-
MOOC 大数据Note
Spark
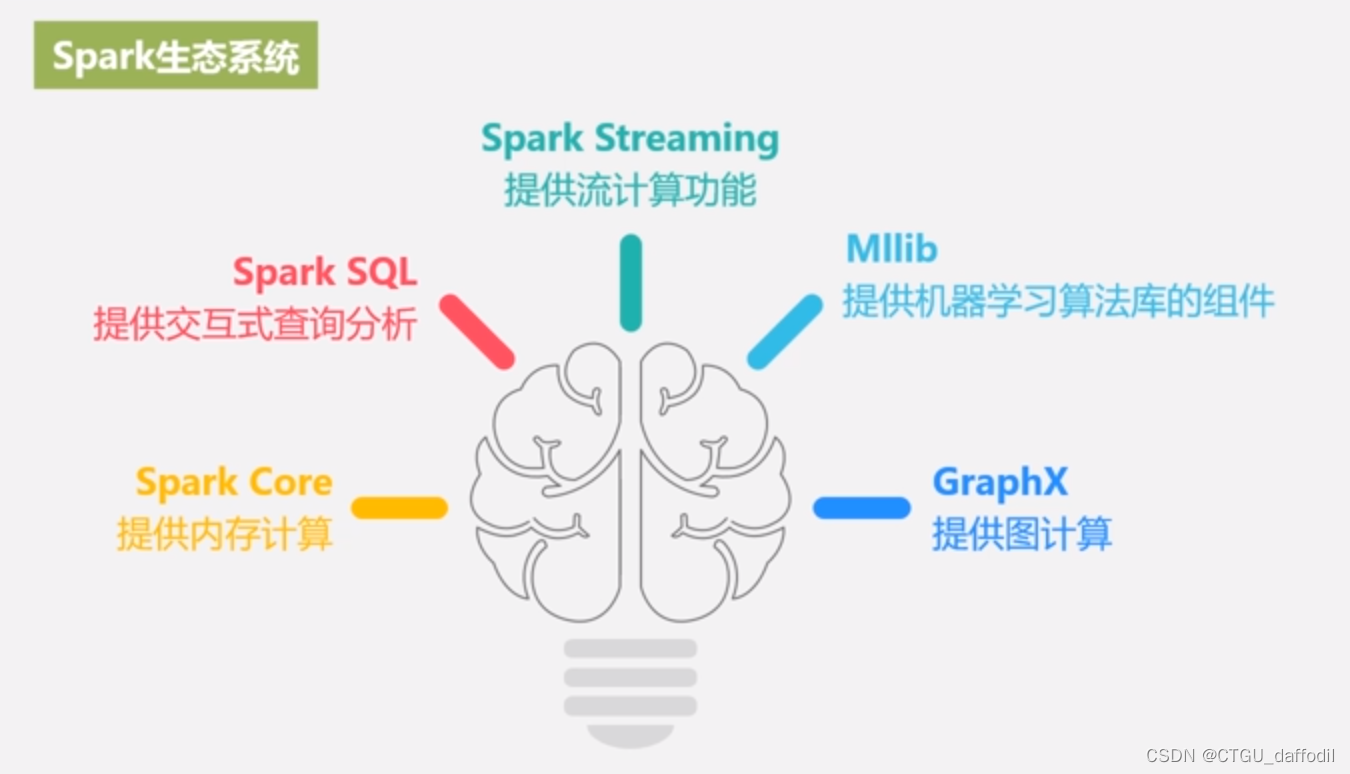
Spark 一个软件栈满足不同交互场景
Lineage 血缘关系
创建 转换 动作
ShuffleMapStage
Spark的部署和应用方式


RDD操作分为转换(Transformation)和动作(Action)两种类型,下列属于动作(Action)类型的操作的是:count
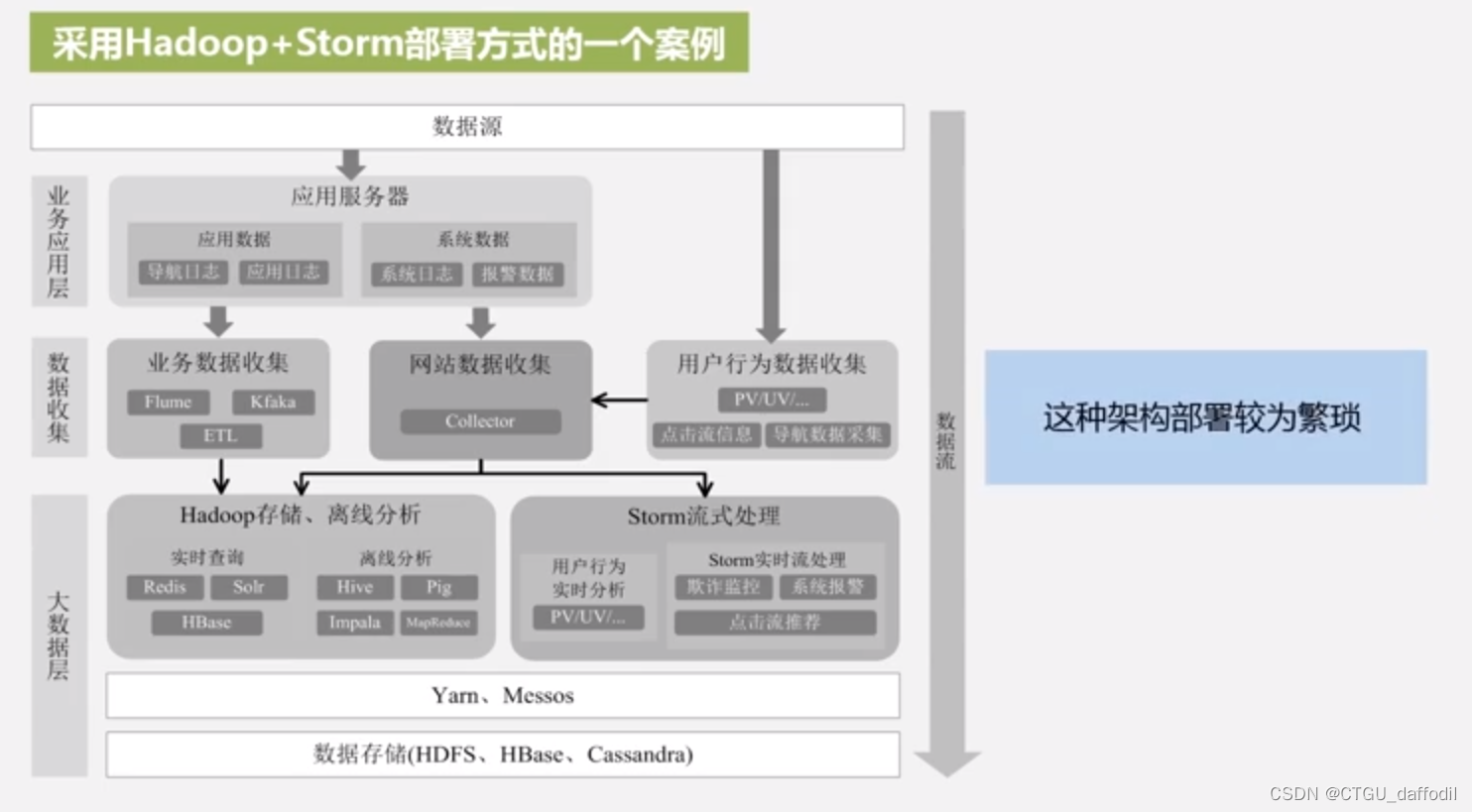
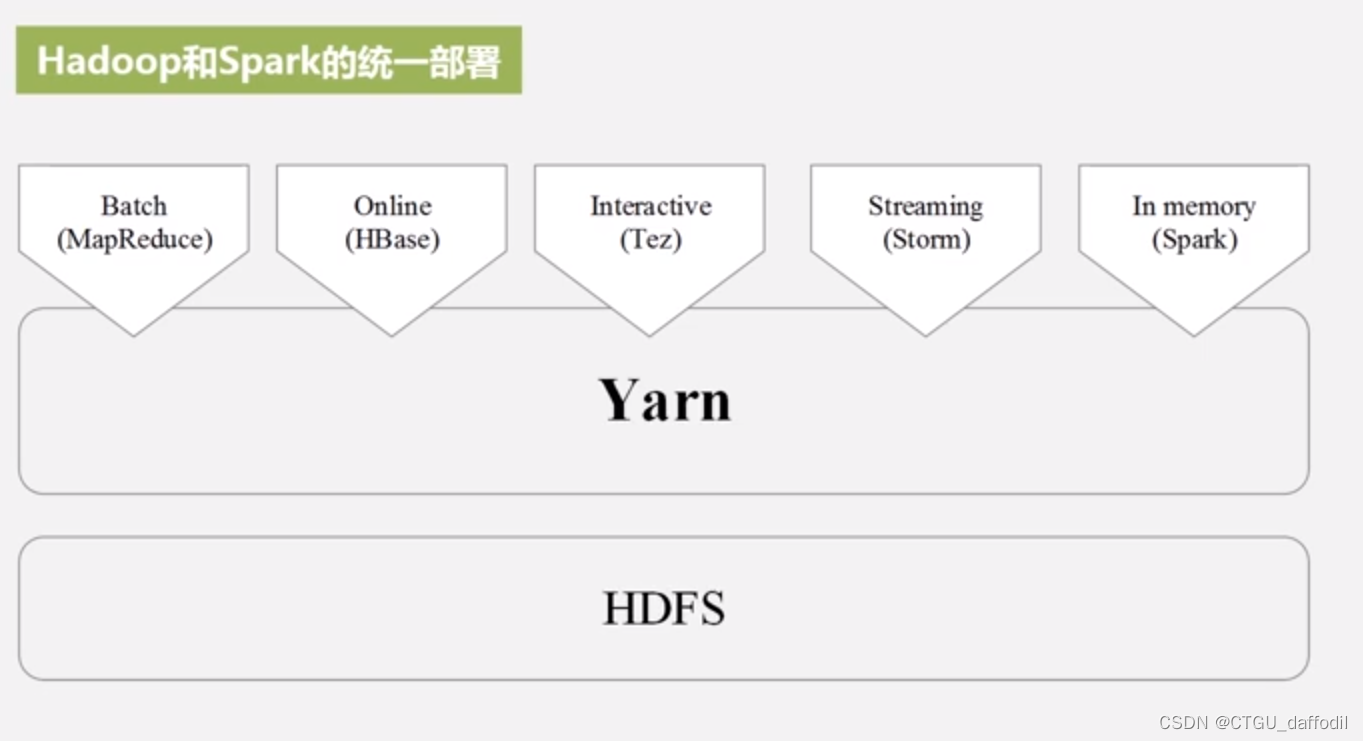
Spark支持三种类型的部署方式:Standalone,Spark on Mesos,Spark on YARN
RDD采用惰性调用,遇到“转换(Transformation)”类型的操作时,只会记录RDD生成的轨迹,只有遇到“动作(Action)”类型的操作时才会触发真正的计算
在选择Spark Streaming和Storm时,对实时性要求高(比如要求毫秒级响应)的企业更倾向于选择流计算框架Storm
基于实时数据流的数据处理:Storm
复杂的批量数据处理:MapReduce
基于历史数据的交互式查询:Impala
Apache软件基金会最重要的三大分布式计算系统开源项目包括:Storm、Spark、Hadoop
