时间。
from torchnet import meter as tnt def my_model(): tmp = 1 for i in range(10000000): tmp *= 1024 * 10.24 * (i+1) # unit=False, 统计总的消耗时间 # unit=True, 统计平均消耗时间 timer = tnt.TimeMeter(unit=False) for epoch in range(10): my_model() # timer.value() print('all time: ', timer.value()) # all time: 8.787968158721924- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
总结
慢慢的将这个库都会使用,以及会自己总结经验都行啦的额样子与打算。

- 代码复用和模块化编程的框架都搞清楚。
-
相关阅读:
RK3568笔记五:基于Yolov5的训练及部署
Codeforces Round #833 (Div. 2)A — C
Linux history 命令相关使用以及配置
数据结构与算法之图的应用
nmp ERR! code ERR SOCKET TIMEOUT nmp ERR!network npmSocket timeout(已解决)
SSM网上在线校园商城平台网站
FlinkModule加载HiveModule异常
Oracle/PLSQL: To_Clob Function
Python算法——树的镜像
GEE Python 客户端库中推出了两个新方法:getPixels 和computePixels 用于解决超限和下载的超时的问题
- 原文地址:https://blog.csdn.net/kuxingseng123/article/details/128195248
