-
机器学习 分类、回归、聚类、特征工程区别
一、分类和回归的区别
简单理解分类和回归的区别在于输出变量的类型不同。
- 定量输出称为回归,或者说是连续变量预测;
- 定性输出称为分类,或者说是离散变量预测。
举个例子:
预测明天的气温是多少度,这是一个回归任务;
预测明天是阴、晴还是雨,就是一个分类任务。二、回归和聚类的区别
二者解决的具体问题不一样**分类算法的基本功能是做预测。**我们已知某个实体的具体特征,然后想判断这个实体具体属于哪一类,或者根据一些已知条件来估计感兴趣的参数。比如:我们已知某个人存款金额是10000元,这个人没有结婚,并且有一辆车,没有固定住房,然后我们估计判断这个人是否会涉嫌信用欺诈问题。这就是最典型的分类问题,预测的结果为离散值,当预测结果为连续值时,分类算法可以退化为计量经济学中常见的回归模型。分类算法的根本目标是发现新的模式、新的知识,与数据挖掘数据分析的根本目标是一致的。
**聚类算法的功能是降维。**假如待分析的对象很多,我们需要归归类,划划简,从而提高数据分析的效率,这就用到了聚类的算法。很多智能的搜索引擎,会将返回的结果,根据文本的相似程度进行聚类,相似的结果聚在一起,用户就很容易找到他们需要的内容。聚类方法只能起到降低被分析问题的复杂程度的作用,即降维,一百个对象的分析问题可以转化为十个对象类的分析问题。聚类的目标不是发现知识,而是化简问题,聚类算法并不直接解决数据分析的问题,而最多算是数据预处理的过程。
三、什么是特征工程?
将原始数据转换为数据集的任务称为特征工程。
我们没办法将原始数据直接调用模型进行fit
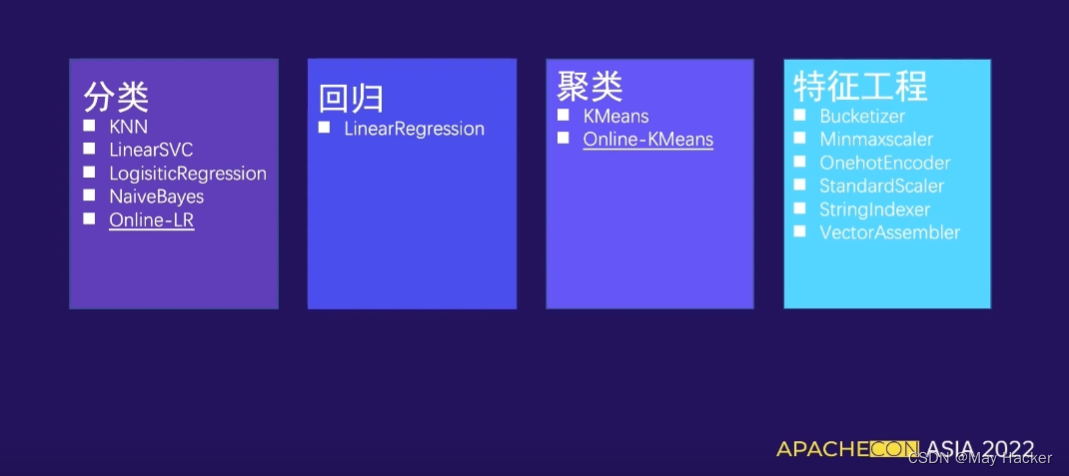
flink ML 提供的:
-
相关阅读:
_Linux进程控制
使用C语言实现散列表中的冲突处理方法
SHAP解释模型(二)
本地数仓网络设备迁移实录
scala解析命令行参数详解
Java基础简单整理
Linux文件系统
报错处理:Nginx端口被占用
在Linux操作系统中,修改文件目录权限常用的命令操作
R 语言 基于关联规则与聚类分析的消费行为统计
- 原文地址:https://blog.csdn.net/weixin_43889841/article/details/128167666