Spark的主要特点包括:运行模式多样、通用性好、容易使用、运行速度快
Scala是Spark的主要编程语言,但Spark还支持Java、Python、R作为编程语言
Scala具备强大的并发性,支持函数式编程
Scala是一种多范式编程语言
Scala运行于Java平台,兼容现有的Java程序
Spark的运行架构包括:每个应用的任务控制节点 Driver、集群资源管理器 Cluster Manager、运行作业任务的工作节点 Worker Node、每个工作节点上负责具体任务的执行进程 Executor
常见的动作(Action)和转换(Transformation)操作的API count():返回数据集中的元素个数,map(func):将每个元素传递到函数func中,并将结果返回为一个新的数据集,filter(func):筛选出满足函数func的元素,并返回一个新的数据集
HBase是一种列式数据库
HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳
每个HBase表都由若干行组成,每个行由行键(row key)来标识
HBase列族支持动态扩展,可以很轻松地添加一个列族或列
Zookeeper是一个集群管理工具,常用于分布式计算,提供配置维护、域名服务、分布式同步等
HBase三层结构的顺序是:Zookeeper文件,-ROOT-表,.MEATA.表
客户端是通过三级寻址来定位Region
访问HBase表中的行,有哪些方式:通过一个行健的区间来访问,通过单个行键来访问、全表扫描
HBase和传统关系型数据库的区别在于哪些方面:数据操作、数据模型、存储模式、数据索引
下列对HBase的理解正确的是:HBase多用于存储非结构化和半结构化的松散数据,HBase是针对谷歌BigTable的开源实现
-
相关阅读:
群辉 Synology NAS Docker 安装 RustDesk-server 自建服务器只要一个容器
高项 01 信息化与信息系统
Linux简介
c++习题02-浮点数求余
CPP-Templates-2nd--第十九章 萃取的实现 19.7---
【学习笔记】Windows GDI绘图(九)Graphics详解(上)
Camtasia Studio 2024软件最新版下载【安装详细图文教程】
计算机网络期末知识点(第六章)
idea Java代码格式化规范
矩阵分析与应用-4.7-QR分解及其应用-Section2
-
原文地址:https://blog.csdn.net/zhanghanqmx/article/details/128171841